
1、修饰符
修饰符 | 描述 |
i | 完成不区分大小写的搜索 |
g | 查找所有出现(all occurrences,完成全局搜索) |
m | 将一个字符串视为多行(m就标识多multiple)。默认情况下,^和$字符串匹配字符串中的最开始和最末尾。使用m修饰符将使^和$匹配字符串中每行的开始 |
s | 将一个字符串视为一行,忽略其中的所有换行符;他与m修饰符正好相反 |
X | 忽略正则表达式中的空白和注释 |
U | 第一次匹配后停止,许多量词很"贪婪",将尽可能的完成匹配。而不是在第一次匹配后停止。利用这个修饰符,可以让它们"不再贪婪" |
2、元字符
元字符 | 描述 |
\A | 只匹配字符串开头 |
\b | 匹配单词边界 |
\B | 匹配除单词边界之外的任意字符 |
\d | 匹配数字字符,它与[0-9]相同 |
\D | 匹配非数字字符 |
\s | 匹配空白字符 |
\S | 匹配非空白字符 |
[] | 包围一个字符类。 |
() | 包围一个字符分组或定义一个反引用 |
$ | 匹配行尾 |
^ | 匹配行首 |
. | 匹配除换行之外的任何字符 |
\ | 引出下一个元字符 |
\w | 匹配任何只包含下划线、字母、数字的字符串[a-zA-Z0-9]相同 |
\W | 匹配没有下划线和字符数字字符的字符串 |
3、函数
/*
* 搜索字符串
* 搜索数组中的所有元素,返回由与某个模式匹配的所有元素组成的数组
* array preg_grep(string psttern,array input[,flag])
*/
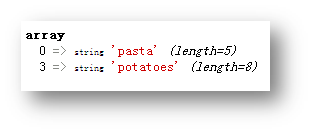
$foods = array ("pasta", "steak", "fish", "potatoes" );
var_dump ( preg_grep ( "/^p/", $foods ) );
/*
* 搜索模式
* 在字符串中搜索模式,如果存在返回TRUE否则返回FALSE
* boolean preg_match(string pattern,string string[,array matches[,int flags[,int offset]]])
*/
$line = "Vim is the greatest word processor ever created!";
if (preg_match ( "/\bVim\b/i", $line, $match )) {
var_dump ( $match );
}
/*
* 匹配模式的所有出现
* 在字符串中匹配模式的所有出现,以便通过可选的输入参数order所指定的顺序
* int preg_match_all(string pattern,string string,array pattern-array[,int order])
*/
$userinfo = "Name:<b>Zeev Suraski</b><br>Title:<b>PHP Curu</b>";
preg_match_all ( "/<b>(.*)<\/b>/U", $userinfo, $pat_array );
var_dump ( $pat_array );

/*
* 界定特殊的正则表达式字符
* 在每个对于正则表达式语法而言有特殊含义的字符前插入一个反斜线。这些特殊字符包括$^*()+={}|\\:[]<>
* string preg_quote(string str[,string delimitrer])
*/
$text = "Tickets for the bout are going for $500.";
echo preg_quote ( $text );

/*
* 替换模式的所有出现
* mixed preg_replace(mixed pattern,mixed replacement,mixed str[,int limit])
*/
$text = "This is a link to http://www.wk.com/.";
echo preg_replace ( "/http:\/\/(.*)\//", "<a href=\"\${0}\">\${0}</a>", $text );

/*
* 创建定制的替换函数
* mixed preg_replace_callback(mixed pattern,callback callback,mixed str[,int limit])
*/
function acronym($matches) {
$acronyms = array(
'WWW' => 'World Wide Web',
'IRS' => 'Internal Revenue Service',
'PDF' => 'Portable Document Format'
);
if(isset($acronyms[$matches[1]]))
return $matches[1] . "(" .$acronyms[$matches[1]] . ")";
else
return $matches[1];
}
$text = "The <acronym>ISR</acronym> offsers tax form in <acronym>PDF</acronym> format on the <acronym>WWW</acronym>.";
$newtext=preg_replace_callback("/<acronym>(.*)<\/acronym>/U", 'acronym', $text);
var_dump($newtext);

/*
* 以不区分大小写的方式将字符串划分为不同的元素
* array preg_split(string pattern,string string[,int limit[,int flags]])
*/
$delimitedText = "Jason++Gilmore+++++++Columbus+++OH";
$fields = preg_split ( "/\+{1,}/", $delimitedText );
var_dump ( $fields );

