

参数嗅探(Parameter Sniffing)(1/2)
这个问题会在参数话的SQL语句(例如存储过程)与SQL Server里的计划缓存机制结合的时候会出现。这个文章分为2个部分,第1部分会介绍下参数嗅探(Parameter Sniffing)的概况,第2部分我们介绍下如何解决这个问题。
什么是参数嗅探(Parameter Sniffing)
在SQL Server里当你执行参数话的SQL查询时,查询优化器会基于第一个提供的参数值编译执行计划。然后生成的执行计划在计划缓存里缓存作为后期的重用。这就是说SQL Server后续会直接重用这个计划,而不管每次你提供的不同参数值。我们需要识别2类参数值:
- 参数编译值(Compile time values)
- 参数运行值(Runtime values)
参数编译值是用于查询优化器生成物理执行计划的值。参数运行值是提供给执行计划运行的值。对于第一次执行这些值是一致的,但接下来的执行,这些值就很可能不同了。这就会带来严重的性能问题,因为执行计划只为编译值而优化的,不是为你接下来提供的不同运行值而优化。
如果你在第一次查询执行的时候提供了一个特定值,然后查询优化器选择了非聚集索引查找和书签查找运算符从你表里来获取所有查询列。这样的执行计划只对特定值有意义,非特定值的话,你的逻辑读数就会很高,SQL Server会选择全表扫描,忽略定义的非聚集索引。SQL Server选择这2个计划的决定点就是所谓的临界点(Tipping Point) 。
如果书签查找的计划被缓存,SQL Server就不会理会输入值,盲目重用缓存的计划。这个情况下SQL Server的保护机制就失效了,只从计划缓存里执行缓存的计划。作为副作用,你的IO成本(逻辑都)就会爆表,查询的性能就会非常糟糕。我们来演示下这个情况,下面的脚本会创建一个简单的表,在表的第2列有不平均的数据分布(就第1条值是1,剩下的1499条值都是2)。
1 -- Create a test table 2 CREATE TABLE Table1 3 ( 4 Column1 INT IDENTITY, 5 Column2 INT 6 ) 7 GO 8 9 CREATE NONCLUSTERED INDEX idx_Test ON Table1(Column2) 10 11 -- Insert 1500 records into Table1 12 INSERT INTO Table1 (Column2) VALUES (1) 13 14 SELECT TOP 1499 IDENTITY(INT, 1, 1) AS n INTO #Nums 15 FROM 16 master.dbo.syscolumns sc1 17 18 INSERT INTO Table1 (Column2) 19 SELECT 2 FROM #nums 20 DROP TABLE #nums 21 GO
基于这个不平均的数据分布和临界点,对于同个逻辑查询会有2个不同的执行计划,点击工具栏的 显示包含实际的执行计划:
显示包含实际的执行计划:
1 SELECT * FROM dbo.Table1 WHERE Column2=1 2 SELECT * FROM dbo.Table1 WHERE Column2=2

现在当你创建一个存储过程时,查询优化器会根据第一次提供的参数值生成执行计划,然后在接下来的执行中就会盲目重用了。
1 -- Create a new stored procedure for data retrieval 2 CREATE PROCEDURE RetrieveData 3 ( 4 @Col2Value INT 5 ) 6 AS 7 SELECT * FROM Table1 8 WHERE Column2 = @Col2Value 9 GO
1 SET STATISTICS IO ON 2 EXEC dbo.RetrieveData @Col2Value = 1 -- int 3 EXEC dbo.RetrieveData @Col2Value = 2 -- int
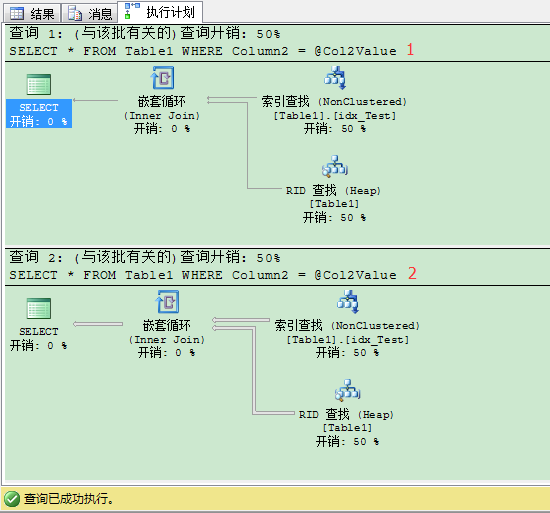
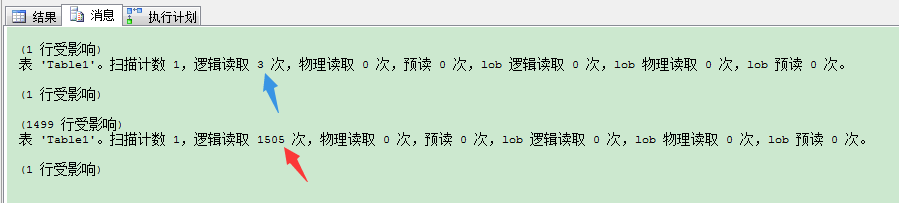
现在当你用1值运行存储过程时,只返回1条记录,查询优化器在执行计划里选择书签查找。查询只产生3个逻辑读。但是当你用2值运行存储过程时,缓存的计划被重用,书签查找反复执行1499次。每条记录上都执行!查询现在产生了1505个逻辑读。这和刚才的执行完全不同。当你看查看2值里执行计划里,SELECT运算符的属性时,在参数列表里你可以看到:
如你所见它们是不一样的,参数编译值是1,参数运行值是2。这就是说在你面前的执行都是基于参数值1而优化的,但实际上你传给存储过程的参数值是2。这就是SQL Server里的参数嗅探(Parameter Sniffing)问题。
小结
如你所见,在SQL Server里很容易碰到这个问题。每次你使用参数话的SQL查询(像在存储过程里),当表数据分布不平均,提供的非聚集索引没有覆盖到查询列时,你就会碰到这个问题。这里我们只介绍了这个问题,下篇文章我会向你展示如何处理这个问题,即SQL Server向你提供了哪些方案来解决这个问题。
参考文章:
https://www.sqlpassion.at/archive/2014/10/20/parameter-sniffing-part-1/
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!

