
一、监督学习过程完整的流程(线性回归模型Linear Regression)
1. 训练集
在监督学习中我们有一个数据集,这个数据集被称训练集 。因此对于房价的例子 我们有一个训练集。
2. 现在我们给出这门课中经常使用的一些符号定义:
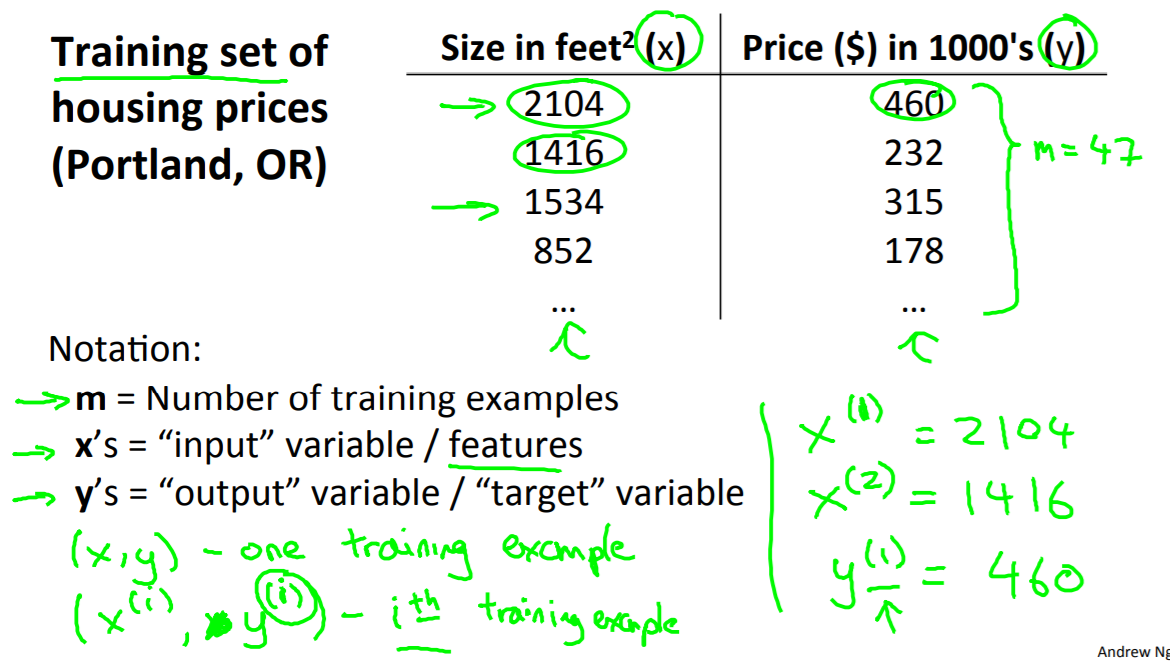
小写m:表示训练样本的数目。 因此,在这个数据集中,如果表中有47行 ,那么我们就有47组训练样本 。m就等于47;
小写x:表示输入变量 。往往也被称为特征量 ;
y:表示输出变量或者目标变量。 也就是我的预测结果;
(x, y):表示一个训练样本 。所以 ,在这个表格中的单独的一行对应于一个训练样本 ;
(x上标(i)与y上标(i)):表示某个训练样本。用这个表示第i个训练样本 。(x(i), y(i))是在此表中的第 i 行
小写h:代表hypothesis(假设) 。h表示一个函数。
3. 线性回归模型流程
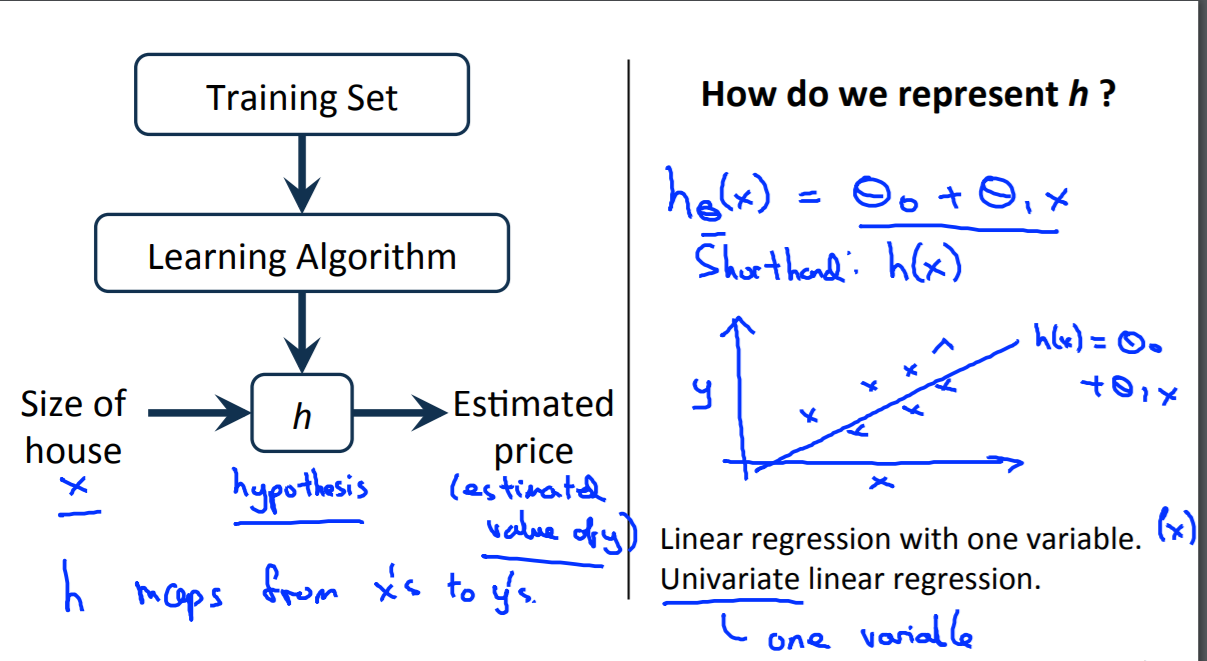
怎样得到这个假设h :
从这个图片中, 意味着我们要预测一个关于x的 线性函数 y ,所以这就是数据集和函数的作用 。用来预测 (这里是)y关于x的线性函数 hθ(x)=θ0+θ1*x
(有时候 我们会有更复杂的函数 ,也许是非线性函数。由于线性方程是简单的形式, 我们将先从线性方程的例子入手。)
