

一个http请求完整过程的个人理解
随着接触web开发的时间增长,自己也对http请求有了自己的见解,但都是自己理解,不一定十分正确,在此记录下来,方便以后更加深入学习后,用来对比与现在理解上的差异。
我们都知道,在服务器中需要定义url与视图函数的映射关系,那什么是映射关系呢?
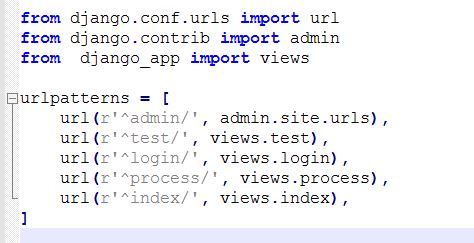
假设现在定义了下图的url与视图函数的映射关系,现在我在浏览器中输入url=http://127.0.0.1/index/,这时候浏览器就会向服务器发送一个请求--->>服务器接收到请求---->>解析请求头----->发现请求url是index/---->>查询url-视图函数映射表,如果发现了url,则调用对应的视图函数(此处是views.index)处理这个请求,并将处理完的结果返回浏览器,如果没有发现对应的url,则返回404,表示没有找到相应的资源。
 这个过程就好比是,你现在是一个顾客(浏览器),得知某个商店(视图函数)有你需要的商品(请求的资源),那么在你得知商店地址(url),你就会过去商店(发起请求),向商店说出你要的商品,然后商店找出商品(处理请求),然后卖给你(响应请求)。但是,商店觉得卖的商品太单一了,除了原来的日用品(get),现在还增加首饰(post),电子设备(put)等各种商品(http中的其他请求方式,例如delete等)。这时候你再到店买商品(请求来到视图函数),就要告诉商店,我要买xxx日用品(请求头中是get请求方式),这时候商店中负责日用品的店员就会为你找到xxx日用品,并卖给你。然后过了一段时间,又想去同一家店买东西了,还是按照原来的地址(url)去到商店(视图函数),这时候发现商店居然搬走了,这时候地址与商店的映射关系就消失了,没有商店处理你要买商品的请求了,这时候就相当于404状态码了,如果店家在门口贴着新地址,那么你就可以去新地址找到商店,这就相当于302状态码了。
这个过程就好比是,你现在是一个顾客(浏览器),得知某个商店(视图函数)有你需要的商品(请求的资源),那么在你得知商店地址(url),你就会过去商店(发起请求),向商店说出你要的商品,然后商店找出商品(处理请求),然后卖给你(响应请求)。但是,商店觉得卖的商品太单一了,除了原来的日用品(get),现在还增加首饰(post),电子设备(put)等各种商品(http中的其他请求方式,例如delete等)。这时候你再到店买商品(请求来到视图函数),就要告诉商店,我要买xxx日用品(请求头中是get请求方式),这时候商店中负责日用品的店员就会为你找到xxx日用品,并卖给你。然后过了一段时间,又想去同一家店买东西了,还是按照原来的地址(url)去到商店(视图函数),这时候发现商店居然搬走了,这时候地址与商店的映射关系就消失了,没有商店处理你要买商品的请求了,这时候就相当于404状态码了,如果店家在门口贴着新地址,那么你就可以去新地址找到商店,这就相当于302状态码了。
