

java实现四则运算应用(基于控制台)
项目地址:https://gitee.com/wxrqforever/object_oriented_exp1.git
一、需求分析:
一个基于控制台的四则运算系统,要能实现生成并计算含有真,假分数,整数的不超过三个运算符带有括号的四则运算表达式,并且要能根据用户所提交的答案生成答题报告,答题报告中主要包括,本次答题的正确,错误,和重复表达式出现的情况。生成的表达式和答案要存入文件中。对生成的表达式有如下要求,不能在过程中产生负数,因为小学生并不会计算负数,以及不能出现除0的情况,因为小学生不会计算除以0。
从整个需求来看,大致可以分为三个模块,生成表达式,表达式计算(包括将表达式和答案写入文件),答题报告的生成(包括表达式的查重和根据输入完成的校验)。各个模块之间关系密切,故采用由下至上的不断迭代的开发模式,先开发最底层的各个桩模块,在开发每个桩模块时再采用测试驱动开发的方法,从编写小的测试用例开始开发桩模块,当对桩模块进行整合时,再编写测试模块,这样当开发完成后测试也就完成了。
生成表达式模块:主要的关键点在于如何能够全覆盖所有不超过三个运算符含有真,假分数,整数的可以带有括号的四则运算表达式。在忽略优先级的条件下,我们观察表达式形如(1+2+3)*6,1+2+3, 1+2,的三个表达式,我们会发现任何一个复杂的表达式均可看作,其少一个运算符的表达式和一个运算符以及一个运算数构成,如上的例子中
(1+2+3)*6 可以看作是由(1+2+3)和*以及6构成,而1+2+3 则可以看做是由1+2 和+以及3构成。这就给了一个思路只要编写一个能随机生成所有情况下的带一个运算符的表达式,就可以通过不断添加运算符和运算操作数的方式而穷尽所有的可能。
表达式计算:可采用将随机生成的表达式转换为后缀,在对后缀表达式进行计算完成。
答题报告的生成:关键点在于如何实现查重,首先我们要明白何为重复的表达式?根据题目中的定义“程序一次运行生成的题目不能重复,即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目。例如,23 + 45 = 和45 + 23 = 是重复的题目,6 × 8 = 和8 × 6 = 也是重复的题目。3+(2+1)和1+2+3这两个题目是重复的,由于+是左优先计算的,1+2+3等价于(1+2)+3,也就是3+(1+2),也就是3+(2+1)。但是1+2+3和3+2+1是不重复的两道题,因为1+2+3等价于(1+2)+3,而3+2+1等价于(3+2)+1,它们之间不能通过有限次交换变成同一个题目。" 仔细观察题目中所给的两个例子,你会发现这里所说的重复的意思就是你不能破坏原本计算时的优先级,在这个基础上你可以交换加法或者乘法的。解析一下题中的例子,比如3+(2+1)和1+2+3这两个题目,为什么是重复的呢?按照优先级,我们是如何计算左边题目的,是先计算2+1的这个加法再计算3加上2+1的结果的这个加法的对吧,而右边这个题目根据加法的左结合,先计算1+2 的这个加法 再计算3加上1+2 这个结果的加法,运算时的符号的优先级并没有被改变仅仅改变了加法的左右操作数,满足重复的定义,所以是重复的。
