
C专家编程 总结
1 类型转换
当执行算术运算时,操作数的类型如果不同,就会发生转换,数据类型一般朝着浮点精度高、长度更长的方向转换,整数型如果转换为signed不会丢失信息,就转换为signed,否则转换为unsigned。
K&R C所采用无房户后保留原著,就是当一个无符号类型与int或更小的整型混合使用时,结果类型是无符号类型。
2 C语言中const并不真正表示常量。
3 switch语句的缺点
1)switch语句最大的缺点是它不会在每个case标签后面的语句执行完毕后自动终止。
2)由于break语句事实上跳出的是最近的那层循环语句或switch语句,所以break可能使switch语句提前跳出结束。
4 C语言中的符号重载
| 符号 | 意义 |
| static |
在函数内部,表示该变量的值在各个调用间一直保持延续性 在函数这一级,表示该函数只对本文件可见 |
| extern |
用于函数定义,表示全局可见(属于冗余的) 用于变量,表示它在其他地方定义 |
| void |
作为函数的返回类型,表示不返回任何值 在指针声明中,表示通用指针的类型 位于参数列表中,表示没有参数 |
| * |
乘法运算符 用于指针,间接引用 在声明中,表示指针 |
| & |
位的AND操作符 取地址运算符 |
| = | 赋值符 |
| == | 比较运算符 |
|
<= <<= |
小于运算符 左移复合赋值运算符 |
| < |
小于运算符 #include指令的左定界符 |
| () |
在函数定义中,包围形式参数表 调用一个函数 改变表达式的运算次序 将值转换为其他类型(强制类型转换) 定义带参数的宏 包围sizeof操作符的操作数(如果它是类型名) |
5 C语言中的优先级
| 优先级问题 | 表达式 | 人们可能误以为的结果 | 实际结果 |
|
.的优先级高于*。->操作符 用于消除这个问题 |
*p.f | p所指对象的字段f (*p).f |
对p取f偏移,作为左值,然后进行 解除引用操作。*(p.f) |
| []高于* | int *ap[] | ap是个指向int数组的指针 int(*ap)[] | ap是个元素为int左值的数组int *(ap[]) |
| 函数()高于* | int *fp() | fp是个函数指针,所指函数返回int,int(*fp)() | fp是个函数,返回int*,int*(fp()) |
| ==和!=高于位运算符 | (val&mask!=0) | (val&mask)!=0 | val&(mask!=0) |
| ==和!=高于赋值符 | c=getchar()!=EOF | (c=getchar())!=EOF | c=(getchar()!=EOF) |
| 算术运算符高于移位运算符 | msb<<4+lsb | (msb<<4)+lsb | msb<<(4+lsb) |
| 逗号运算符在所有运算符中优先级最低 | i=1,2 | i=(1,2) | (i=1),2 |
结合性只用于表达式中出现两个以上相同优先级的操作符的情况,用于消除歧义。事实上,你会注意所有优先级相同的操作符,它们的结合性也相同。
6 返回局部对象的指针
char * localized_time(char* filename) { struct tm *tm_ptr; struct stat stat_block; char buffer[120]; stat(filename,&stat_block); tm_ptr=localtime(&stat_block.st_mtime); strftime(buffer,sizeof(buffer,"%a %b %e %T %Y",tm_ptr); return buffer; }
问题就出在最后一行,也就是返回buffer的那行。buffer是一个自动分配内存的数组,是该函数的局部变量。当控制流离开声明自动变量(即局部变量)的范围时,自动变量就会失效。这就意味着即使返回一个指向局部变量的指针,当函数结束时,由于该变量已被销毁,谁也不知道这个指针所指向的地址的内容是什么。
在C语言中,自动变量在堆栈中分配内存。当包含自动变量的函数或代码块退出时,它们所占用的内存便被回收,它们的内容肯定会被下一个调用的函数覆盖。这一切取决于堆栈中先前的自动变量位于何处,活动函数声明了什么变量,写入了什么内容等。原先自动变量地址的内容可能被立即覆盖,也可能稍后才被覆盖。
解决这种问题有几种方案:
1 返回一个指向字符串常量的指针。例如:
char* func() { return "Only works for simple strings";}
2 使用全局声明的数组。例如:
char *fun() {
...
my_global_array[i] =
...
return my_global_array;
}
这个适用于自己创建字符串的情况,也很简单易用。它的缺点在于任何人都有可能在任何时候修改这个全局数组,而且该函数的下一次调用也会覆盖该数组的内容。
3 使用静态数组。例如:
char * func()
{
static char buffer[20];
...
return buffer;
}
这就可以防止任何人修改这个数组。只有拥有指向该数组的指针的函数才能修改这个静态数组。但是,该函数的下一次调用将覆盖这个数组的内容,所以调用者必须在此之前使用或备份数组的内容。和全局数组一样,大型缓冲区如果闲置不用是非常浪费内存空间的。
4 显式分配一些内存,保存返回的值。例如:
char* func(){
char *s=malloc(120);
...
return s;
}
这个方法具有静态数组的优点,而且在每次调用时都创建一个新的缓冲区,所以该函数以后的调用不会覆盖以前的返回值。它适用于多线程的代码。它的缺点在于程序员必须承担内存管理的责任。根据程序的复杂程度,这项任务可能很容易,也可能很复杂。如果内存尚在使用就释放或者出现“内存泄露”(不再使用的内存未回收),就会产生令人难以置信的Bug。
5最好使用的解决方案就是要求调用者分配内存来保存函数的返回值。为了提高安全调用者应该同时指定缓冲区的大小。
void func(char* result,int size){
...
strncpy(result,"That't be in the data segment,Bob",size);
}
buffer=malloc(size);
func(buffer,size);
...
free(buffer);
如果程序员可以在同一代码块中同时进行“malloc”和“free”操作,内存管理是最为轻松的。这个解决方案就可以实现这一点。
7 声明是如何形成的
不合法的声明:
- 函数的返回值不能是一个函数,所以像foo()()这样是非法的。
- 函数的返回值不能是一个数组,所以像foo()[]这样是非法的。
- 数组里面不能有函数,所以像foo[]()这样是非法的。
合法的声明:
- 函数的返回值允许是一个函数指针,如: int(*fun())();
- 函数的返回值允许是一个指向数组的指针,如: int(*foo())[];
- 数组里面允许有函数指针,如int(*foo[])()
- 数组里面允许有其他数组,所以你经常看到int foo[][]
8 typedef的使用
typedef与define的区别:
首先,可以用其他类型说明符对宏类型名进行扩展,但对typedef所定义的类型名不能这样做。如下所示:
#define peach int
unsigned peach i; //没问题
typedef int banana;
unsigned banana i; //错误! 非法
其次,在连续几个变量的声明中,用typedef定义的类型能够保证声明中所有的变量均为同一种类型,而用#define定义的类型则无法保证。如下所示:
#define int_ptr int *;
int_ptr chalk,cheese;
经过宏扩展,第二行变为:
int * chalk,cheese;
这使得chalk和cheese成为不同的类型:chalk是一个指向int的指针,而cheese则是一个int。相反,下面的代码中:
typedef char* char_ptr;
char_ptr Bentley,Rolls_Royce;
Bentley和Rolls_Royce的类型依然相同。虽然前面的类型名变了,但它们的类型相同,都是指向char的指针。
//下面两个声明具有相似的形式 typedef struct fruit{ int weight, price_per_lb; } fruit; //语句1 struct veg{ int weight,price_per_lb; } veg; //语句2
但它们代表的意思却完全不一样,语句1声明了结构表情“fruit”和由“typedef声明的结构类型”fruit“,其实际效果如下:
struct fruit mandarin; //使用结构标签fruit
fruit mandarin; //使用结构类型fruit
语句2声明了结构标签veg和变量veg,只有结构标签能够在以后的声明中使用,如
struct veg potato;
如果试图使用veg cabbage这样的声明,将是一个错误。这有点类似下面的写法:
int i;
i j;
9 声明和定义的区别
记住,C语言的对象必须有且只有一个定义,但它可以有多个extern声明。
定义是一种特殊的声明,它创建了一个对象;声明简单地说明了在其他地方创建的对象的名字,它允许你使用这个名字。
定义 只能出现在一个地方 确定对象的类型并分配内存,用于创建的对象。例如,int my_array[100];
声明 可以多次出现 描述对象的类型,用于指代其他地方定义的对象(例如在其他文件里)例:extern int my_array[];
区分定义和声明
只要记住下面的内容即可分清定义和声明:
声明相当于普通的声明:它所声明的并非自身,而是描述其他地方的创建的对象。
定义相当于特殊的声明:它为对象分配内存。
extern对象声明告诉编译器对象的类型和名字,对象的内存分配则在别处进行。由于并未在声明中为数组分配内存,所以并不需要提供关于数组长度的信息。对于多维数组,需要提供除最左边一维之外其他维的长度——这就给编译器足够的信息产生相应的代码。
10 数组和指针的访问

C语言引入了”可修改的左值“这个术语,它表示左值允许出现在赋值语句的左边,这个奇怪的术语是为与数组名区分,数组名也用于确定对象在内存中的位置,也是左值,但它不能作为赋值的对象。因此,数组名是个左值但不是可修改的左值。
左值:出现在赋值符左边的符号有时被称为左值。
右值:出现在赋值符右边的符号有时则被称为右值。
编译器为每个变量分配一个地址(左值)。这个地址在编译时可知,而且该变量在运行时一直保存于这个地址。相反,存储于变量中的值(它的右值)只有在运行时才可知。如果需要用到变量中存储的值,编译器就发出指令从指定的地址读入变量值并将它存于寄存器中。
这里的关键之处在于每个符号的地址在编译时可知。所以,如果编译器需要一个地址(可能还需要加上偏移量)来执行某种操作,它就可以直接进行操作,并不需要增加指令首先取得具体的地址。相反,对于指针,必须首先在运行时取得它的当前值,然后才能对它进行解除引用的操作(作为以后进行查找的步骤之一)。

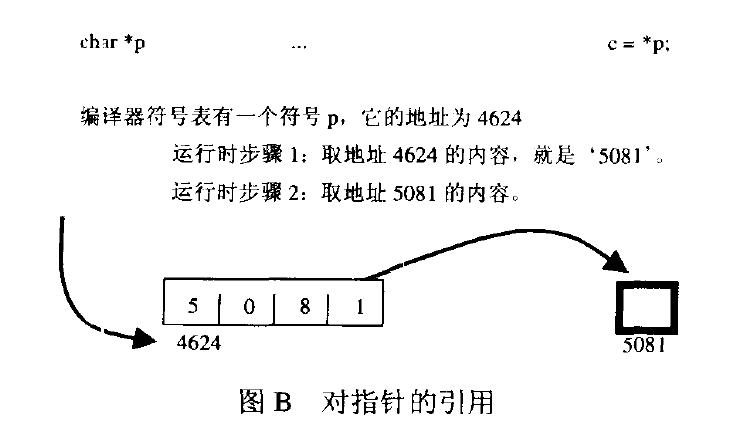
相反,如果声明extern char *p,它将告诉编译器p是一个指针,它指向的对象是一个字符。为了取得这个字符,必须得到地址p的内容,把它作为字符的地址并从这个地址中取得这个字符。指针的访问要灵活很多,但需要增加一个额外的提取,如图所示:
11 数组和指针的其他区别
比较数组和指针的另外一个方法就是对比两者的特点。
数组和指针的区别
| 指针 | 数组 |
|
保存数据的地址 |
保存数据 |
|
间接访问数据,首先取得指针的内容,把它作为地址,然后从这个地址提取数据。 如果指针有一个下标[I],就把指针的内容加上I作为地址,从中提取数据 |
直接访问,a[I]只是简单地从a+I为地址取得数据 |
| 通常用于动态数据结构 | 通常用于存储固定数目且数据类型相同的元素 |
| 相关的函数为malloc() free() | 隐式分配和删除 |
| 通常指向匿名数据 | 自身即为数据名 |
定义指针时,编译器并不为指针所指向的对象分配空间,它只是分配指针本身的空间,除非在定义时赋给指针一个字符串常量进行初始化。例如,下面的定义创建了一个字符串常量(为其分配了内存):
char *p="breadfruit";
注意只有对字符串常量才是如此。不能指望为浮点数之类的常量分配空间,如:
float *pip=3.141; //错误
初始化指针时所创建的字符串常量被定义为只读的。如果试图通过指针修改这个字符串的值,程序就会出现未定义的行为。
数组也可以用字符串常量进行初始化:
char a[]="gooseberry";
与指针相反,由字符串常量初始化的数组是可以修改的。
12 UNIX中的堆栈段和MS-DOS中的堆栈段
在UNIX中,当进程需要更多空间时,堆栈会自动生长。程序员可以想象堆栈是无限大的。这是UNIX胜过其他操作系统如MS-DOS的许多优势之一。在UNIX的实现中一般使用某种形式的虚拟内存。当试图访问当前系统分配给堆栈的空间之外时,它将产生一个硬件中断,称为页错误。处理页错误的方法有好几种,取决于对页的引用是否有效。
在正常情况下,内核通过向违规的进程发送合适的信号(可能是段错误)来处理对地址的引用。在堆栈顶部的下端有一个称为red zone的小型区域,如果对这个区域进行引用,不会产生失败。相反,操作系统通过一个好的内存块来增加堆栈段的大小。
在DOS中,在建立可执行文件时,堆栈的大小必须同时确定,而且它不能在运行时增加,如果你猜测错误,需要的堆栈空间大于所分配的空间,那么你和程序都会迷失。如果设置了检查选项,就会收到STACK OVERFLOW(堆栈溢出)消息。
13 返回局部指针的两种不同情况。
先看下面的程序:
#include<iostream> using namespace std; char* test2() { char p[] = "hello world"; return p; } char* test3(){ char *p = "hello world"; return p; } int main() { test2(); test3(); }
其中,test2中p是一个数组,分配在栈空间,在栈空间存放字符串。当是数组p,则函数会将字符串常量的字符逐个复制到p数组里面,返回p则是返回数组p,但是调用函数结束后p被销毁,里面的元素不存在了。
但是在test3中p是一个指针,则p指向存放字符串常量的地址,返回p则是返回字符串常量地址值,调用函数结束字符串常量不会消失(是常量)。所以返回常量的地址不会出错。
虽然都是返回局部变量的指针,但是test2结果会有问题,但是test3不会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号