

从SQL Server数据库转到Oracle数据库的数据脚本处理
在我们很多情况下的开发,为了方便或者通用性的考虑,都首先考虑SQL Server数据库进行开发,但有时候客户的生产环境是Oracle或者其他数据库,那么我们就需要把对应的数据结构和数据脚本转换为对应的数据库,数据结构一般来说,语法都遵循了SQL92的标准,或者我们根据不同的PowerDesigner文件进行生成对应的结构脚本即可,但是实际数据的脚本我们就需要进行一定的处理,以及文本的替换处理了,本文结合Notepad++的文本正则表达式替换,实现一些如日期较为特殊的数据脚本调整,把它从SQL Server转换为Oracle的处理过程,本文就是针对这些整体的数据库处理进行介绍。
1、数据库设计文件及数据库结构脚本
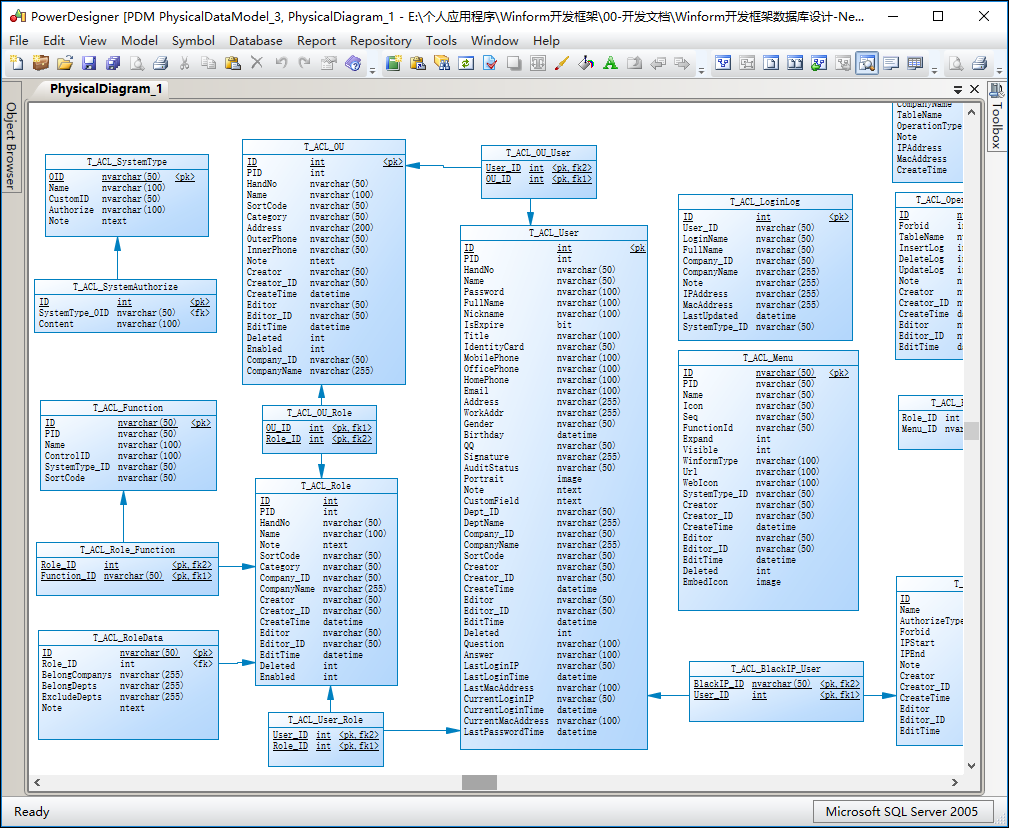
我们一般在做数据库设计的时候,都会使用PowerDesigner这样的数据库建模工具进行设计,默认把它设计为SQL Server的数据库设计模型,如下所示。
当然我们如果需要其他数据库,那么把它转换为对应的数据库,然后进行一定的数据库类型调整,以及字段的大小写转换即可。
根据这种方式我们调整后的各种数据库设计文件如下所示。
不同的数据库的设计模型有所差异,那么我们进行一些核对,主要是数据库类型的核对即可,如备注字段的大文本应该设置为CLOB,二进制的应该调整为BLOB等。
例如对于Oracle的数据库设计(从SQL Server转换过来的),同时也需要把它的字段名转换为大写才好,在PowerDesigner里面可以执行自定义函数进行处理。
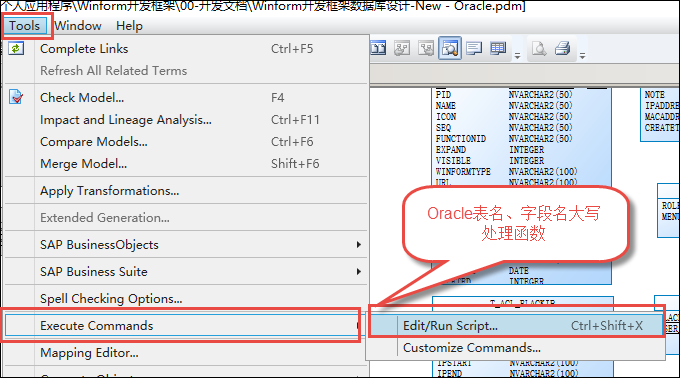
其中在对话框选择打开对应的大写字段表名的脚本,如下操作。
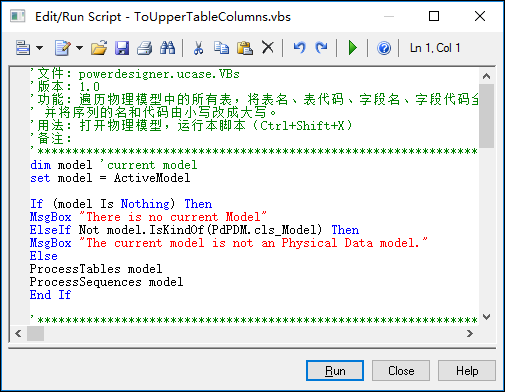
为了大家方便使用,我把它贴出来,供使用。
'文件:powerdesigner.ucase.VBs '版本:1.0 '功能:遍历物理模型中的所有表,将表名、表代码、字段名、字段代码全部由小写改成大写; ' 并将序列的名和代码由小写改成大写。 '用法:打开物理模型,运行本脚本(Ctrl+Shift+X) '备注: '***************************************************************************** dim model 'current model set model = ActiveModel If (model Is Nothing) Then MsgBox "There is no current Model" ElseIf Not model.IsKindOf(PdPDM.cls_Model) Then MsgBox "The current model is not an Physical Data model." Else ProcessTables model ProcessSequences model End If '***************************************************************************** '函数:ProcessSequences '功能:递归遍历所有的序列 '***************************************************************************** sub ProcessSequences(folder) '处理模型中的序列:小写改大写 dim sequence for each sequence in folder.sequences sequence.name = UCase(sequence.name) sequence.code = UCase(sequence.code) next end sub '***************************************************************************** '函数:ProcessTables '功能:递归遍历所有的表 '***************************************************************************** sub ProcessTables(folder) '处理模型中的表 dim table for each table in folder.tables if not table.IsShortCut then ProcessTable table end if next '对子目录进行递归 dim subFolder for each subFolder in folder.Packages ProcessTables subFolder next end sub '***************************************************************************** '函数:ProcessTable '功能:遍历指定table的所有字段,将字段名由小写改成大写, ' 字段代码由小写改成大写 ' 表名由小写改成大写 '***************************************************************************** sub ProcessTable(table) dim col for each col in table.Columns '将字段名由小写改成大写 col.code = UCase(col.code) col.name = UCase(col.name) next table.name = UCase(table.name) table.code = UCase(table.code) end sub
这样处理后,我们在PowerDesigner里面的表名及字段就可以正常转换为大写了,从而可以获得对应表的数据结构脚本,如果需要多个表,那么可以批量生成数据库结构脚本。
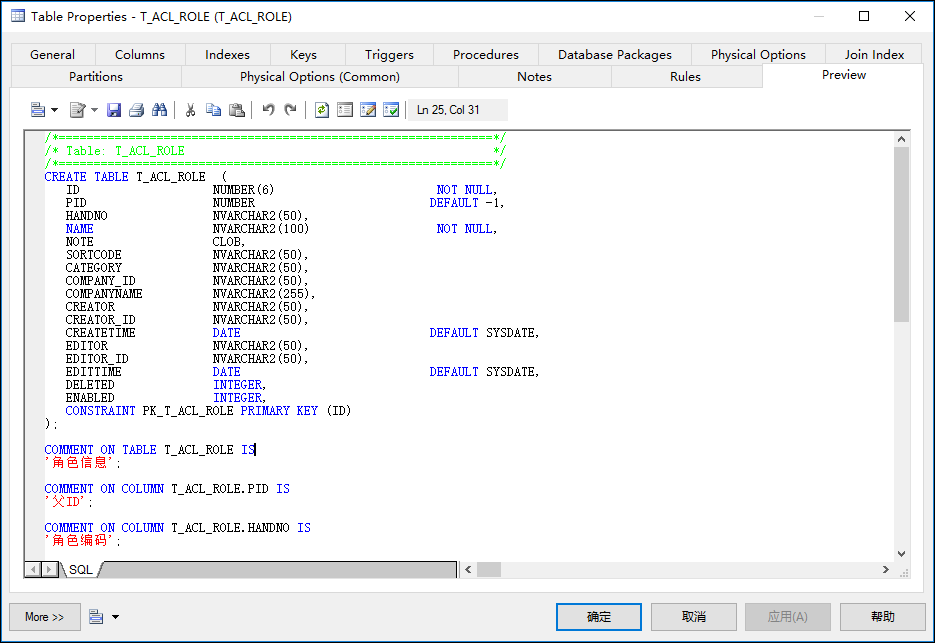
2、数据库表数据脚本的生成
上面的数据库表结构的脚本生成,只是我们数据库迁移脚本的一部分操作,有时候我们实际的框架或者业务系统里面,都往往有一些基础数据需要写入的,那么就需要我们构建对应的数据脚本了。
在数据库脚本导出的,我们可以使用很多工具,如SQL Server本身的工具就可以导出数据的SQL脚本,同时我们也可以利用其它数据库管理工具,如Toad For SQLServer或者Navicat Premium等数据库管理工具实现数据的导出脚本操作。
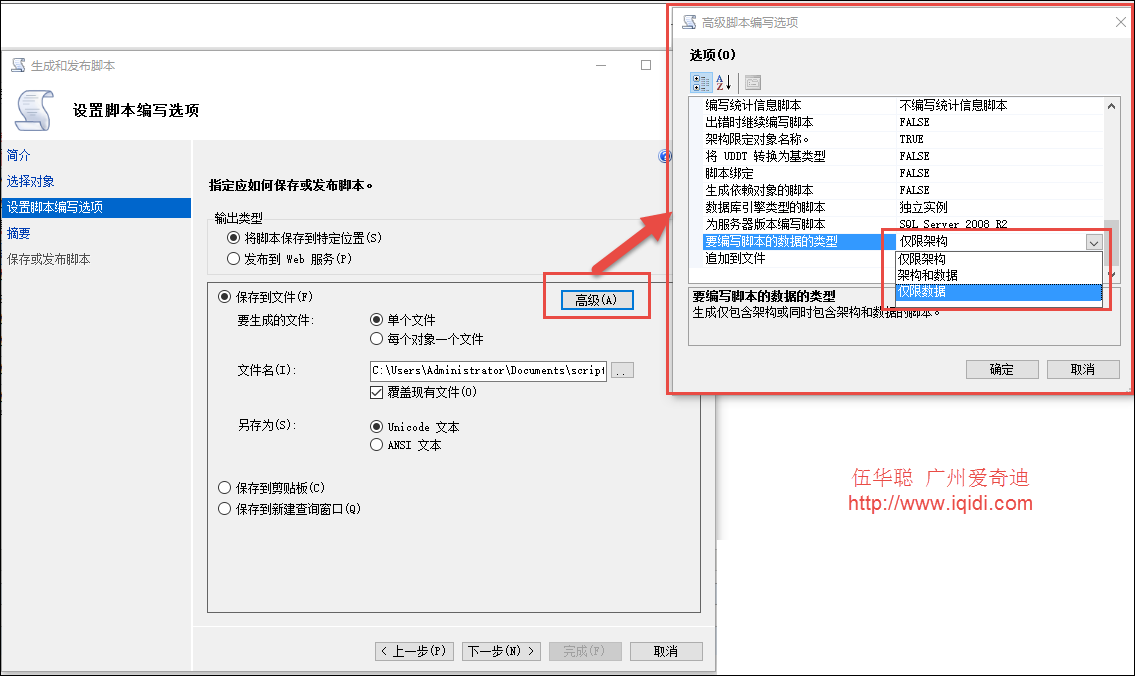
然后在生成脚本的过程中,设置输出的高级选项中的“要编写脚本的数据的类型”为【仅限数据】即可,如下所示。
不过默认采用SQLServer生成出来的数据脚本,对日期类型转换真不是很好,如下结果所示。
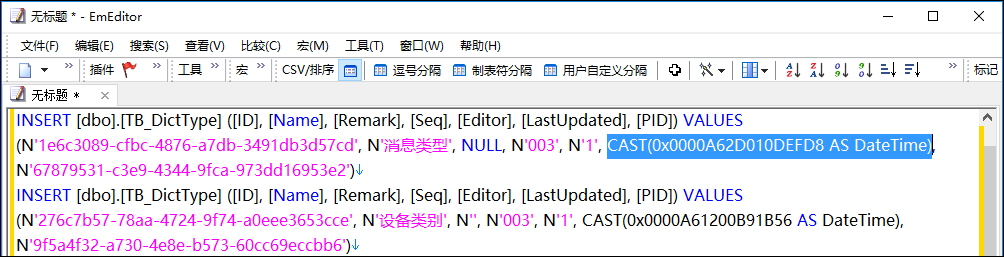
因此我使用更加直观显示的Navicat Premium 工具来处理数据库的数据脚本。使用Navicat Premium生成的脚本如下所示(仅仅日期类型有所不同)。
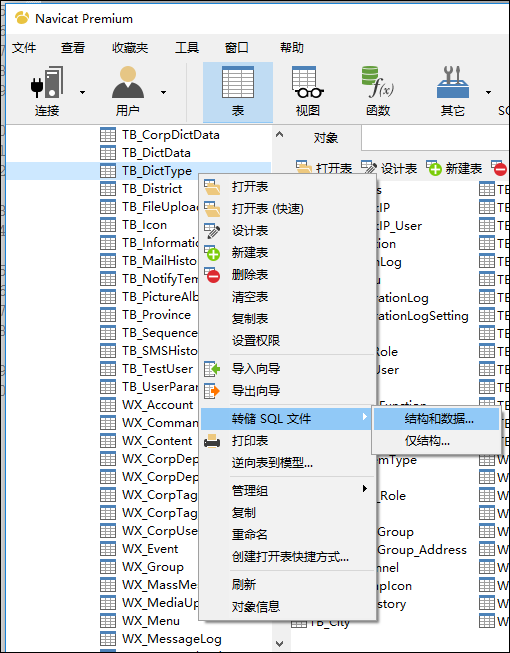
获得生成的数据脚本如下所示。
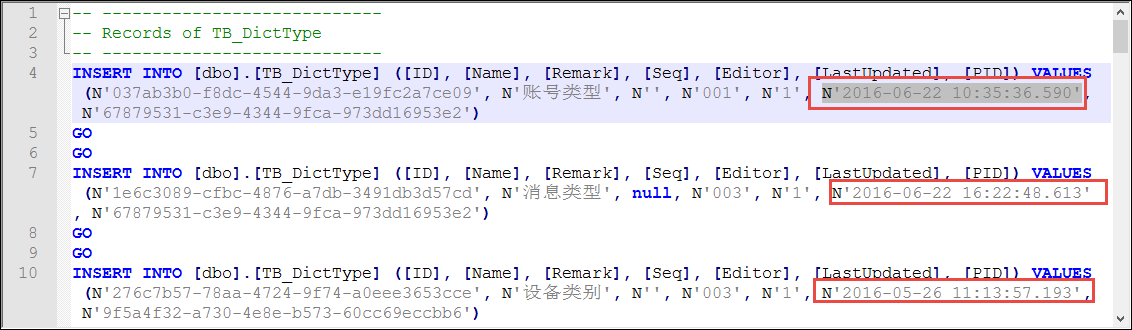
剩下的工作就是我们对这些数据脚本进行进一步的处理操作了。
3、数据表的数据脚本的替换处理
上面介绍了通过工具来获得正确的数据脚本,我们使用了Navicat Premium或者 Toad For SQLServer都能够获得类似下面格式的时间脚本。
N'2016-06-22 10:35:36.590'
这样我们为了处理为Oracle的日期数据,那么需要转换为
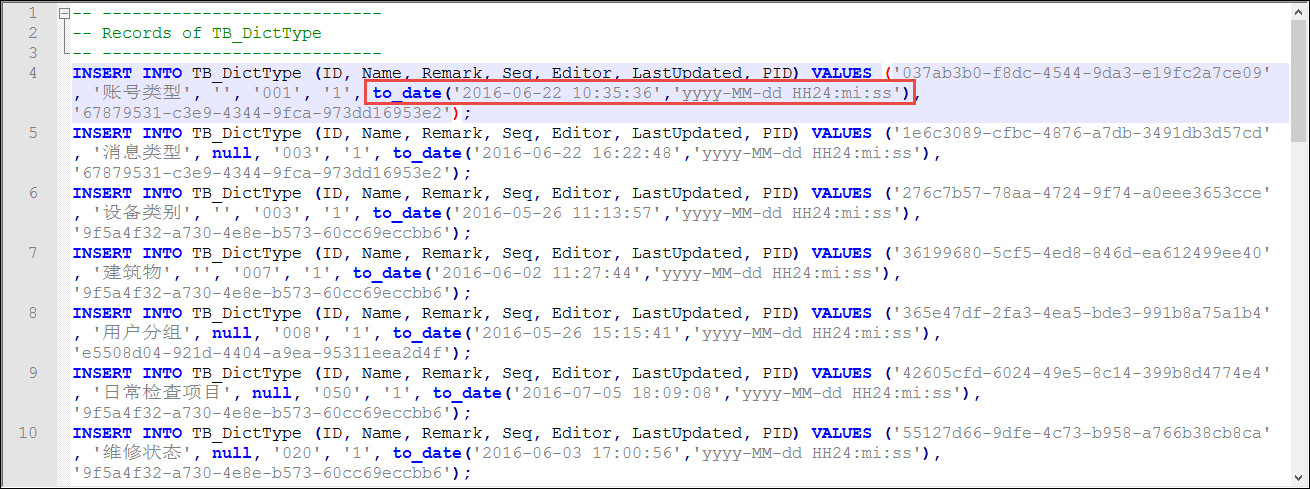
to_date('2016-06-22 10:35:36','yyyy-MM-dd HH24:mi:ss')
这样的格式
那么我们对上面的脚本,进行一定规则的处理,如替换:[dbo]. [ ] N'为' 等常规文本处理后,还需要再进行正则表达式规则的处理才可以,例如我们的日期替换的正则表达式如下:
'(\d{4}-\d{2}-\d{2}\s*\d{2}:\d{2}:\d{2})\.\d{3}'
to_date\('\1','yyyy-MM-dd HH24:mi:ss'\)
如下所示。
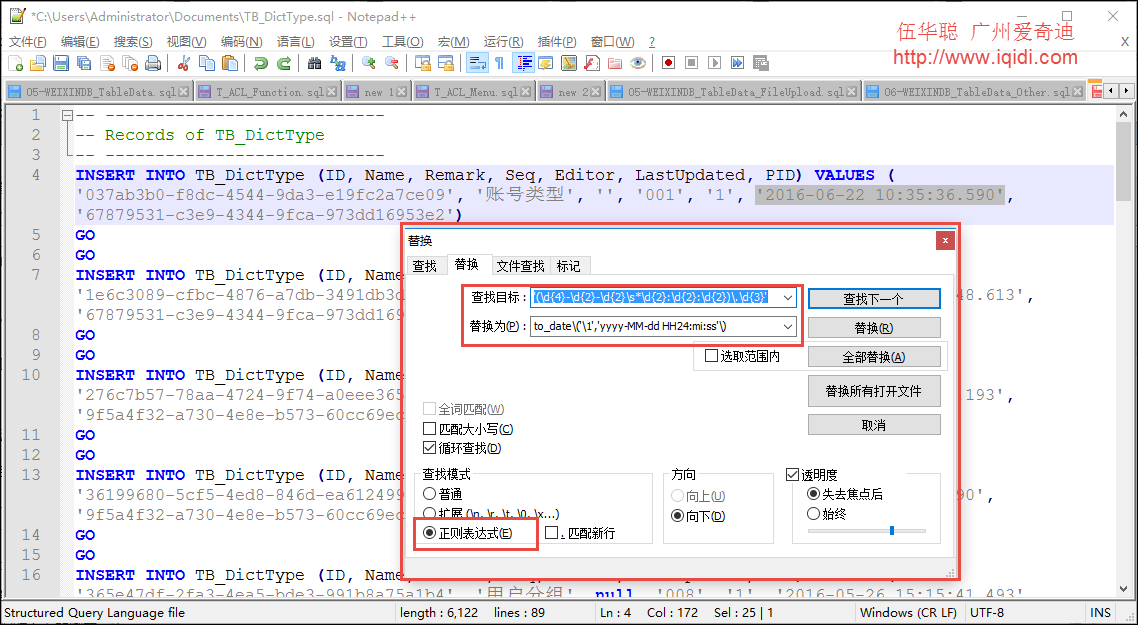
最后使用正则表达式替换后的数据库脚本如下所示。
4、数据脚本在PL-SQL Developer工具上执行操作
上面介绍如何实现了表数据的脚本生成,有了这些脚本,我们需要使用Oracle的数据库管理工具 PL-SQL Developer工具进行数据导入,才能最终完成整个过程。这个操作也是有所讲究的。
例如我们创建各类不同的数据库脚本,那么只需要按照顺序加入或者选择加入执行数据库脚本即可。
那么执行这些SQL,该如何操作呢,是不是直接拖动到PL-SQL上就可以了?
当然不是,否则长一点的数据库脚本,就可能导致非常迟缓的执行效率。
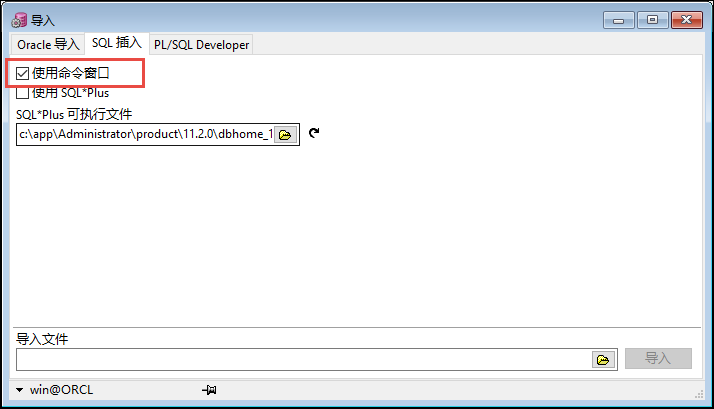
一般可以通过两种方式,一种是使用命令行的方式。

这种方式执行速度非常快,比起直接在PL-SQL的SQL窗口上执行更有效率。
另外一种方式,就是可以利用PL-SQL里面的另外一个地方进行执行数据库脚本,如下所示。
在【 工具】【导入表】的操作里面,弹出一个对话框,也是执行脚本高效的操作之一。
上面介绍的这些方式,就是在数据库没有的情况下,根据数据库脚本构建对应的数据对象和数据的。
 专注于代码生成工具、.Net/.NetCore 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架等框架产品。
专注于代码生成工具、.Net/.NetCore 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架等框架产品。
转载请注明出处:撰写人:伍华聪 http://www.iqidi.com