再看一个不重复的例子,1+2+3和3+2+1,同样的左边的题目,先计算的是1+2的这个加法再计算3加上1+2的结果的这个加法,而右边的则是先计算3+2的这个加法再计算1加上3+2的结果的加法.可以理解为在进行运算时整个运算的流程是不同的,所以是不同的表达式.
通过上述的分析我们可以看到如何判定两个表达式是否重复关键在于如果在计算这两个表达式时的流程完全一致或者仅在加法或者乘法运算时交换了左右操作数则这样的两个运算表达式是重复的,这样的分析很容易让我们相到用后缀表达式解决查重,但仅仅依靠后缀表达式是不够的,后缀表达式是能够体现计算过程但却无法用于判断两个表达式之间计算过程是否相同的直接体现,这是·两个重复的表达式很可能会有不同后缀表达式。比如以(1+2)*3+5和3*(1+2) +5 为例,(1+2)*3+5的后缀表达式为1 2 + 3 * 5 + 而3*(1+2) +5的后缀表达式为3 1 2 + * 5+,虽然是相同运算过程的体现但表达式之间的差距却非常的大,那该如何解决?
所谓相同的运算过程就是,你在做什么运算我也做什么运算,你的操作数是啥我的操作数也是啥,出于这个引入一个新的表达式,我将其命名为查重表达式,他的结构是运算在先后面跟着这个运算符的操作数,以上述为例(1+2)*3+5的查重表达式就为: +12 * 3 +5 这个表达式的含义就是第一个运算的是加法,加法的操作数是2 和3 第二个运算是乘法,乘法的操作数是前一步计算的结果和3以此类推,而3*(1+2) +5的查重表达式为:+12 * 3+5 与上述完全一致!这样在做查重是只需判断查重表达式是否一致或者在查重表达式中第一个字符为‘+’ 或者‘*’的情况下后续的两个操作数互换位置后是否一致即可。也就是说上述的查重表达式于+21 * 3+5 也是等价的。
那该如何生成查重表达式,所谓的查重表达式就是描述表达式正在运算的过程,那就在你使用后缀表达式计算时,去生成即可。算法之后给出
二、功能设计:
功能设计如图:
com.wx.appEntrance是作为项目的入口。
com.wx.test 是作为测试功能使用
com.wx.randomTool是作为生成随机的四则运算表达式的,共有四个类组成其中RandExpressionExport(可直接生成表达式)是顶层类,是对RandOperatorNumberExport(可随机生成各类操作数和操作符)进一步封装,而RandOperatorNumberExport是对RandomExportMachine(可生成数字和字符)的进一步封装,Ruler则是描述生成表达式的功能.
com.wx.expression是描述表达式的结构
com.wx.calculateTool是用于计算表达式,PostfixExpression用于生成后缀表达式,CalculateRuler描述计算规则,CalculateExpression顶层类对可直接计算表达式,对前面两个类的封装。
com.wx.fileIO用于实现文件操作
com.wx.expressionCnki 用于实现表达式的查重,工具类.
com.wx.report 用于生成答题报告.
三、代码实现
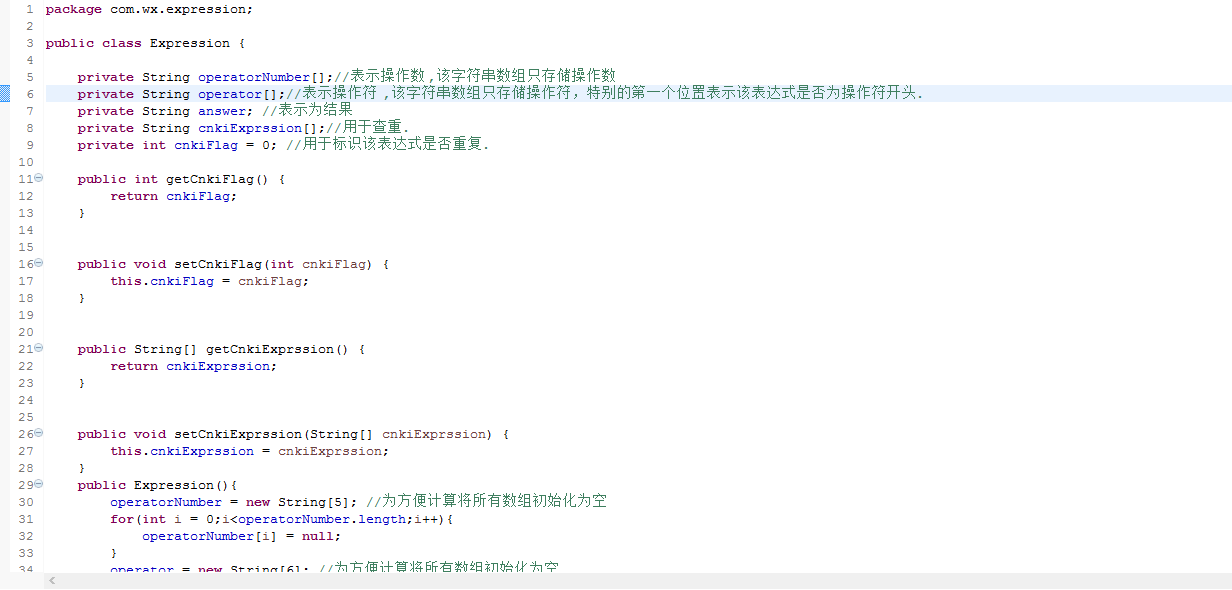
3.1表达式类主要用于存储表达式的代码,如下:



3.2.1 用于随机产生一个表达式的顶层类RandExpressionExport中的产生随机表达式getExpression方法代码如下:


3.2.2 用于随机产生一个表达式的顶层类RandExpressionExport中的随即产生一个操作符表达式的getOneOperatorExpression方法的代码如下:
(其余多操作符的情况均是对该方法的进一步封装)

3.2.3用于随机产生一个表达式的顶层类RandExpressionExport中的随即产生带有两个操作符的表达式的getTwoOperatorExpression方法的代码如下:

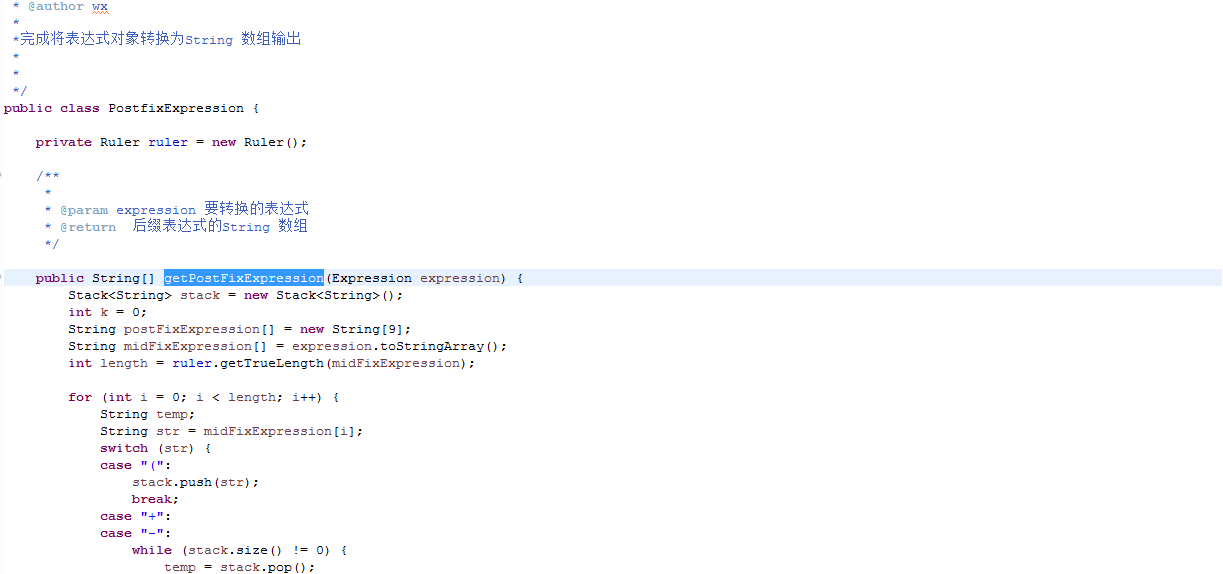
3.3.1用于将表达式转换成后缀表达式的PostfixExpression类中的getPostFixExpression代码如下:


3.3.2用于计算后缀表达式的CalculateExpression类中的calculatePostFixExpression方法代码如下:

