
认识HDFS分布式文件系统
1.设计基础目标
(1) 错误是常态,需要使用数据冗余
(2)流式数据访问。数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理。
(3)文件采用一次性写多次读的模型,文件一旦写入就无法修改。所以一致性模型非常简单。
(4)程序采用 数据就近 原则分配节点执行。(MapReduce)
2.hdf体系结构
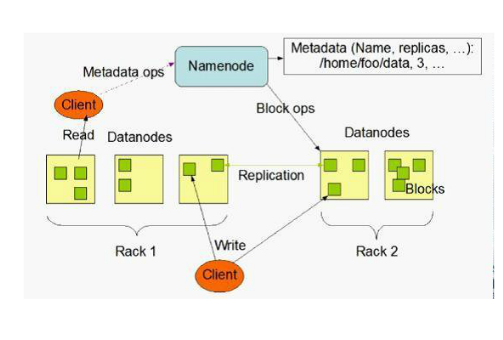
hadfs设计十分简单,在我的1个master和两个slave节点的集群中,通过jps,可以查看在master节点上运行着SecondaryNameNode ,NameNode,JobTracker
在slave结点上运行着DataNode和TaskTracker进程
1.NameNode:管理文件系统的命名空间,记录每个文件数据快在各个DataNode上的位置和副本信息,记录命名空间内的改动或空间本身属性的改动;协调客户端对文件的访问;
NameNode使 用事物日志记录HDFS元数据的变化,使用映像文件存储文件系统的命名空间,
2.DataNode:管理存储节点,一次写入,多次读取,不支持修改。文件由数据块组成,包括文件映射,文件属性。默认的数据块大小为64MB,数据块尽量散布在各个节点中,负载均衡。
3.读取数据流程:客户端要访问HDFS中的文件,首先从NameNode获取组成这个文件的数据块位置列表,根据数据块位置列表,知道存储数据块的DataNode,访问DataNode获取数据,NameNode并不参与数据实际传输。
3.HDFS分布式文件系统的可靠性
- 副本冗余:在hdfs-site.xml中可以设置副本的数量,DataNode启动时,首先会遍历本地的文件系统,产生一份hdfs数据块和本地文件的对应关系列表(blockreport)汇报给namenode。
- 机架策略:通过“机架感知”,将数据块副本存储在不同的机架中。
- 心跳机制:NameNode周期性的从datanode接受心跳信号和块报告。根据块报告验证元数据,副本数量、磁盘错误、节点宕机。
- 安全模式:NameNode启动时会经过“安全模式”阶段,安全模式不会产生数据写。可以通过命令强制集群进入安全模式。
- 校验和:文件创立的时候,每个文件都会产生校验和,校验和会作为一个隐藏文件保存在命名空间下,客户端获取数据时可以检查校验和是否相同,从而法相数据块是否损坏。
- 回收站:HDFS提供回收站功能。
- 元数据保护:映像文件和事物日志是Namenode的核心数据。可以配置为拥有多个副本,副本会降低Name的处理速度,但是增加安全性。
- 快照
4.HDFS文件操作(命令行操作和API调用的方式)
列出文件:hadoop dfs -ls 后可接上目录
文件上传:hadoop dfs -put 本地文件 hdfs目录
文件复制到本地:hadoop dfs -get
文件删除:hadoop dfs -rmr 目录或文件名
文件查看:hadoop dfs -cat 文件名
查看HDFS的基本统计信息:hadoop dfsasmin -report
进入/退出安全模式:hadoop dfsadmin -safemode enter/leave
5.增加节点
- 在新节点安装好hadoop
- 把namenode的有关配置文件复制到该节点
- 修改masters和slaves文件,增加该节点
- 设施ssh免密码进入该结点
- 单独启动该节点上的datanode和tasktracker(hadoop-daemon.sh start datanode/tasktracker)
- 运行start-balancer.sh进行负载均衡。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 深入理解 Mybatis 分库分表执行原理
· 如何打造一个高并发系统?
· .NET Core GC压缩(compact_phase)底层原理浅谈
· 现代计算机视觉入门之:什么是图片特征编码
· .NET 9 new features-C#13新的锁类型和语义
· 手把手教你在本地部署DeepSeek R1,搭建web-ui ,建议收藏!
· Spring AI + Ollama 实现 deepseek-r1 的API服务和调用
· 《HelloGitHub》第 106 期
· 数据库服务器 SQL Server 版本升级公告
· C#/.NET/.NET Core技术前沿周刊 | 第 23 期(2025年1.20-1.26)