
福大软工1816 · 第二次作业 - 个人项目
福大软工1816 · 第五次作业 - 结对作业2
一.链接
github传送门
本次作业传送门
结对同学博客传送门
二.具体分工
- 王全炯:负责CVPR论文的爬取和格式化,以及wordcount程序命令行代码的编写
- 郭俊彦:负责wordcount程序主体代码的编写,包括词频和词组频统计等功能模块
三.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | 710 | 2460 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 400 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 360 | 1200 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 600 |
| Reporting | 报告 | 75 | 110 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 795 | 2600 |
四.解题思路与设计描述说明
-
爬虫使用
先使用正则表达式匹配出每个论文详情页链接
然后使用beautifulsoup提取出title和abstract的标签
最后将其写入txt文件
import os import re import urllib import requests import sys import time from bs4 import BeautifulSoup url = "http://openaccess.thecvf.com/CVPR2018.py#" request = urllib.request.Request(url) resulst = urllib.request.urlopen(request) html = resulst.read() html = html.decode('utf-8') reg = r'<a href="(.+?\.html)">' papRe=re.compile(reg) paperlist = re.findall(papRe,html) le=len(paperlist) context = open("result.txt","w",encoding='utf-8') url_2="http://openaccess.thecvf.com/" i=0 print (time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))) for i in range(le): papget = urllib.request.Request(url_2+paperlist[i]) papRes = urllib.request.urlopen(papget) papRes = papRes.read() papRes = papRes.decode('utf-8') soup = BeautifulSoup(papRes,"html.parser") title= soup.select('#papertitle') abstr= soup.select('#abstract') context.write(str(i)+'\n') context.write('Title: '+title[0].text) context.write('\n') #print (title[0].text) #print ('\n') context.write('Abstract: '+abstr[0].text) context.write('\n') #print (abstr[0].text) print (time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))) print ("hello world") -
代码组织与内部实现设计
-
主函数进行命令行的解析以及调用相关函数来对字符、单词、词组三类对象进行统计和输出。
-
字符通过文件流逐行读入后进行ascii码的筛选和统计,同时进行有效行的计算。
-
单词由结构体链表进行存储,最后通过对单词尾节点的遍历压入优先队列内排序后进行输出。
-
词组存储在map容器里,以<字符串-频数>键值对形式存储,之后通过迭代器对map的遍历把词组和频数信息转储到vector
容器中借助重载运算符定义比较函数来进行sort排序,最后遍历输出。
-
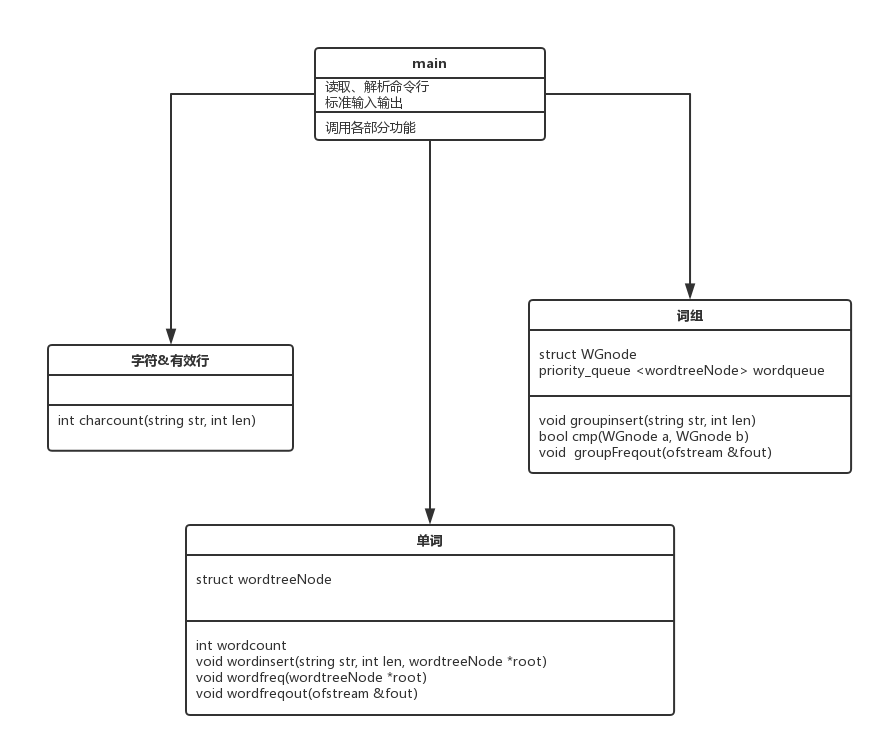
-
说明算法的关键与关键实现部分流程图
- 字符、有效行、单词的相关计算均沿用上次个人项目的思路,主要应注意有效行的判断以及换行符的统计以及指针的移动,此处不加累赘
- 词组统计部分设定了isword(目前单词内字符数)和isgroup(目前词组内单词数)两个标志位,同时借由tmpstr存储目前的临时单词及后缀,preword队列存储目前的临时词组,在游标移动的过程中进行逻辑判断,这是整个算法的核心部分。
-
在字符串连续读入四个字母之前isword以读到字母为条件自增,之后则开始允许接纳数字。清空的条件显然是读入非法单词或者单词结束即读到分割符的时候。
-
当游标在分隔符串之后首次读到字母且分隔符串之前已经读入合法单词的时候isgroup++,即isgroup是以一个单词完全结束(包括他的后缀完结)为条件自增。
-
在一个单词恰完全读取完毕的时候即单词后第一次读取到分隔符,会对isgroup进行判断,如果isgroup==词组长度-1,即算上目前恰读取完毕的单词正好符合词组长度要求时进行一次读入。
-
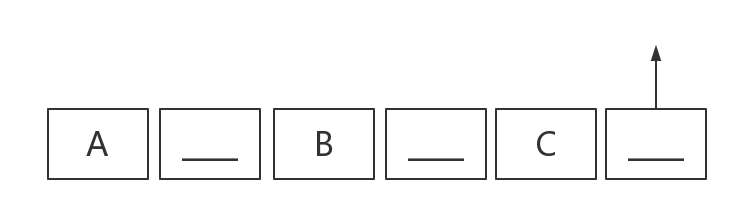
可以参考下面的例子结合上面图片进行理解
-
假设词组长度为3,此处设大写字母代表一个单词,设下划线(______)为分隔符串,当游标在单词C之后首次读到分隔符的时候,isgroup为2加上C这个单词恰好符合词组长度,可以将其存储下来。
在这个过程中tmpstr会将目前的临时单词(包含他的后缀)存储下来,而队列preword会保存之前的isgroup个单词(包含他的后缀)便于之后的操作。每进行一次词组存储isgroup--同时preword会pop一次。
五.附加题设计与展示
-
设计的创意独到之处
由于时间和能力的关系,实现的功能只是在原有的基础上进行了改进,不算是特别有意思或者独到的。
-
实现思路
在爬取的过程中,顺带记录下作者信息,并进行自动下载;接下来想做的是能不能扒一扒作者的信息(感觉比较好玩
-
实现成果展示
六.关键代码解释
- 字符由getline读入之后根据ascii可打印字符进行筛选,需注意补算上换行符
- 有效行通过置flag判断当前行是否有非空字符
- 单词统计由isword标志位根据连续出现四个字母为标准进行判断
- 词频统计将合法单词放入结构体链表当中最后压入优先队列排序,过程中要注意指针的移动以及旧字符串的保存
上述部分的整体代码都和上一次个人项目较为类似,此处就不加累赘,可以直接移步上次的博客。
- 下面为groupinsert的部分函数,主要思路可以参考上面算法关键写的应该不难理解
for (int i = ibegin; i < len; i++)
{
if (str[i] >= 'A' && str[i] <= 'Z')
str[i] += 32;
if (str[i] >= 'a'&&str[i] <= 'z')
{
if (tmpstr != ""&&isword == 0)//如果前面是一个单词完全结束
{
isgroup++;
preword.push(tmpstr);
tmpstr = "";
}
tmpstr += str[i];
isword++;
}
else if (isword < 4)//非法单词或分隔符
{
if (isgroup)//之前有合法单词
{
if (tmpstr != ""&&isword == 0)//在合法单词中可以吞字符
{
if (str[i] >= '0'&&str[i] <= '9')
{
tmpstr = "";
isgroup = 0;
preword = queue<string>();
}
else
tmpstr += str[i];
}
else//在非法单词中不能吞
{
tmpstr = "";
isgroup = 0;
preword = queue<string>();
}
}
else
tmpstr = "";
isword = 0;
}
else if (str[i] >= '0'&&str[i] <= '9')//合法单词继续接纳数字
{
tmpstr += str[i];
isword++;
}
else//分隔符 合法单词恰好结束tmpstr接受此分隔符同时开启一次读入
{
if (isgroup == (GL - 1))//之前的单词有GL-1个再加上目前这个即可压入树
{
temp = preword;
insertstr = "";
for (int j = 1; j < GL; j++)//插入长度为GL-1词组
{
insertstr += temp.front();
temp.pop();
}
insertstr += tmpstr;//插入目前为止的最后一个单词
iter = wordgroup.find(insertstr);
if (iter != wordgroup.end())
//iter->second++;
wordgroup[insertstr]++;
else
wordgroup.insert(map<string, int>::value_type(insertstr, 1));
isgroup--;
preword.pop();
}
tmpstr += str[i];
isword = 0;
}
}
if (isword >= 4)//特殊处理最后一个单词
{
if (isgroup == (GL - 1))//之前的单词有GL-1个再加上目前这个即可压入树
{
temp = preword;
temp.push(tmpstr);
insertstr = "";
for (int j = 1; j <= GL; j++)//插入长度为词组
{
insertstr += temp.front();
temp.pop();
}
iter = wordgroup.find(insertstr);
if (iter != wordgroup.end())
//iter->second++;
wordgroup[insertstr]++;
else
wordgroup.insert(map<string, int>::value_type(insertstr, 1));
}
}
}
简单来说就是借助isword和isgroup两个标志位,通过tmpstr存储目前的临时单词及后缀,preword队列存储目前的临时词组,在游标移动的过程中进行逻辑判断。
- 下面为map的定义和迭代器iter
map<string, int>wordgroup;
map<string, int>::iterator iter;
- 下面为之后存入vector的WGnode以及后面sort要用到的cmp函数
struct WGnode
{
string group;
int count;
WGnode() {}
WGnode(string _group, int _count) :group(_group), count(_count) {}
};
bool cmp(WGnode a, WGnode b)
{
if (a.count == b.count)
return (a.group.compare(b.group) <= 0);
return a.count > b.count;
}
- 下面为词组频率排序和输出的函数,通过min来控制输出数量
void groupFreqout(ofstream &fout)
{
map<string, int>::iterator it;
vector<WGnode> vec;
for (it = wordgroup.begin(); it != wordgroup.end(); it++)
{
vec.push_back(WGnode(it->first, it->second));
}
sort(vec.begin(), vec.end(), cmp);
int length = vec.size();
length = min(outctrmode, length);
for (int i = 0; i < length; i++)
{
fout << "<" << vec[i].group << ">: " << vec[i].count << endl;
}
}
七.性能分析与改进
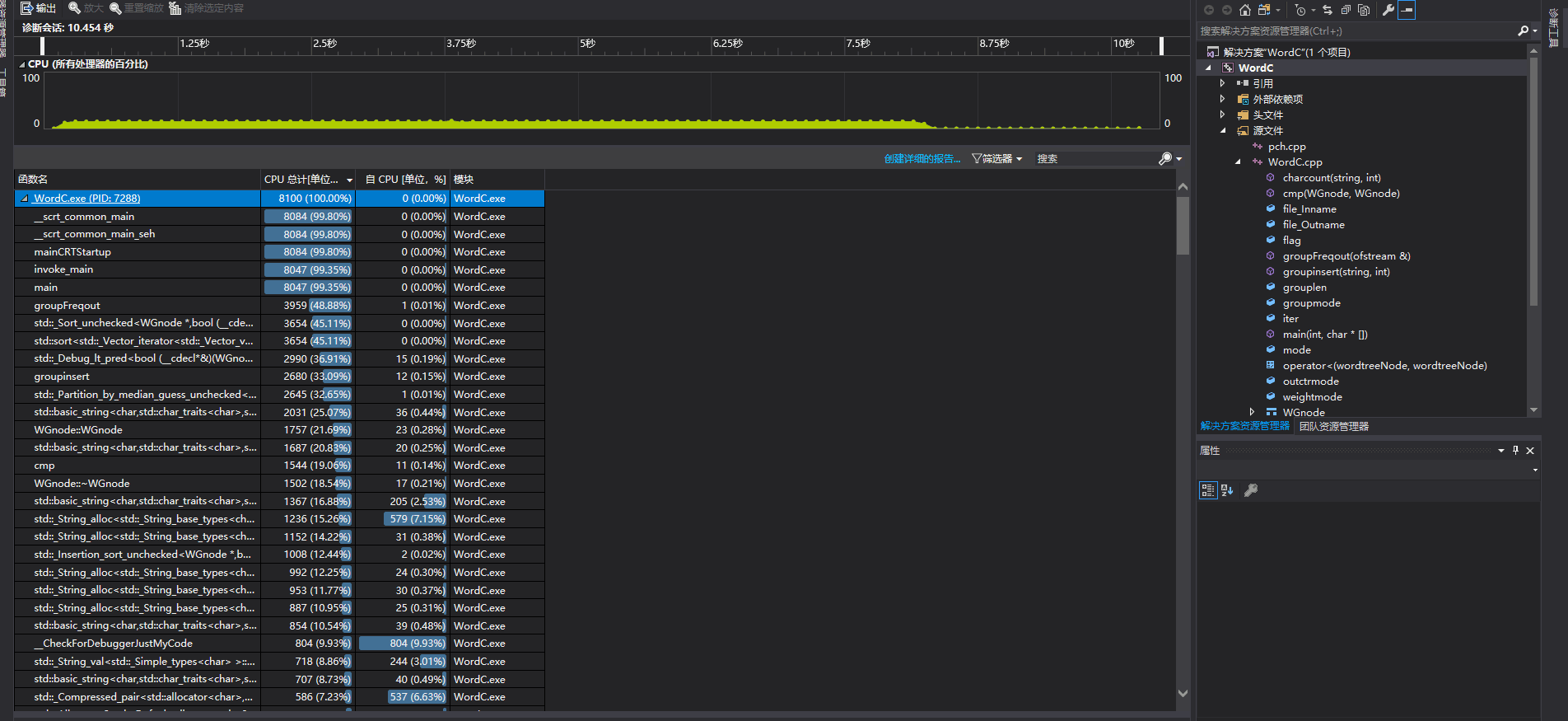
- 描述你改进的思路
- 最早的想法是词组统计上也完全沿用单词统计的那一套,但是因为不明的指针问题最后放弃了。在整体的效率上map应该是高于结构体链表的。之后词频的计算部分也可以把单词的容器由结构体迁移到map来。词组方面目前的做法是遍历map再把里面的键值对抓出来放到vector里面从而方便排序,以后的优化可以放在这个地方,试着不用更换容器直接进行排序,应该会剩下不少空间和时间。
- 展示性能分析图和程序中消耗最大的函数
八.单元测试
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
九.Github的代码签入记录
十.代码模块异常或结对困难及解决方法
-
问题描述
刚开始在词组的存储以及排序上面沿用了上次单词统计的思路,采取结构体链表进行处理。完成初版之后程序在devC++上
快乐地奔跑,而放在vs2017中时则会随机性地出现错误词组的输出,偶尔会报指针域冲突的错误。 -
做过哪些尝试
对于代码的总体逻辑以及词组插入链表的过程都进行了分析,同时也进行调试监控节点存储字符串内容是否正确,但是都没有找出问题是什么。后来干脆重写了词组插入函数groupinsert,然而呈现出一样的问题,再次对代码进行重审以及请教各路大佬之后依旧是很难看出问题出在哪里。插入中间变量的临时输出语句也看不出任何问题,实在是很折磨。最后只得改变存储容器,由结构体链表转战map。
-
是否解决
用STLmap来存储词组-频数对以后输出之类都很顺利,在devC++和vs2017上都能
愉快翱翔。 -
有何收获
极大地磨练了小组的受虐能力,在这个过程中自己对于vs的调试能力也有了一定的提高,对于链表的组织也更加的熟练了,同时学习了map的使用。以及学习到不要一直死磕一个问题,该转换思路的时候要学会变通。
十一.评价你的队友
-
值得学习的地方
俊彦是一个非常好说话的同学,在得知我要去旅游的时候,非常爽快地说:ass we can ,先去玩吧!他也非常有肝地精神,竟然debug到四点多。
导致被柯大魔王点了名(划掉。 -
需要改进的地方
和我一样都有一点点咸鱼,在合作进行开发的过程当中,常会碰到两个人都无法解决的问题,比较尴尬。
十二.学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 12 | 12 | 学习构建之法的前面部分内容 |
| 2 | 200 | 200 | 21 | 33 | 学习需求开发模型,巩固c++编程基础 |
| 3 | 200 | 400 | 22 | 55 | 学习原型工具墨刀,巩固c++ |
| 4 | 570 | 970 | 43 | 98 | 巩固结构体链表知识,学习STL map的使用,学习vs的调试功能使用方法 |

