

SQL Server中的事务日志管理(1/9):事务日志概况
当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的。你只要确保每个数据库都有正确的备份。当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时。这系列文章会告诉你每个DBA应该知道的具体细节。
事务日志是存储对应数据库所有事务和数据修改记录的文件(每个数据库都有对应的日志文件)。在造成SQL Server意外关闭的灾难事件里,例如实例或硬件故障,事务日志用来恢复数据库,用来保证数据的完好无损(完整性)。在重启前,数据库进入恢复过程,事务日志被读取保证所有有效,提交的数据写入数据文件(前滚)而生效,未提交的事务会撤销(回滚)。简单来说,事务日志是SQL Server保证数据库完整性和事务ACID(原子性、一致性、隔离性、持久性)属性,尤其是持久性的基本架构。
根据事务日志管理DBA的一些重要职责如下:
- 选择正确恢复模式——SQL Server提供3个恢复模式:完整(默认),简单和大容量日志。DBA必须根据业务需求对数据库选择正确的模式,然后用这个模式建立合适的维护流程。
- 进行事务日志备份——除非使用简单模式,DBA进行常规的事务日志备份非常重要。一旦拿到备份文件,日志文件可以随后应用到一个完整备份来进行数据库恢复,因此可以重建先前某个时间点存在的数据库,例如刚好在故障前。
- 监视管理日志增长——在忙碌的数据库中事务日志大小可以很快的增长。如果没有定期备份,或者大小不合适,或者指定不正确的增长率,事务日志文件会被填满,导致臭名昭著的“9002”(事务日志已满)错误,它把SQL Server进入“只读”模式(或“资源等待”模式,这只在恢复期间发生)。
- 优化日志读写和可用性——另外对于例如备份的基本维护外,DBA必须采取措施来保证事务日志的达到预期的功能。这包括硬件方面的考虑,也有避免例如日志碎片的情况,它会影响事务性能。
在这个系列文章里,我们会关注这些核心维护工作的每个细节。这里,第一篇,我们从SQL Server如何使用事务日志开始,还有影响DBA生活的最重要的2个方式,即数据库恢复与磁盘空间管理。
SQL Server如何使用事务日志
在SQL Server里,事务日志是个物理文件,按照常理来说是LDF的扩展名,当并不强制。在数据库创建的时候会自动生成,随同主数据文件一起,一般是MDF的扩展名,但任何扩展名也是可以使用的,它存储数据库对象和数据本身。事务日志,一般以一个单独物理文件生成,也可以用多个文件生成。但是,在多个文件的情况下,SQL Server还是把它当作简单的序列文件,就其本身而论,SQL Server不能并行写入多个日志文件,因此使用多个日志文件并不会带来性能上的提升。这个会在第7篇——事务日志的的大小和增长里详谈。
任何时候T-SQL代码对数据库对象或它包含的数据做出的改变(DDL),不但在数据文件里数据和对象会更新,而且在事务日志里修改的细节会作为日志记录(log record)进行记录。每个日志记录包含细节,关于进行修改的事务ID,事务何时开始和结束,哪些页被修改,哪些数据被修改等等。
备注:事务日志并不是审计跟踪。它不提供对数据库做出改变的审计跟踪;他不保持对数据库已执行命令的记录,只有数据如何改变的结果。
当一个数据被修改,相关的数据页,希望是从数据缓存读取,如果他们还没在缓存的话会首先从磁盘重新获取。在数据缓存里数据被修改,在日志缓存里,描述事务影响的日志记录被创建。当一个事务被提交,日志记录会写入磁盘上的事务日志。但是,实际的数据改变还没写入磁盘,直到随后数据库检查点(Database checkpoint)发生时。在缓存里的任何页,自从磁盘读取后已被修改,这样的话缓存里数据值和磁盘上的值不一样,这就是所谓的脏页。这些脏页会包含:
- 已提交的数据并写入事务日志文件但没写入数据文件;
- 通过打开事务修改的数据,但还未提交(或回滚)。
定期的数据库检查点处理扫描数据缓存,把所有的脏页写入磁盘,在这个点,日志文件里的修改会在物理数据文件里体现。即使事务还是打开的情况也会发生;在检查点期间,脏页相关的打开事务都会写入磁盘,即在脏页写入数据文件前,SQL Server总会保证这些打开事务的日志记录都从日志缓存写入事务日志文件。
备注:另一个扫描数据缓存的惰性写入器(LazyWriter),也会写脏数据页到磁盘,除检查点外,它会因为内存压力而这样做。
这里需注意的要点是日志缓存管理器总保证描述修改的日志记录,在数据页写入物理数据文件前,会写入磁盘上的事务日志。这种机制被称为预写式日志(Write-Ahead Logging)。它是SQL Server保证事务持久性(Durability)的基本机制(围观下数据库事务的ACID属性)。
通过总首先写入修改到日志文件,SQL Server有可以保证所有提交事务的影响最终会在数据文件里体现的基本机制,还有源于磁盘上未完成事务的任何数据修改,例如对于哪些既不提交也不回滚的最终都不会在数据文件里体现。
如果数据库崩溃,例如,在某个事务T1提交后,但在写入数据文件生效前重启了,数据库恢复进程(databse recovery process)会初始化,尝试调节事务日志文件和数据文件内容的一致。它会读取事务日志文件并保证事务T1的记录在日志文件里的所有操作,被“前滚”(重做)这样的话,它们会在数据文件里体现。
同样,数据库崩溃后,恢复进程会“后滚”(撤销)数据库里的任何未提交事务的数据修改,通过从日志文件里读取相关操作,在数据上进行逆物理操作。
在崩溃事件里,这个方式里,SQL Server会返回数据库到一个一致的状态。一般来说,回滚(撤销)进程会在下列情况发生:
- 对于显性事务的ROLLBACK命令
- 发生错误且XACT_ABORT设置打开
- 如果数据库检测到数据库和客户端策动事务的通讯中断
在这个情况下,日志记录属于中断的事务,或者是显性触发ROLLBACK命令的事务,这些日志记录会被读取并回滚修改。在这些方式里,SQL Server保证事务相关的所有操作都作为一个单元要么全部成功,要么全部失败。同样在日常操作期间,事务日志是SQL Server重现它的一个基础,用来保证数据一致性(consistency)和完整性(integrity)。
另外,事务日志扮演了另一个重要角色,在灾难发生时,它提供数据库可以恢复到先前时间点的机制。使用合适的计划和管理,在它们损坏或不可用时,你可以使用这些日志文件备份来恢复你所有数据到某个时间点。
事务日志和数据库恢复
刚才提到,一个事务日志文件存储一系列的日志记录,根据事务开始的时间排序,它提供了修改的历史记录和已对数据库发出的事务。每个日志记录包含进行改变事务的ID,事务什么时候开始和结束,那些页被修改,对数据所做的修改等等。事务日志文件里日志记录由多个部分组成,即虚拟日志文件(Virtual Log Files(VLFs)),这个会在第2篇——事务日志架构里详细讲解。
SQL Server的预写式日志(write-ahead logging)机制保证修改的描述(例如日志记录)会在数据本身修改写入数据文件前写入VLF。因此,一个日志记录会包含关闭(已提交)事务或打开(未提交)事务的详细信息,在数据被事务修改的不同情况下,会已经或没有写入数据文件,取决于检查点是否已发生。
备注:通过定期将脏页从缓存写入磁盘,数据库检查点过程控制着数据库恢复操作期间的工作量。如果SQL Server需要为大量脏页相关的提交事务前滚做出改变,恢复过程会非常长。
在恢复期间,和打开事务相关的任何日志记录都需要回滚操作,且总会称为所谓活动(active)VLF的一部分,在日志文件里都会保留。和关闭事务相关的日志记录也会成为活动VLF的一部分,直到到达检查点,在整个VLF里没有打开事务相关的日志记录,在这个点VLF变成不活动(inactive)。
在这些不活动的日志记录里本质上提供了先前已完成的数据库事务的“历史”,对这些不活动的VLFs的不同操作取决于数据库的恢复模式。我们会在第3篇到第6篇详细讨论这些恢复模式,但这里的关键点是,如果你使用完整(或大容量日志)数据库恢复模式,事务日志在不活动的VLFs保留日志记录,直到(最近不久)进行了一次日志备份。
通过备份事务日志,我们可以在活动日志里的所有日志文件,也包括不活动VLFs里的日志文件,捕获到备份文件。这些日志备份可以用来恢复你的数据库到先前的某个时间点;甚至很有希望恢复到”灾难“发生前的一个时间点。在灾难这样的事件里,日志备份文件可以追加到完全数据库备份的副本,在数据库恢复期间,在完整备份后发生的任何事务都会”前滚“,恢复数据库并恢复到给定的时间点,因此会最小化任何数据丢失。当然,这是假设你已经做这些日志备份,并把它们传送到一个安全的地方。如果你的日志备份文件和活动日志文件在同个硬盘,那个硬盘崩溃后,你也会丢失你的备份。
当数据库在简单恢复模式(在第3篇-第4篇会详细介绍),在活动VLFs里的日志记录会保留,因为它们对于回滚操作需要。但是,当检查点发生时,活动的VLFs会被清理,这就是说在这些VLFs里日志记录会被新的日志记录覆盖。这就是为什么简单恢复模式的数据库操作指的是自动截断模式,在日志里没有“历史”维护,因此它不能在日志备份里捕获,也不能作为恢复的一部分。
控制日志文件大小
希望刚才的介绍已经让你明白,对于大多数运行在完整恢复模式的生产数据库,进行定期的日志文件备份是必须的,这样可以让数据库恢复到特定的时间点。
当在完整(或大容量日志)模式下,还有一点重要的原因需要进行定期的日志文件备份,那就是控制日志文件大小。记住,在SQL Server数据库里,对于每个修改数据或对象的事务都有日志记录写入日志文件。在忙碌的系统里,会有很多并发的事务,或者一个事务写入很多数据,事务日志文件会增长会非常快。
当在完整(或大容量日志)模式下,将非活动VLFs里的日志记录备份到文件,是唯一截断这些活动VLFs的方法,就是说这些被日志记录占用的空间可以被重用。
对于截断和事务日志大小的备注:截断日志文件有个常规误区:日志记录被删除,文件大小会变小。不是这样的:日志文件截断只是标记这些空间可以重用。截断,在不同恢复模式下的上下文里,会在接下来的文章里详细讨论。
因此,当在完整(或大容量日志)模式下进行定期的事务日志备份的重要原因是控制日志文件的大小。
事务日志备份的简单例子
为了简单演示下在这篇文章里我们已经讨论的概念,我们会举一个完整恢复模式下的数据库的事务日志备份例子。在接下来的文章里,每个流程和命令会详细讲解。
在1.1的代码里,我们在SQL Server 2008实例上创建一个新的TestDB数据库,使用DBCC SQLPERF(LOGSAPCE)来获得日志日志文件大小。
1 USE master ; 2 IF EXISTS ( SELECT name 3 FROM sys.databases 4 WHERE name = 'TestDB' ) 5 DROP DATABASE TestDB ; 6 CREATE DATABASE TestDB ON 7 ( 8 NAME = TestDB_dat, 9 FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\TestDB.mdf' 10 ) LOG ON 11 ( 12 NAME = TestDB_log, 13 FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\TestDB.ldf' 14 ) ; 15 DBCC SQLPERF(LOGSPACE) ;
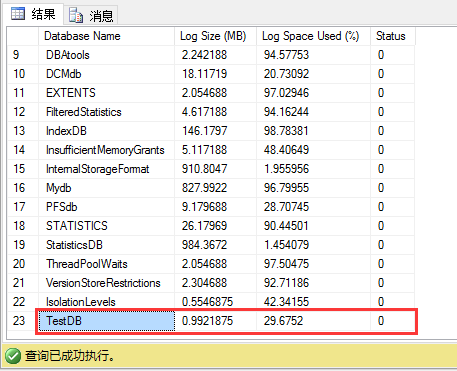
可以看到,当前日志文件大小近1MB,30%满。
备注:在实例上创建的用户数据库的初始大小和增长属性是由model数据库的属性决定的,默认情况下每个数据库使用的恢复模式是(完整,在这里)。我们会在第7篇——事务日志的大小和增长详细讲解这些属性的影响。
我们可以到本地硬盘的对应目录下确认下文件的大小。

现在我们对TestDB进行数据文件的备份。(你首先要创建“Backups”目录)。注意这个备份操作是在完整恢复模式下进行;在第3篇——事务日志,备份和恢复会有更多详细讲解。
1 -- full backup of the database 2 BACKUP DATABASE TestDB 3 TO DISK ='C:\Backups\TestDB.bak' 4 WITH INIT; 5 GO
备份完成后,数据文件、日志文件的大小及日志空间的使用率都没有改变,这一点也不奇怪,因为当前在数据库没有用户表和数据。我们在数据库上创建LogTest表,往表里插入100万条记录,再检查下数据库大小。不要担心代码的细节;这里最重要的是我们插入了很多行。这个代码在你电脑上可能会运行几十秒,并不是因为代码并不高效:它只是在后台运行,写入数据和日志文件。