这个模型被称为线性回归(linear regression)模型。另外 ,这实际上是关于单个变量的线性回归 ,这个变量就是x ,根据x来预测所有的价格函数。 同时 ,对于这种模型有另外一个名称 ,称作单变量线性回归 。
二、损失/代价函数(Cost Function)
1. 介绍代价函数
在线性回归中,我们有一个训练集,m代表了训练样本的数量 ,比如 M = 47 。而我们的假设函数 h,也就是用来进行预测的函数 ,是这样的线性函数形式 。

θ0和θ1: 这些θi我把它们称为模型参数,。
如何选择这两个参数值θ0和θ1 。选择不同的参数θ0和θ1, 我们会得到不同假设函数 。
我们要做的就是 ,得出θ0 、θ1这两个参数的值, 来让假设函数表示的直线 尽量地与这些数据点很好的拟合。
那么我们如何得出θ0、 θ1的值 ,来使它很好地拟合数据的呢?我们要选择能使h(x) (也就是输入x时我们预测的值 )最接近该样本对应的y值的参数θ0、θ1,即使得代价函数最小化 。所以 ,在我们的训练集中我们会得到一定数量的样本,要尽量好的选择参数值,使得 在训练集中, 给出训练集中的x值让我们能合理准确地预测y的值 。
2. 代价函数之平方误差函数
在线性回归中, 我们要解决的是一个**最小化问题 。所以我要写出关于θ0 、θ1的最小化。而且 ,我希望这个式子极其小,我想要h(x)和y之间的差异要小 。我要做的事情是,尽量减少假设的输出与房子真实价格 **之间的差的平方 。即:

而我希望尽量减小这个值 ,也就是预测值和实际值的差的平方误差和 ,我们还要尝试尽量减少我们的平均误差 ,也就是尽量减少其1/2m 。这意味着我们要找到θ0和θ1 的值,来使这个表达式的值最小, 而这个表达式因θ0和θ1的变化而变化。我们想要做的就是关于θ0和θ1 对函数J(θ0,θ1)求最小值 ,这就是我的代价函数。代价函数也被称作**平方误差函数 **,有时也被称为 平方误差代价函数 。还有其他的代价函数也能很好地发挥作用 ,但是平方误差代价函数可能是解决回归问题最常用的手段了。
3.举例:代价函数到底是在干什么
我们想找一条直线来拟合我们的数据 ,所以我们用 θ0 、θ1 等参数 ,得到了这个假设。 而且通过选择不同的参数 ,我们会得到不同的直线拟合。
所以拟合出的数据就像这样, 然后我们还有一个代价函数,下图就是我们的优化目标。我们先将θ1 简化为0,即:

结果你会发现, 你算出来的这些值能得到一条这样的曲线 。通过计算这些值 ,你可以慢慢地得到这条线 ,这就是 J(θ) 的样子了 :
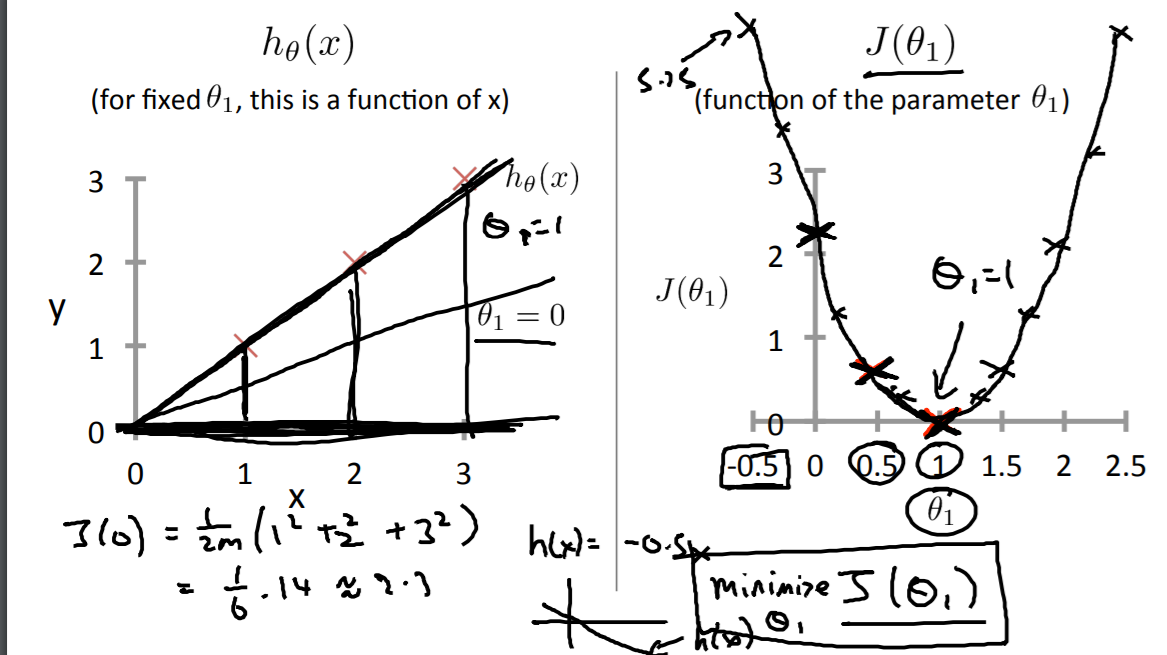
已知,任何一个 θ1 的取值对应着一个不同的 假设函数 ,即对应图中左边一条不同的拟合直线。 对于任意的θ1 ,你可以算出一个不同的 J(θ1) 的取值,对于任意一个 θ1 的取值,我们会得到 一个不同的 J(θ1) 。即对应图中右边利用这些来描出这条曲线。
而我们的学习算法的优化目标是:我们想找到一个 θ1 的值 ,来将 J(θ1) 最小化 。这个例子中, 曲线 让 J(θ1) 最小化的值时,θ1 等于1 。而最小化 J(θ1) 对应着寻找一个最佳拟合直线的目标。
