

Jmeter脚本增强之参数化(多方式实现)(6)
参数化的场景:
①在插入记录时,数据库对某些字段唯一限制,这时需要参数化(不能传固定参数)
②在压测过程中,比如登录操作,需要使用不同的用户登录,模拟真实的使用场景(避免数据库查询缓存),模拟500并发,需要500个不同的用户账号
这种方式通常被称为数据驱动测试(Data Driven Test),参数的取值范围被称为数据池(Data Pool)。
支持如下多种参数化方式:
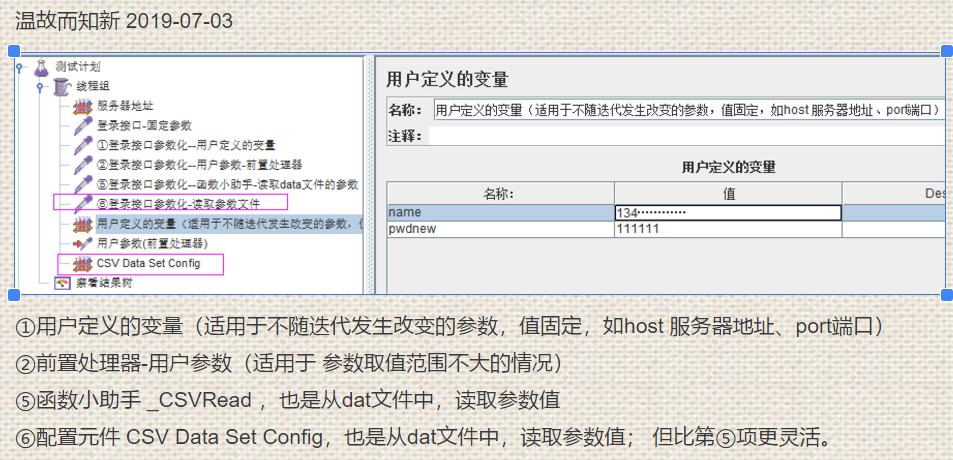
①User Defined Variables:用户定义的变量(设置不需要随迭代发生改变的参数,例如:被测应用的host和port值)
②User Variables:用户参数
③随机变量(待补充)
④正则表达式提取器(待补充)
⑤函数助手:_CSVRead
⑥读取参数文件:CSV数据控件 (强烈推荐)
⑦读取数据库(待补充)
======================
下面截图是说测试中使用最多的方式:读取参数文件 CSV数据控件
======================
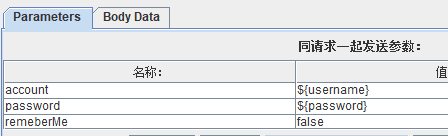
参数化前,参数值传入具体的值:
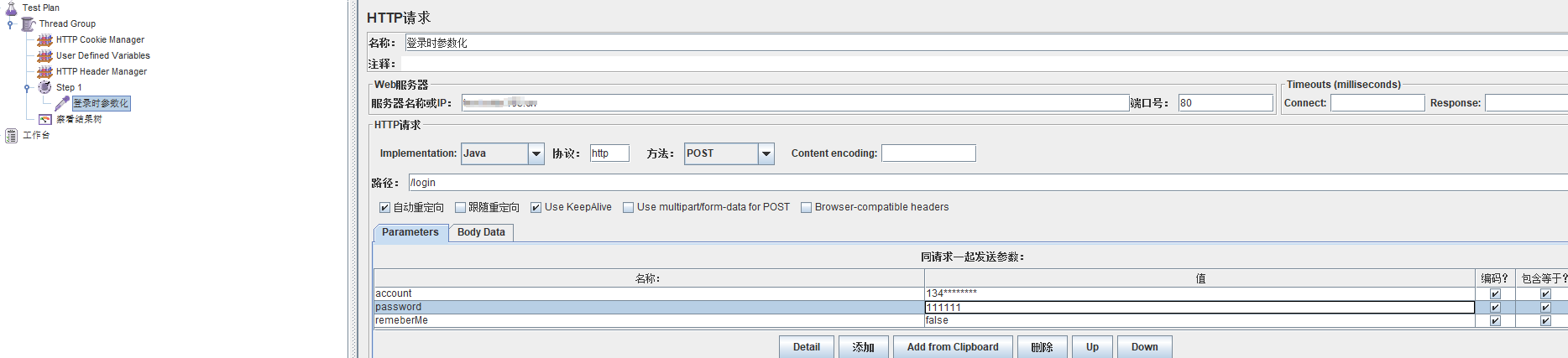
下面说一说各类参数化的方法:
=====================================================================
①用户定义变量 User Defined Variables
点击线程组添加配置元件→ User Defined Variables(用户定义的变量):
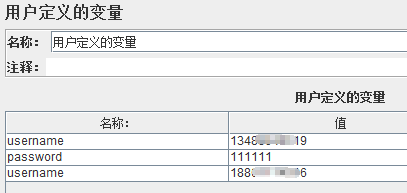
设置虚拟用户数:3个
运行后查看传入的参数username,始终用的134……这个手机号,ok。
PS:User Defined Variables中定义的参数值在test plan执行过程中不能发生取值的改变,因此一般仅将test plan中不需要随迭代发生改变的参数(只取一次的参数),例如:被测应用的host和port值。
==================================
②用户参数(前置处理器的一项)
点击线程组添加前置处理器→ 用户参数:
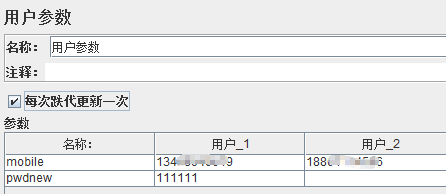
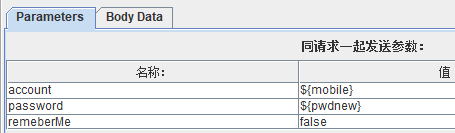 设置了3个虚拟用户:
设置了3个虚拟用户:
第一次迭代:
POST data:
account=13488940619&password=111111&remeberMe=false
第二次迭代:
POST data:
account=18801114596&password=&remeberMe=false (注意这里取的用户2中的pwd哦,所以为空,不能取用户1的pwd)
第三次迭代:
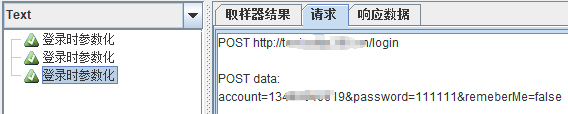
======================
⑤用函数小助手,进行参数化:
先准备dat文件
将用户名密码写入txt文档,保存为.dat格式,编码类型选择UTF-8;(注意:用户名密码一一对应,之间用半角英文逗号隔开)
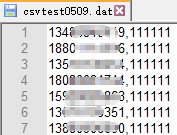
然后将保存的.dat文件放入计算机的某个盘里,这里我放入路径为:F:\jmeter\csvtest0509.dat
点击jmeter的界面,功能栏选项→ 函数助手对话框→ _CSVRead
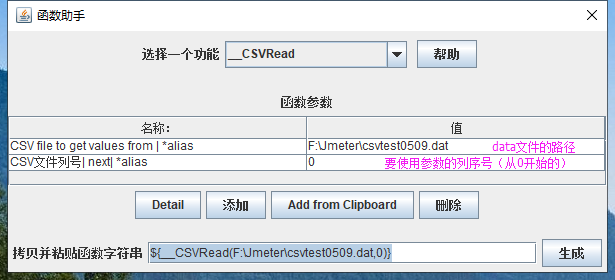
点击‘生成’按钮,即生成对应的参数,然后在接口中使用:

替换参数化后的参数,然后修改线程数,执行脚本,通过监听器里结果树的请求内容,可以看到请求的参数都是参数化后的数据
小结
当设置的虚拟用户数(n+5)>data文件的行数n时:
前n个请求依次取data的每行参数,后5个请求时,再次从data文件第一行开始读取5行参数。
====================================================================
⑥读取参数文件 CSV Data Set Config
也是先准备dat文件
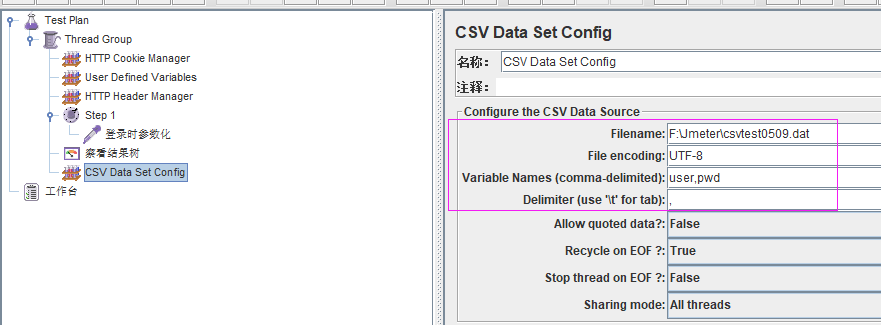
点击线程组添加配置元件→ CSV Data Set Config:

填写参数:
参数说明:
Filename:F:\jmeter\csvtest.dat文件名,保存参数化数据的文件目录,可选择相对或者绝对路径(建议填写相对路径,避免脚本迁移时需要修改路径);
File encoding:UTF-8,F:\jmeter\csvtest.dat文件的编码格式,在保存时保存编码格式为UTF-8即可;
Variable Names(comma-delimited):对对应参数文件每列的变量名,类似excel文件的文件头,起到标示作用,同时也是后续引用的标识符,建议采用有意义的英文标示;
(如:有几列参数,在这里面就写几个参数名称,每个名称中间用分隔符分割,这里的 user,pwd,可以当变量来引用:{user},{pwd};
Delimitet:参数文件分隔符,用来在“Variable Names”中分隔参数,与参数文件中的分隔符保持一致即可;
Allow quote data:是否允许引用数据,默认false,选项选为“true”的时候对全角字符的处理出现乱码 ;
Recycle on EOF?:是否循环读取参数文件内容;因为CSV Data Set Config一次读入一行,分割后存入若干变量中交给一个线程,如果线程数超过文本的记录行数,那么可以选择从头再次读入;
△ Ture:为true时,当已读取完参数文件内的测试用例数据,还需继续获取用例数据时,此时会循环读取参数文件数据(即:读取文件到结尾时,再重头读取文件);
△False:为false时,若已至文件末尾,则不再继续读取测试数据;通常在“线程组线程数* 线程组循环次数>参数文件行数”时,选用false(即:读取文件到结尾时,停止读取文件);
Stop thread on EOF?:当Recycle on EOF为False时(读取文件到结尾),停止进程,当Recycle on EOF为True时,此项无意义;
△若为ture,则在读取到参数文件行末尾时,终止参数文件读取线程;
△若为false,此时线程继续读取,但会请求错误,因此时读取的数据为EOF;
Sharing mode:共享模式,即参数文件的作用域,有以下几种方式:
△All threads:当前测试计划中的所有线程中的所有的线程都有效,默认;
△Current thread group:当前线程组中的线程有效;
△Current thread:当前线程有效;
==============
完成之后,将刚才生成的参数写入参数对应的值里面:

运行它,效果同上面⑤函数助手设置参数的一样。
小结:
每次调用函数,都会从文件中读取下一行。当到达文件末尾时,函数又会从文件开始处重新读取,直到最大循环次数。
如果在一个测试脚本中对该函数有多次引用,那么每一次引用都会独立打开文件,即使文件名是相同的
==================================
以上就是jmeter参数化的几种方式,其中:
1、函数助手_CSVRead的参数化功能相比CSV Data Set Config较弱;
2、CSV Data Set Config适用于参数取值范围较大的时候使用,该方法具有更大的灵活性;
3、User Defined Variables一般用于test plan中不需要随请求迭代的参数设置;
4、User Variables适用于参数取值范围很小的时候使用;
PS:相比于loadrunner来说,jmeter参数化有以下不同:
1.jmeter参数文件第一行没有列名称
2.参数文件的编码,尽量保存为UTF-8(编码问题在使用CSV Data Set Config参数化时要求的比较严格)
3.Jmeter的参数化没有LoadRunner做的出色,它是依赖于线程设置的(只有CSV Data Set Config参数化方法才有?)
参照:https://www.cnblogs.com/imyalost/p/6229355.html