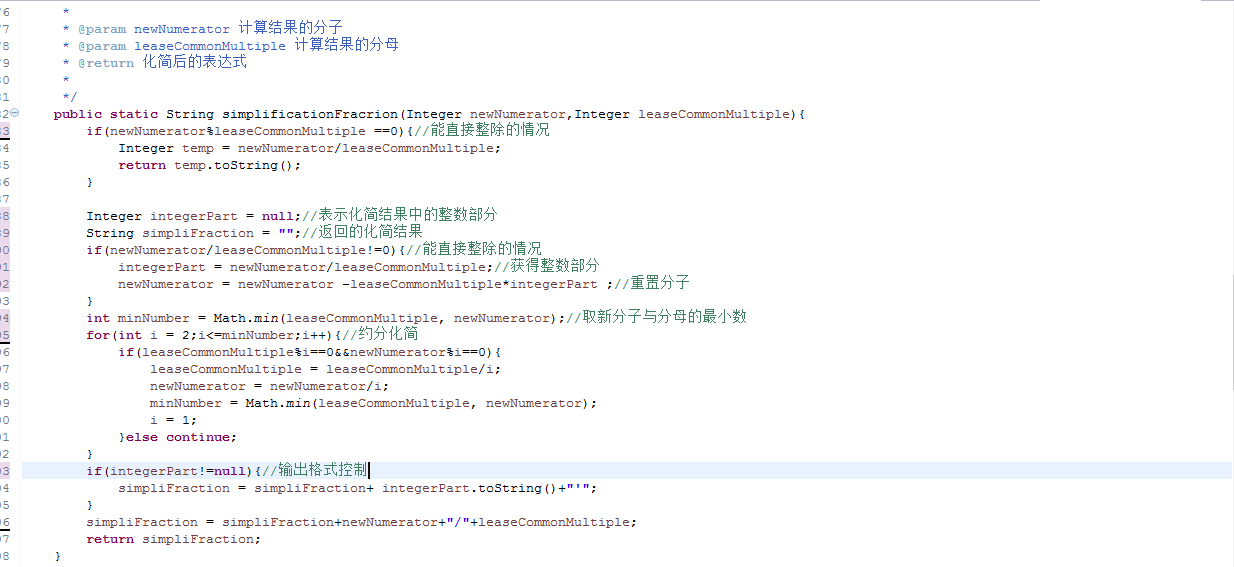
3.3.3用于描述计算规则的CalculateRuler中的用于化简表达式的方法simplificationFracrion的代码如下:
4.1用于实现查重的Cnki类中的得到查重表达式的getCnkiExpressionArray方法的代码如下:

4.2用于实现查重的Cnki类中的判断两个表达式是否重复的代码如下:

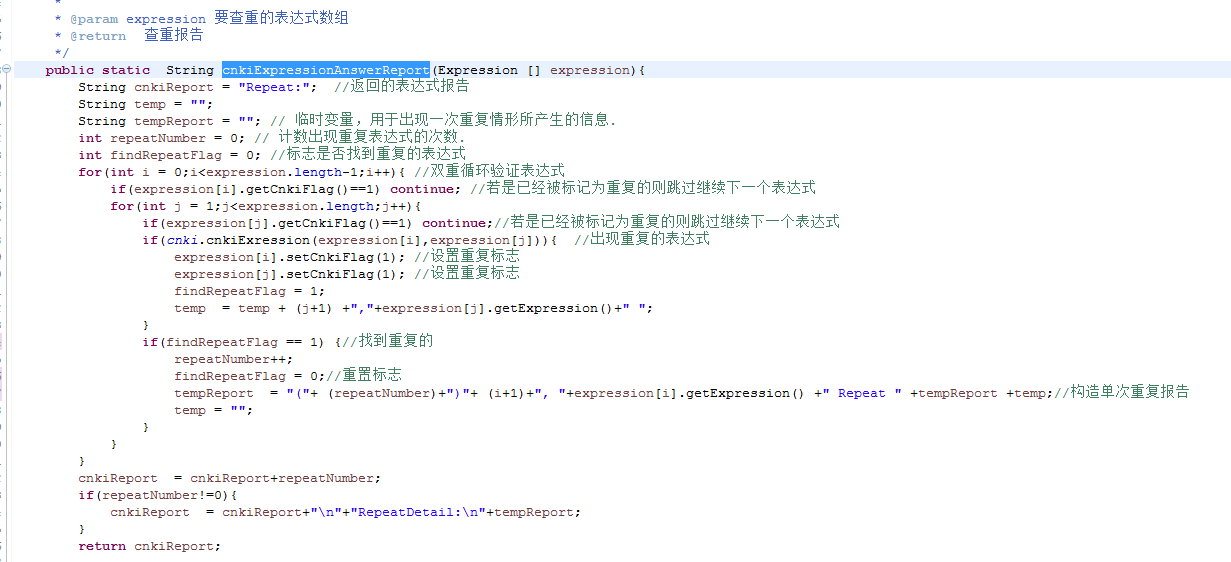
4.3用于生成报告的AnswerResport中生成答题报告getAnswerResport方法的代码: 4.4用于生成报告的AnswerResport中生成查重报告cnkiExpressionAnswerReport方法的代码:
4.4用于生成报告的AnswerResport中生成查重报告cnkiExpressionAnswerReport方法的代码:
四、测试运行:
测试截图如下:
输入题目数为10 生成的数字范围为10
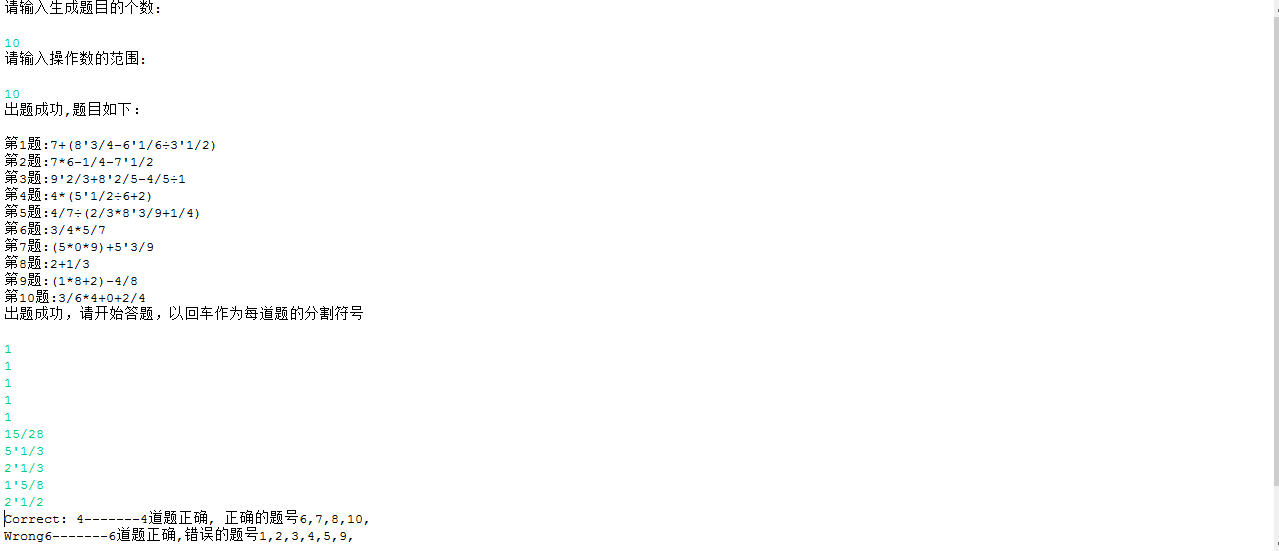

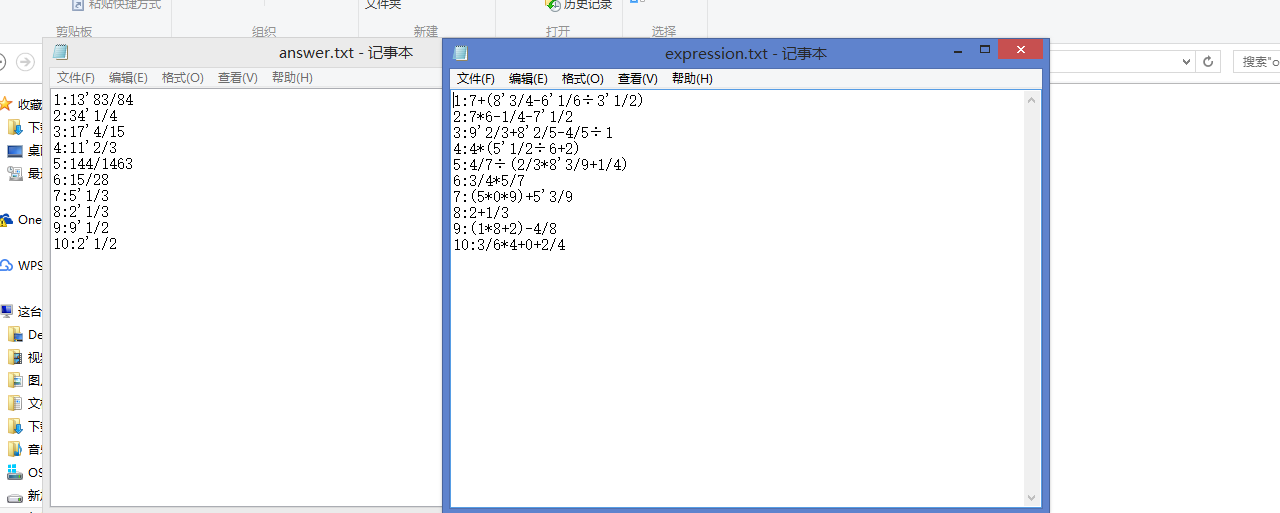
文件中的截图如下:

对于查重进行单独测试:
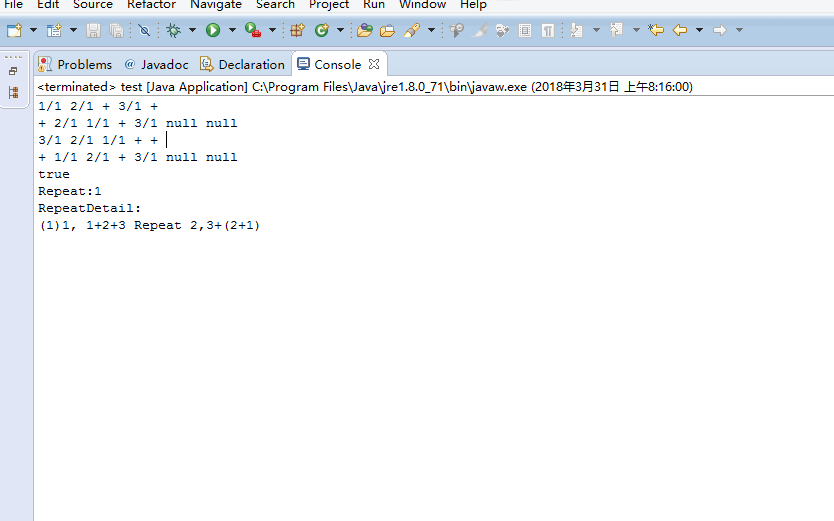
当输入的表达式为1+2+3 与3+(2+1)时,截图如下:其中第一,二行为1+2+3的后缀表达式和查重表达式,第三,四行为3+(2+1)的后缀表达式和查重表达式。
第五行为查重结果,余下的为查重报告。
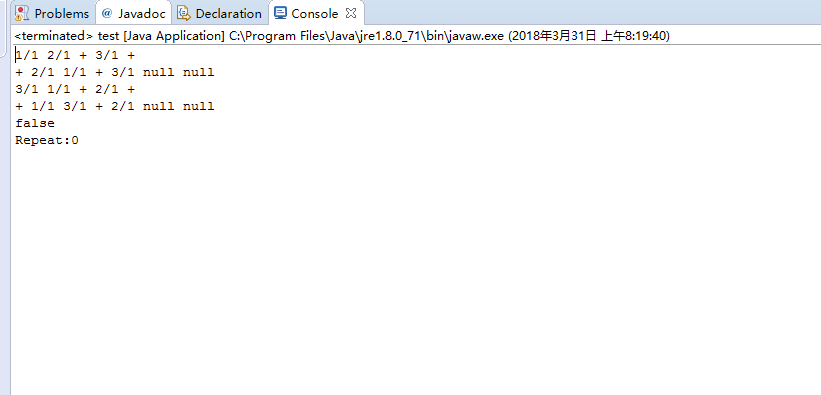
当输入的表达式为1+2+3 与3+1+2时,截图如下:其中第一,二行为1+2+3的后缀表达式和查重表达式,第三,四行为3+1+2的后缀表达式和查重表达式。
第五行为查重结果,余下的为查重报告。
当输入的表达式为(1+2)*3+5 与3*(1+2) +5 时,截图如下:其中第一,二行为(1+2)*3+5的后缀表达式和查重表达式,第三,四行为3*(1+2) +5 的后缀表达式和查重表达式。
第五行为查重结果,余下的为查重报告

五、psd个人过程:


