高斯混合模型(理论+opencv实现)
查资料的时候看了一个不文明的事情,转载别人的东西而不标注出处,结果原创无人知晓,转载很多人评论~~标注了转载而不说出处这样的人有点可耻!
写在前面:
Gaussian Mixture Model (GMM)。事实上,GMM 和 k-means 很像,不过 GMM 是学习出一些概率密度函数来(所以 GMM 除了用在 clustering 上之外,还经常被用于 density estimation ),简单地说,k-means 的结果是每个数据点被 assign 到其中某一个 cluster 了,而 GMM 则给出这些数据点被 assign 到每个 cluster 的概率,又称作 soft assignment 。
得出一个概率有很多好处,因为它的信息量比简单的一个结果要多,比如,我可以把这个概率转换为一个 score ,表示算法对自己得出的这个结果的把握。也许我可以对同一个任务,用多个方法得到结果,最后选取“把握”最大的那个结果;另一个很常见的方法是在诸如疾病诊断之类的场所,机器对于那些很容易分辨的情况(患病或者不患病的概率很高)可以自动区分,而对于那种很难分辨的情况,比如,49% 的概率患病,51% 的概率正常,如果仅仅简单地使用 50% 的阈值将患者诊断为“正常”的话,风险是非常大的,因此,在机器对自己的结果把握很小的情况下,会“拒绝发表评论”,而把这个任务留给有经验的医生去解决。
准备阶段
1.协方差
注:内容是http://pinkyjie.com/2010/08/31/covariance/(讲的太好了,一下子就理解了,对下面的高斯混合模型没啥帮助,我以为会用到的,哈哈)
统计学的基本概念
学过概率统计的孩子都知道,统计里最基本的概念就是样本的均值,方差,或者再加个标准差。首先我们给你一个含有n个样本的集合X={X1,…,Xn}X={X1,…,Xn},依次给出这些概念的公式描述,
这些高中学过数学的孩子都应该知道吧,一带而过。
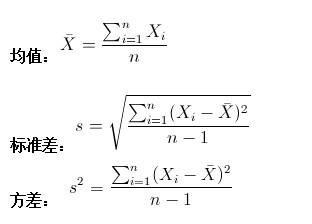
很显然,均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,而标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”。而方差则仅仅是标准差的平方。
为什么需要协方差?
上面几个统计量看似已经描述的差不多了,但我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子欢迎程度是否存在一些联系啊,嘿嘿~协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:
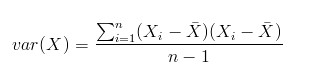
来度量各个维度偏离其均值的程度,标准差可以这么来定义:
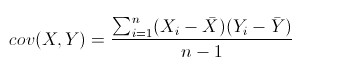
协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐就越受女孩子欢迎,嘿嘿,那必须的~结果为负值就说明负相关的,越猥琐女孩子越讨厌,可能吗?如果为0,也是就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:
协方差多了就是协方差矩阵
上一节提到的猥琐和受欢迎的问题是典型二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算n!(n−2)!∗2n!(n−2)!∗2个协方差,那自然而然的我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
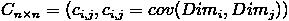
这个定义还是很容易理解的,我们可以举一个简单的三维的例子,假设数据集有{x,y,z}{x,y,z}三个维度,则协方差矩阵为

可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
Matlab协方差实战
上面涉及的内容都比较容易,协方差矩阵似乎也很简单,但实战起来就很容易让人迷茫了。必须要明确一点,### 协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。这个我将结合下面的例子说明,以下的演示将使用Matlab,为了说明计算原理,不直接调用Matlab的cov函数。
首先,随机产生一个10*3维的整数矩阵作为样本集,10为样本的个数,3为样本的维数。
|
1
|
MySample = fix(rand(10,3)*50)
|

