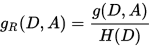决策树公式
决策树公式
1. 熵
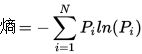
Gini系数
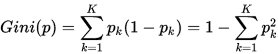
1.1数据表
| outlook | temperature | humidity | windy | play |
|---|---|---|---|---|
| sunny | hot | high | FALSE | no |
| sunny | hot | high | TRUE | no |
| overcast | hot | high | FALSE | yes |
| rainy | mild | high | FALSE | yes |
| rainy | cool | normal | FALSE | yes |
| rainy | cool | normal | TRUE | no |
| overcast | cool | normal | TRUE | yes |
| sunny | mild | high | FALSE | no |
| sunny | cool | normal | FALSE | yes |
| rainy | mild | normal | FALSE | yes |
| sunny | mild | normal | TRUE | yes |
| overcast | mild | high | TRUE | yes |
| overcast | hot | normal | FALSE | yes |
| rainy | mild | high | TRUE | no |
play的熵:
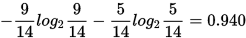
outlook的信息熵:
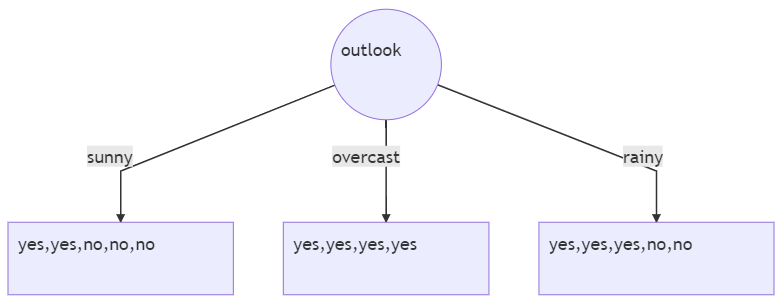
- outlook=sunny时,2/5打球概率,3/5打球概率. entropy=0.971
- outlook=overcast,entropy=0
- outlook=rainy时,entropy=0.971
5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971=0.693
信息增溢gain(outlook)=0.940-0.693=0.247
同样计算出gain(temperature)=0.029
gain(humidity)=0.152
gain(windy)=0.048
gain(outlook)最大(信息熵下降最快),所以决策树根节点选outlook
2.经验熵H(D)
为了计算熵,我们需要计算所有类别所有可能值所包含的信息期望值,p(xi)是选择该分类的概率:
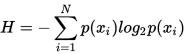
其中,n为分类数目,熵越大,随机变量的不确定性就越大。
设有K个类Ck,k = 1,2,3,···,K,|Ck|为属于类Ck的样本个数,这经验熵公式可以写为:
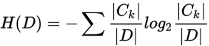
outlook特征的熵
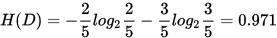
3.条件熵
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵(conditional entropy) H(Y|X),定义X给定条件下Y的条件概率分布的熵对X的数学期望:
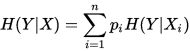
其中,pi = P(X=xi)
4.信息增益
信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
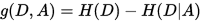
5.信息增益比
特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D的经验熵之比: