

Socket网络编程--简单Web服务器(3)
上一小节已经实现了浏览器发送请求,然后服务器给出应答信息,然后浏览器显示出服务器发送过来的网页。一切看起来都是那么的美好。这一小节就准备实现可以根据地址栏url的不同来返回指定的网页。目前还不考虑带参数的问题。
stat函数
#include <sys/stat.h>
int stat(const char *restrict pathname,struct stat * restrict buf);
int fstat(int filedes,struct stat * buf);
int lstat(const char *restrict pathname,struct stat * restrict buf);
给出pathname,stat函数就返回与此命名文件有关的信息结构。fstat函数获取已在描述符filedes上打开文件的有关信息。lstat函数类似与stat,但是命名的文件不是个符号链接。
实现指定url访问指定目录的web服务器

1 int WebServer::ServerRequest(int cli_fd) 2 { 3 char buf[1024]; 4 int size=1024; 5 int i,j; 6 char method[255];//用于保存请求方式 7 char url[512]; 8 char path[1024]; 9 struct stat st; 10 int cgi; 11 memset(buf,0,sizeof(buf)); 12 cgi=0; 13 //获取第一行请求信息 一般格式为: GET / HTTP/1.1 14 // POST / HTTP/1.1 15 size=get_line(cli_fd,buf,sizeof(buf)); 16 cout<<"\t\t"<<buf<<endl; 17 i=0,j=0; 18 //截取第一个单词 19 while(!isspace(buf[j]) && (i<sizeof(method)-1)) 20 { 21 method[i]=buf[j]; 22 i++;j++; 23 } 24 method[i]='\0'; 25 //取第一个与第二个单词之间的空格 26 while(isspace(buf[j]) && (j<sizeof(buf))) 27 j++; 28 //截取第二个单词 29 i=0; 30 while(!isspace(buf[j]) && (i<sizeof(url)-1) && (j<sizeof(buf))) 31 { 32 url[i]=buf[j]; 33 i++;j++; 34 } 35 url[i]='\0'; 36 37 if(strcasecmp(method,"GET") && strcasecmp(method,"POST")) 38 { 39 Page_501(cli_fd); 40 return -1; 41 } 42 43 if(strcasecmp(method,"GET")==0) 44 { 45 cout<<"此次请求的方式是GET方法"<<endl; 46 } 47 else if(strcasecmp(method,"POST")==0) 48 { 49 cout<<"此次请求的方式是POST方法"<<endl; 50 } 51 cout<<"此次请求的地址为:"<<url<<endl; 52 53 sprintf(path,"www%s",url);//这个是web服务器的主目录,这个以后可以处理成读取配置文件,这里就先写固定的www目录 54 if(path[strlen(path)-1]=='/') 55 strcat(path,"index.html");//同上 56 57 //根据文件名,获取该文件的文件信息。如果为-1,表示获取该文件失败 58 if(stat(path,&st)==-1) 59 { 60 while((size>0) && strcmp("\n",buf))//去除掉多余的请求头信息 61 size=get_line(cli_fd,buf,sizeof(buf)); 62 Page_404(cli_fd); 63 } 64 else 65 { 66 if((st.st_mode & S_IFMT)== S_IFDIR)//判断url地址,如果是个目录,那么就访问该目录的index.html 67 { 68 strcat(path,"/index.html"); 69 } 70 if((st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH))//判断该url地址所对应的文件是否是可执行,并且是否有权限 71 { 72 cgi=1;//是一个cgi程序 73 } 74 if(cgi==0)//如果cgi为0,那么就表示该url所对应的文件不是cgi程序,而是一个简单的静态页面 75 { 76 ServerCatHttpPage(cli_fd,path); 77 } 78 } 79 80 if(fork()==0) 81 { 82 //处理阶段 83 //execl("/bin/ls","ls","/home/myuser/",NULL); 84 //Page_200(cli_fd); 85 } 86 close(cli_fd); 87 return 0; 88 }
返回页的代码
1 int WebServer::ServerCatHttpPage(int cli_fd,char *path) 2 { 3 FILE * resource=NULL; 4 int size=1; 5 char buf[1024]; 6 buf[0]=1;buf[1]=0; 7 while((size>0) && strcmp("\n",buf))//去除掉多余的请求头信息 8 size=get_line(cli_fd,buf,sizeof(buf)); 9 10 resource=fopen(path,"r");//根据GET后面的文件吗,将文件打开 11 if(resource==NULL)//打开文件失败 12 { 13 Page_404(cli_fd); 14 } 15 else 16 { 17 char type[32]="text/html"; 18 char * p =type; 19 Page_Headers(cli_fd,p); 20 Page_Cat(cli_fd,resource); 21 } 22 fclose(resource); 23 return 0; 24 }
1 int WebServer::Page_Headers(int cli_fd,char * type) 2 { 3 char buf[1024]; 4 strcpy(buf,"HTTP/1.1 200 OK\r\n"); 5 send(cli_fd, buf, strlen(buf), 0); 6 sprintf(buf, "Server:wunaozai.cnblogs.com\r\n"); 7 send(cli_fd, buf, strlen(buf), 0); 8 sprintf(buf, "Content-Type: %s\r\n",type); 9 send(cli_fd, buf, strlen(buf), 0); 10 sprintf(buf, "\r\n"); 11 send(cli_fd, buf, strlen(buf), 0); 12 return 0; 13 } 14 int WebServer::Page_Cat(int cli_fd,FILE * fp) 15 { 16 char buf[1024]; 17 18 fgets(buf,sizeof(buf),fp); 19 while(!feof(fp)) 20 { 21 send(cli_fd,buf,strlen(buf),0); 22 fgets(buf,sizeof(buf),fp); 23 } 24 return 0; 25 }
代码写好了,我在当前目录下创建一个www的目录在里面有个index.html和text.html的页面。然后我们通过浏览器进行返回。得到的结果如下:
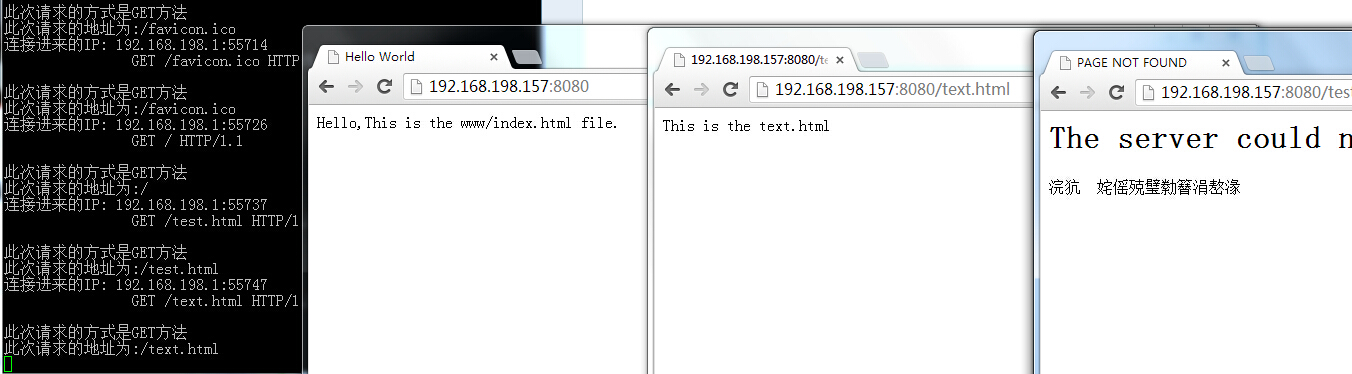
可以看出都显示了指定的网页信息,而最后一个是404页面,可是为什么会有乱码呢,应该是在应答信息哪里没有指点编码格式。所以我们在Page_404这个函数里的Content-Type这一行进行如下修改
1 sprintf(buf, "Content-Type: text/html;charset=utf-8\r\n");
当然还可以在html网页上进行指定。
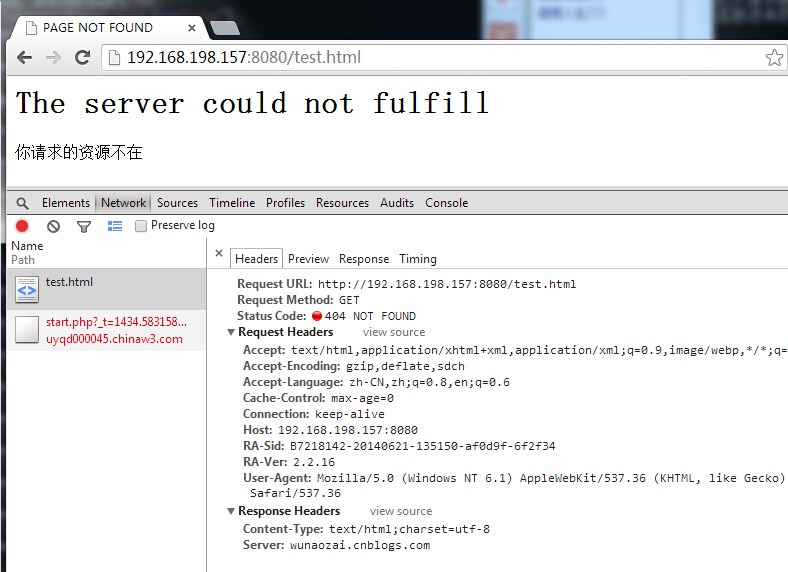
本小结篇幅比较少,接下来就实现传输一个ico图标吧。我们都知道一个html网页是通过一个url进行查找文件然后以http协议发送个浏览器。但是我们服务器怎么发送css或js或图片给浏览器呢?怎么知道那些是要的那些是不要的。一看是还以为很难,上网查了一下,原来很简单的。浏览器接收到根据url发送过来的html文件,然后浏览器会分析这个html文件中代码的图片文件,css文件等,然后在跟服务器建立一个http请求,请求一个新的文件。在发送的过程中,不是直接发送图片过去的,而是先编织成HTTP的格式发送给浏览器,其中还要指定这个图片的格式,大概就是这样了。说起来比较抽象,我用wireshark抓一个包看看。

可以看出这个应答信息的格式跟以前讲的是一样的。也是一个应答头,然后在应答头里有个Content-Length属性,里面包含接下来要接收的文件大小。
一开始使用下面代码进行文件的读取
1 int WebServer::Page_Cat(int cli_fd,FILE * fp) 2 { 3 char buf[1024]; 4 5 fgets(buf,sizeof(buf),fp); 6 while(!feof(fp)) 7 { 8 send(cli_fd,buf,strlen(buf),0); 9 fgets(buf,sizeof(buf),fp); 10 } 11 return 0; 12 }
然后在浏览器进行访问,然后就是一直访问不到图片资源,一直弄到凌晨几点。今天,想了个办法,对于图片一个字节一个字节的打印出来,弄了好久才知道,原来是因为图片资源里面有ascii码为0的字符,所以导致在发送的时候使用strlen时发送数据会不完整。哎......这个以后要注意啊。所以我准备使用fgetc来获取数据,要注意fgetc的返回值是int型,用char会出错,应该没有人跟我一样不小心吧。
1 int WebServer::Page_Headers(int cli_fd,char * type,int filesize) 2 { 3 char buf[1024]; 4 strcpy(buf,"HTTP/1.1 200 OK\r\n"); 5 send(cli_fd, buf, strlen(buf), 0); 6 sprintf(buf, "Server:wunaozai.cnblogs.com\r\n"); 7 send(cli_fd, buf, strlen(buf), 0); 8 sprintf(buf, "Content-Type: %s\r\n",type); 9 send(cli_fd, buf, strlen(buf), 0); 10 sprintf(buf, "Content-Length: %d\r\n",filesize); 11 send(cli_fd, buf, strlen(buf), 0); 12 sprintf(buf, "\r\n"); 13 send(cli_fd, buf, strlen(buf), 0); 14 return 0; 15 } 16 int WebServer::Page_Cat(int cli_fd,FILE * fp) 17 { 18 int c; 19 20 while((c=fgetc(fp))!=EOF) 21 { 22 send(cli_fd,&c,1,0); 23 } 24 return 0; 25 }
ServerCatHttpPage函数的代码如下
1 int WebServer::ServerCatHttpPage(int cli_fd,char *path,int filesize) 2 { 3 FILE * resource=NULL; 4 int size=1; 5 char buf[1024]; 6 char type[32]; 7 char * p =type; 8 buf[0]=1;buf[1]=0; 9 while((size>0) && strcmp("\n",buf))//去除掉多余的请求头信息 10 size=get_line(cli_fd,buf,sizeof(buf)); 11 12 //判断文件类型 13 int len=strlen(path); 14 cout<<path<<":"<<filesize<<endl; 15 if(path[len-4]=='h'&&path[len-3]=='t'&&path[len-2]=='m'&&path[len-1]=='l') 16 { 17 strcpy(type,"text/html"); 18 } 19 else if(path[len-4]=='.'&&path[len-3]=='i'&&path[len-2]=='c'&&path[len-1]=='o') 20 { 21 strcpy(type,"image/x-icon"); 22 } 23 else if(path[len-4]=='.'&&path[len-3]=='j'&&path[len-2]=='p'&&path[len-1]=='g') 24 { 25 strcpy(type,"image/jpeg"); 26 } 27 else 28 { 29 strcpy(type,"text/html"); 30 } 31 cout<<"请求资源的类型:"<<type<<endl; 32 33 resource=fopen(path,"r");//根据GET后面的文件吗,将文件打开 34 if(resource==NULL)//打开文件失败 35 { 36 Page_404(cli_fd); 37 } 38 else 39 { 40 Page_Headers(cli_fd,p,filesize); 41 Page_Cat(cli_fd,resource); 42 } 43 fclose(resource); 44 return 0; 45 }
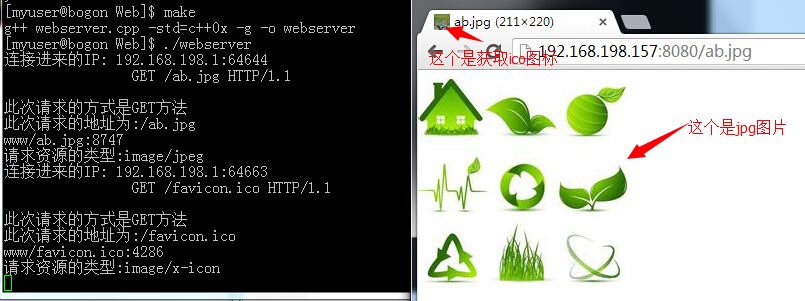
好了,感觉还不错的样子。
参考资料: http://bbs.csdn.net/topics/100130327
|
作者:无脑仔的小明 出处:http://www.cnblogs.com/wunaozai/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。有需要沟通的,可以站内私信,文章留言,或者关注“无脑仔的小明”公众号私信我。一定尽力回答。 |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构