
自增长的聚集键值不会扩展(scale)
如何选择聚集键值的最佳实践是什么?一个好的聚集键值应该有下列属性:
- 范围小的(Narrow)
- 静态的(Static)
- 自增长的(Ever Increasing)
我们来具体看下所有这3个属性,还有在SQL Server里为什么自增长值实际上是不会扩展的。
范围小的(Narrow)
聚集键值应该i越小越好。为什么?因为它要占用空间,聚集键值也在每个非聚集索引的叶子曾作为逻辑指针。如果你的聚集键值很广,你的非聚集索引也会很大。如果你定义了非唯一非聚集索引(Non-Unique Non-Clustered Index)(基本上是这个情况),聚集键也是你非聚集索引导航结构的一部分。因此你的索引会变得很大。我们的目标是最小化我们的索引。因为我们要为此承担更多的物理存储,缓存池,这些都是SQL Server从存储缓存读取的索引页的地方。
一般我们会选择技术性键值(technical key value)(像INT/BIGINT数据类型),而不是自然键值(natural key value)。当我也看到很多长度有100 bytes甚至更长的聚集键值(包含LastName, FirstName, SocialSecurityNumber等)。相信我——你这是在浪费内存!没有必要这样做。选择一个技术性键值就可以了。
静态的(Static)
因为聚集键值在每个非聚集索引里都会复制一份,你的聚集键值应该从不改变!不然SQL Server需要经常维护,去更新执行计划里每个在你表上定义的非聚集索引。你再次引入了你不需要的额外计算。把你的CPU用在其它重要的事情上。我们都知道,自然键值是会改变的(例如LastName列,当你结婚了就会改变)。
技术性键值(像INT IDENTITY)不会改变(默认)。因此在你非聚集索引里的逻辑指针(聚集键值格式)保持稳定——永远没有必要修改他们!
自增长的(Ever Increasing)
“好”的聚集键值第3个重要属性是选择列应该给你自增长的值。为什么?因为你总是在你聚集索引的末尾增加额外记录,因此你可以避免昂贵的分页(Page Splits)(涉及到CPU周期,事务日志等问题)和索引碎片。使用像INT IDENTITY自增长值列,在99%的情况下是没有问题的,但还是有些情形,这个方法会导致严重的扩展性问题。假设你有个工作量,那里有很多不同用户用自增长聚集键值对同个表永久插入键值。想下日志/审计表(Logging/Auditing Table)。
我们来仔细看下当你在内存里读写页时,在SQL Server内部会发生什么。当SQL Server访问特定内存机构(像存储在缓存池里的页)时,这些内存访问必须被多个线程上同步。你不能在内存里并发写入同个页。当一个线程写入一个页时,其他一些线程同时就不能读这个页。另外并发编程你用互斥器(Mutexes)解决那个问题——像临界区(Critical Section)。一些代码路径是人为互斥的。闩锁(latches)用来在线程/查询间的同步。每次当你读一个页,工作线程需要获得共享锁(Shared Latch(SH)),每次当你写一个页,工作线程需要获得排它闩锁(Exclusive Latch(EX))。而且这些闩锁彼此是不兼容的。
当你进行INSERT语句时,工作线程在INSERT语句发生的页获得排它闩锁。同时没有线程可以从这个页读写。使用自增长聚集键值这个方法实际上不会扩展,因为你在你聚集索引的末尾插入你的记录。因此你的并行线程/查询在你聚集索引里同个最后页为闩锁竞争。作为一个副作用SQL Server会连续执行你的INSERT语句——一个接着一个INSERT,你就碰到了著名的最后页插入闩锁竞争(Last Page Insert Latch Contention)。我们来看下面的图片。
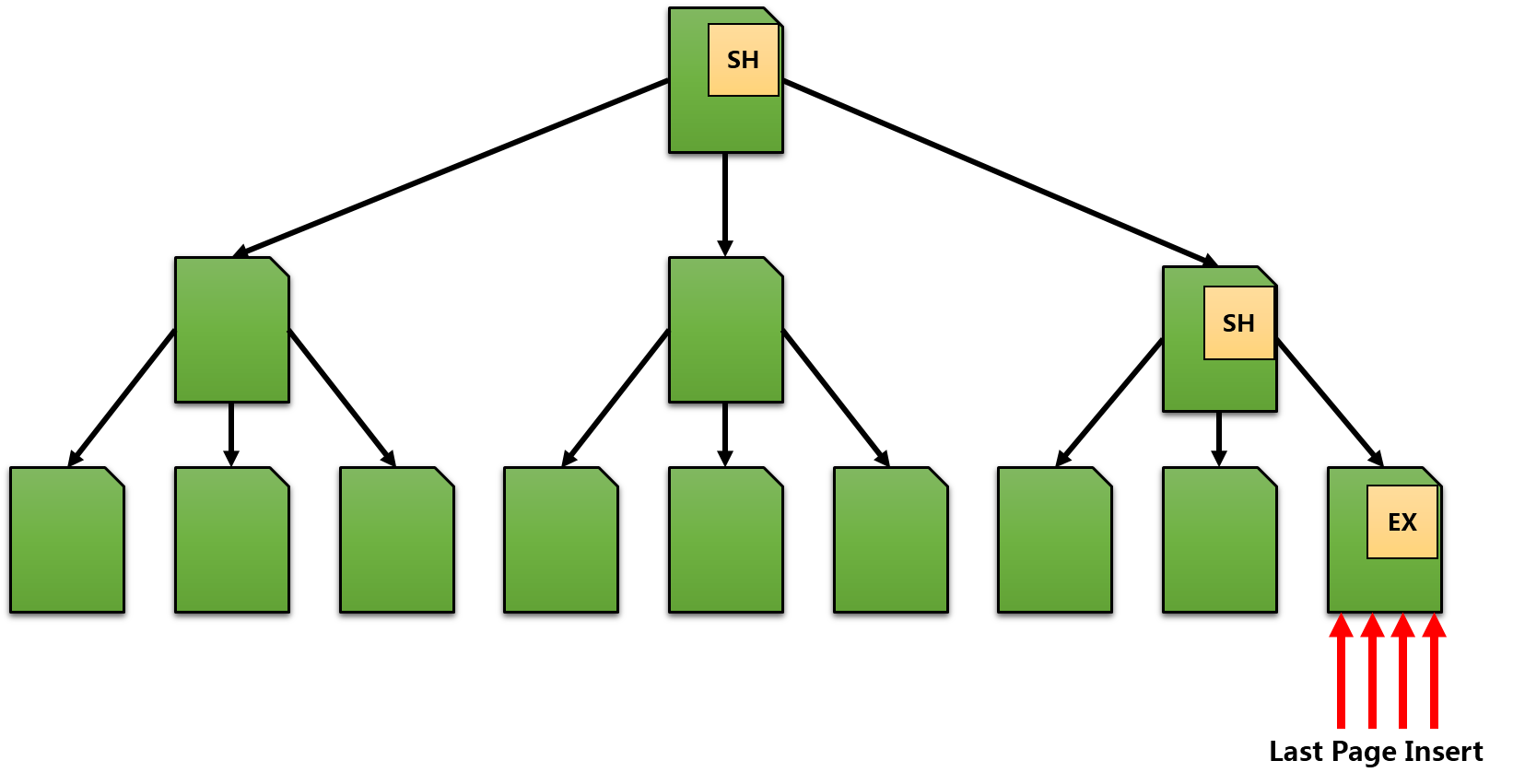
用自增长聚集键值的最佳实践,在聚集键的末尾你有一个热区。你的记录越小,这里就会有更多的竞争。如果解决那个问题?简单:把你的INSERT语句扩散到聚集索引的整个B树结果。有很多方法可以实现这个:
- 使用随机聚集键值(像UNIQUEIDENTIFIER)。但要意识到副作用:在每个非聚集索引里逻辑指针更大,页分裂问题……
- 实现哈希分区(Hash Partitioning),如果你使用企业版本的SQL Server。
- 使用SQL Server 2014里内不能优化表OLTP来剔除闩锁。
- 使用逆向索引(Reverse index),很遗憾SQL Server并不提供你像Oracle那样的内建索引。你也可以自己写一个的……
1 CREATE FUNCTION BitReverse 2 ( 3 @Input bigint 4 ) 5 RETURNS bigint 6 AS 7 BEGIN 8 DECLARE @WorkValue bigint=@Input 9 DECLARE @Result bigint=0; 10 DECLARE @Counter int=0; 11 WHILE @Counter<63 12 BEGIN 13 SET @Result=@Result*2 14 IF (@WorkValue&1)=1 15 BEGIN 16 SET @Result=@Result+1 17 SET @WorkValue=@WorkValue-1 18 END 19 SET @WorkValue=@WorkValue/2 20 SET @Counter=@Counter+1 21 END 22 23 RETURN @Result 24 25 END
小结
使用像INT IDENTITY数据类型的范围小,静态的,自增长的聚集键值99%的情况都没问题。但在一些有大量并发INSERT语句的情况(日志/审计表(Logging/Auditing Table)),用那个方法你会碰到最后也插入闩锁竞争(Last Page Insert Latch Contention)。如果你碰到这个特定问题,你就会离开这99%的太平区域,你要保证INSERT语句散布到你的整个B树结构。基本上你就在如果将多线程散步到典型B树结构做斗争。
希望这篇文章可以帮助你从内部理解:为什么自增长聚集键值会伤及你表的扩展性。
感谢关注。
参考文章:
https://www.sqlpassion.at/archive/2014/04/15/an-ever-increasing-clustered-key-value-doesnt-scale/
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!

