
理解统计信息(4/6):自动更新统计信息的阀值——人为更新统计信息的重要性
在理解统计信息(3/6):谁创建和管理统计信息?在性能调优中,统计信息的作用里我们讨论了统计信息的自动创建和自动更新。我们真的需要人为维护统计信息来保持性能最优?答案是肯定的,这取决与你的工作量。SQL Server只在达到阀限值时进行统计信息的自动更新。当大量的Insert/Update/Delete操作发生时,内建的自动更新统计信息不能持续保证性能的最优。
经过一系列的Insert/Update/Delete后,统计信息可能不会是最新。如果SQL Server查询优化器在表里需要指定列的统计信息,自上次统计信息创建或更新后经历了实质的更新活动,SQL Server会通过采样列值自动更新统计信息(通过自动更新统计信息)。统计信息的自动更新由查询优化器或编译好的计划执行来触发,它只涉及到查询里引用到的各个列。如果自动异步更新统计信息是停用的话,统计信息会在查询编译前更新,启用的话是在查询编译后更新。当统计信息是异步更新时,受益于触发更新的查询使用老的统计信息。对一些工作量来说,这可以提供更可预估的响应时间,尤其是那些大表上的短时间运行的查询。
当一个查询首次编译完成,如果优化器需要指定对象的统计信息,这个统计信息存在的话,若已过期则自动更新统计信息。如果一个查询被执行且它的计划在缓存里,计划依赖的统计信息会被检查是否过期,如果过期,计划会在缓冲中移除,在查询的重编译时,统计信息会被更新。如果计划依赖的任何统计信息被更新的话,计划都会从缓存中移除。
SQL Server 2008基于列修改的计数器(colmodctrs)来决定是否更新统计信息:
在下列情况下,统计信息对象被认为过期:
如果在常规表上定义的统计信息,被认为过期的话,那么:
- 表的大小从0行变成了大于0行(测试1)
- 当统计信息收集时,表的行数为500或更少,统计的第一列对象的计数器,自改变为大于500时(测试2)。
- 当统计信息收集时,表的行数大于500时,统计的第一列对象的计数器,受表里超过500 +20%的行数而改变(测试3)。
上述描述来自微软的MSDN,具体参见Statistics Used by the Query Optimizer in Microsoft SQL Server 2008。
前2个条件还是相当好的,但第3个条件在处理大表时,有些时候阀值会很高,但对统计信息更新还是无效。例如有个表有100000条记录,只有在200500条件记录被修改后(update/insert),对于触发自动更新还是无效的阀值。
我们来看个例子。
1 USE StatisticsDB 2 GO 3 4 DROP TABLE SalesOrderDetail 5 SELECT * INTO SalesOrderDetail FROM AdventureWorks2008r2.sales.SalesOrderDetail 6 CREATE INDEX ix_ProductID ON SalesOrderDetail(ProductID) 7 SET STATISTICS IO ON 8 SELECT * FROM SalesOrderDetail WHERE ProductID=725
我们创建了SalesOrderDetail表的副本,并在上面创建非聚集索引,我们看下最后SELECT查询的执行计划,点击工具栏的 显示包含实际的执行计划。
显示包含实际的执行计划。
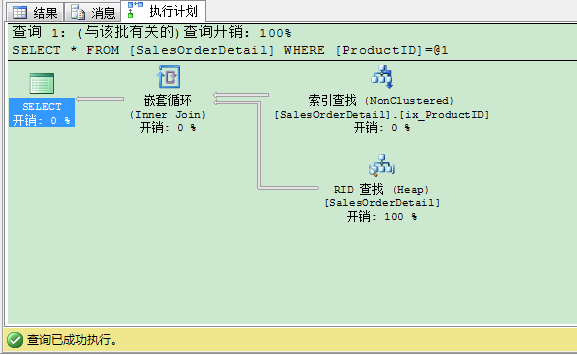

优化器选择了索引查找和书签查找操作作为优化的计划,完成这个操作需要377个逻辑读。
salesOrderDetail 表有121317条记录,上述第3个条件如果要使统计信息无效的话,121317的20% =24263+500=24763条记录需要被修改,我们用下列语句只更新5000条记录,再次看看查询的执行计划,点击工具栏的显示包含实际的执行计划。
1 SET ROWCOUNT 5000 2 UPDATE SalesOrderDetail SET ProductID=725 WHERE ProductID<>725 3 SET ROWCOUNT 0 4 SET STATISTICS IO ON 5 SELECT * FROM SalesOrderDetail WHERE ProductID=725
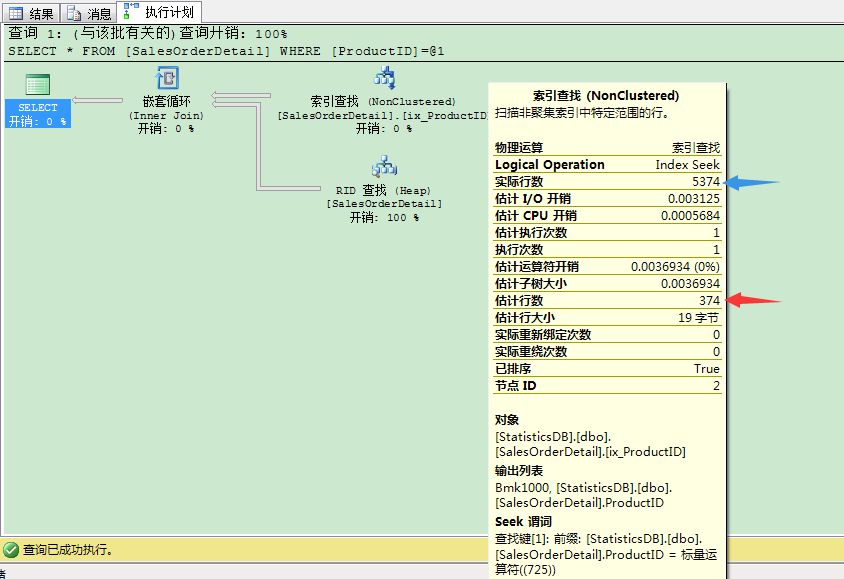

执行计划里估计行数是374,这是基于上次更新操作收集的统计信息。优化器基于统计信息,选择了索引查找和书签查找作为最优计划。SELECT操作进行5390逻辑读来完成这个操作。
下一步,我们用producid值为725来更新19762条记录。实际上我们更新24762条记录(包含上一步5000条更新的记录),比使统计信息无效的更新的记录(24763)少1条。
1 SET ROWCOUNT 19762 2 UPDATE SalesOrderDetail SET ProductID=725 WHERE ProductID<>725 3 SET ROWCOUNT 0 4 SET STATISTICS IO ON 5 SELECT * FROM SalesOrderDetail WHERE ProductID=725
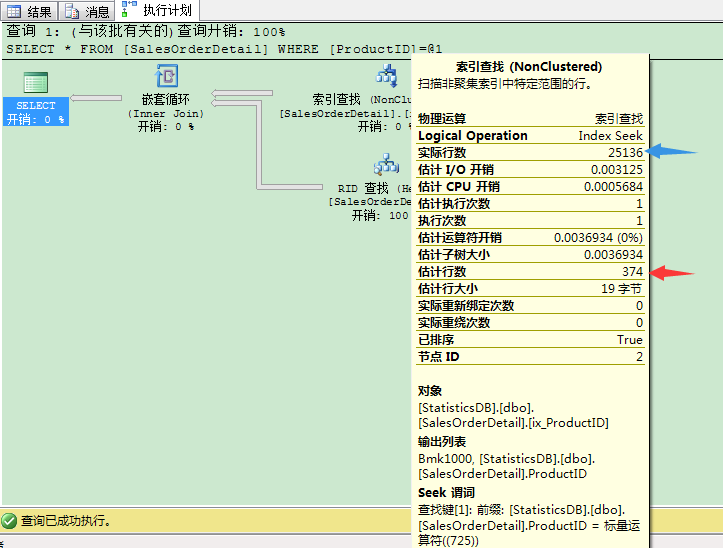

执行计划里估计行数是374,这是基于上次更新操作收集的统计信息。优化器基于统计信息,选择了索引查找和书签查找作为最优计划。完成这个操作需要25206个逻辑读。
现在我们更新再多一条记录使统计信息无效。
1 SET ROWCOUNT 1 2 UPDATE SalesOrderDetail SET ProductID=725 WHERE ProductID<>725 3 SET ROWCOUNT 0 4 SET STATISTICS IO ON 5 SELECT * FROM SalesOrderDetail WHERE ProductID=725

(这里我跌了个跟头,在SQL SERVER 2008R2里首次执行,始终是下列结果:
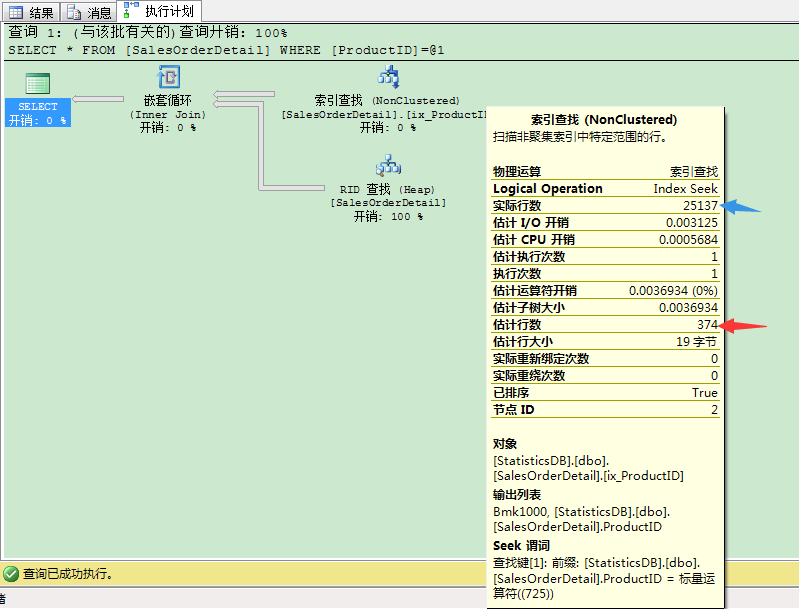

回家吃饭还在思考这个问题,一想原因,应该是自动创建统计信息和自动更新统计信息被停用的原因(上篇文章理解统计信息(3/6):谁创建和管理统计信息?在性能调优中,统计信息的作用 代码执行后未还原为默认设置),在数据库属性里一看,果然是False状态,赶紧用下列语句启用,出现的问题立马消失!
1 ALTER DATABASE StatisticsDB SET AUTO_CREATE_STATISTICS ON 2 ALTER DATABASE StatisticsDB SET AUTO_UPDATE_STATISTICS ON
看来计算机是最诚实可靠的,即使计算机犯了错,也是因为人犯错造成的! )
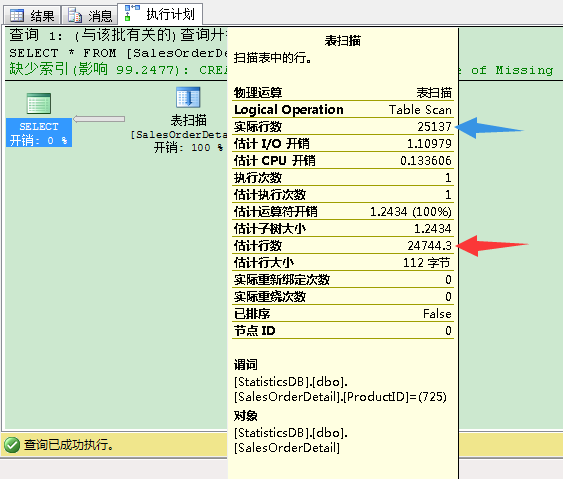
和我们预期的一样,SELECT语句触发了自动更新统计信息,计划中的估计行数和实际行数已经非常接近了。这可以帮助优化器选择更好的执行计划。优化器选择了表扫描而不是索引查找和书签查找。SELECT操作只进行了1495个逻辑读来选取25137条记录,比起25212个逻辑读才选择2516条记录。在第一步,我们只更新了5000条记录,如果统计信息在那个时候更新的话,优化器可能会选择表扫描作为最优计划而不是索引查找和书签查找。那样的话就可以只用1495个逻辑读代替5390个逻辑读来完成操作,这样就会好很多。
从这个例子我们可以清楚看到,对于自动更新统计信息的阀值对于获得最优性能还是不够好。对于大表来说会更糟。我们就需要人为去更新统计信息用来保证长须的最佳性能,当然更新的频率要看具体的工作量。
在进行大量DML操作后,统计信息都会过期,在查询计划访问统计信息前,统计信息都不会自动更新。更清楚的说,SQL Server会在下列情况自动更新统计信息:
- 查询第一次编译,计划使用到的统计信息已经过期
- 查询已有存在的查询计划,但计划中的统计信息已经过期。
参考文章:
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步