1 USE TestDB ; 2 GO 3 IF OBJECT_ID('dbo.LogTest', 'U') IS NOT NULL 4 DROP TABLE dbo.LogTest ; 5 --===== AUTHOR: Jeff Moden 6 --===== Create and populate 1,000,000 row test table. 7 -- "SomeID" has range of 1 to 1000000 unique numbers 8 -- "SomeInt" has range of 1 to 50000 non-unique numbers 9 -- "SomeLetters2";"AA"-"ZZ" non-unique 2-char strings 10 -- "SomeMoney"; 0.0000 to 99.9999 non-unique numbers 11 -- "SomeDate" ; >=01/01/2000 and <01/01/2010 non-unique 12 -- "SomeHex12"; 12 random hex characters (ie, 0-9,A-F) 13 SELECT TOP 1000000 14 SomeID = IDENTITY( INT,1,1 ), 15 SomeInt = ABS(CHECKSUM(NEWID())) % 50000 + 1 , 16 SomeLetters2 = CHAR(ABS(CHECKSUM(NEWID())) % 26 + 65) 17 + CHAR(ABS(CHECKSUM(NEWID())) % 26 + 65) , 18 SomeMoney = CAST(ABS(CHECKSUM(NEWID())) % 10000 / 100.0 AS MONEY) , 19 SomeDate = CAST(RAND(CHECKSUM(NEWID())) * 3653.0 + 36524.0 AS DATETIME) , 20 SomeHex12 = RIGHT(NEWID(), 12) 21 INTO dbo.LogTest 22 FROM sys.all_columns ac1 23 CROSS JOIN sys.all_columns ac2 ; 24 DBCC SQLPERF(LOGSPACE) ;

可以看到日志文件已经膨胀到近100MB,日志已经近93%满(每个数据库上看到的结果都会不一样)。如果我们插入更多的数据,它会继续增长来容纳更多的数据,文件大小我们可以在本地硬盘的对应目录上进行确认(数据文件已经增长到54M)。

我们可以用刚才的代码再次备份数据文件,同样也不会对数据文件、日志文件和日志空间使用率造成影响。现在我们备份下事务日志文件,再次检查下文件大小。
1 -- now backup the transaction log 2 BACKUP Log TestDB 3 TO DISK ='C:\Backups\TestDB_log.bak' 4 WITH INIT; 5 GO 6 DBCC SQLPERF(LOGSPACE) ;
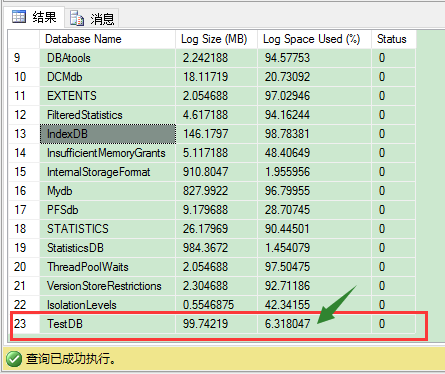
日志文件还是一样的物理大小,但是通过备份文件,SQL Server可以截断日志,在“不活动”VLFs里日志文件标记空间作为重用;更多的日志记录会被添加而不需要物理增长文件。当然还有,我们把日志捕获到备份文件,这样的话我们可以使用这个文件作为数据库恢复进程,如果我们想把TestDB数据库恢复到上一状态。
小结
在这篇文章里,我们介绍了事务日志,解释了SQL Server如何使用它来维护数据的一致性(consistency)和完整性(integrity),通过预写式日志(write-ahead logging)机制。我们也介绍了并简洁演示了,一个DBA如何捕获事务日式文件内容到备份文件,它可以被重用来恢复数据库,作为恢复过程的一部分。最后,我们强调了备份在控制事务日志文件大小的重要性。
在下一篇文章,我们会进一步看下事务日志的架构。
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!