根据公式,计算协方差需要计算均值,那是按行计算均值还是按列呢,我一开始就老是困扰这个问题。前面我们也特别强调了,协方差矩阵是计算不同维度间的协方差,要时刻牢记这一点。样本矩阵的每行是一个样本,每列为一个维度,所以我们要### 按列计算均值。为了描述方便,我们先将三个维度的数据分别赋值:
|
1
2
3
|
dim1 = MySample(:,1);
dim2 = MySample(:,2);
dim3 = MySample(:,3);
|
计算dim1与dim2,dim1与dim3,dim2与dim3的协方差:
|
1
2
3
|
sum( (dim1-mean(dim1)) .* (dim2-mean(dim2)) ) / ( size(MySample,1)-1 ) % 得到 74.5333
sum( (dim1-mean(dim1)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -10.0889
sum( (dim2-mean(dim2)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -106.4000
|
搞清楚了这个后面就容易多了,协方差矩阵的对角线就是各个维度上的方差,下面我们依次计算:
|
1
2
3
|
std(dim1)^2 % 得到 108.3222
std(dim2)^2 % 得到 260.6222
std(dim3)^2 % 得到 94.1778
|
这样,我们就得到了计算协方差矩阵所需要的所有数据,调用Matlab自带的cov函数进行验证:
|
1
|
cov(MySample)
|

把我们计算的数据对号入座,是不是一摸一样?
Update:
今天突然发现,原来协方差矩阵还可以这样计算,先让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0,然后直接用新的到的样本矩阵乘上它的转置,然后除以(N-1)即可。其实这种方法也是由前面的公式通道而来,只不过理解起来不是很直观,但在抽象的公式推导时还是很常用的!同样给出Matlab代码实现:
|
1
2
|
X = MySample - repmat(mean(MySample),10,1); % 中心化样本矩阵,使各维度均值为0
C = (X'*X)./(size(X,1)-1);
|
总结
理解协方差矩阵的关键就在于牢记它计算的是不同维度之间的协方差,而不是不同样本之间,拿到一个样本矩阵,我们最先要明确的就是一行是一个样本还是一个维度,心中明确这个整个计算过程就会顺流而下,这么一来就不会迷茫了~
2.高斯函数(模型)
记得上次看高斯函数还是在高斯滤波和双边滤波的时候,现在再来提到都已经忘得差不多了。。。。
知道下面几个公式就可以了:
高斯一维函数:

高斯概率分布函数:

3.EM算法
本来打算在这里叙述的,感觉内容有点多,而且以后还会用到这个算法,还是另外开一篇博客叙述:http://www.cnblogs.com/wjy-lulu/p/7010258.html
4.混合高斯模型
注释:这里是http://blog.sina.com.cn/s/blog_54d460e40101ec00.html博客的内容,看了很多篇文章,感觉还是这篇讲的好,不是很深入但是把原理讲的很清楚。
如果理解了我另一篇博客的EM算法,看这个混合高斯模型很简单了。。。。
高斯混合模型--GMM(Gaussian Mixture Model)
统计学习的模型有两种,一种是概率模型,一种是非概率模型。
所谓概率模型,是指训练模型的形式是P(Y|X)。输入是X,输出是Y,训练后模型得到的输出不是一个具体的值,而是一系列的概率值(对应于分类问题来说,就是输入X对应于各个不同Y(类)的概率),然后我们选取概率最大的那个类作为判决对象(软分类--soft assignment)。所谓非概率模型,是指训练模型是一个决策函数Y=f(X),输入数据X是多少就可以投影得到唯一的Y,即判决结果(硬分类--hard assignment)。
所谓混合高斯模型(GMM)就是指对样本的概率密度分布进行估计,而估计采用的模型(训练模型)是几个高斯模型的加权和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
从中心极限定理的角度上看,把混合模型假设为高斯的是比较合理的,当然,也可以根据实际数据定义成任何分布的Mixture Model,不过定义为高斯的在计算上有一些方便之处,另外,理论上可以通过增加Model的个数,用GMM近似任何概率分布。
混合高斯模型的定义为:
")
其中K 为模型的个数;πk为第k个高斯的权重;p(x / k) 则为第k个高斯概率密度,其均值为μk,方差为σk。对此概率密度的估计就是要求出πk、μk 和σk 各个变量。当求出p(x )的表达式后,求和式的各项的结果就分别代表样本x 属于各个类的概率。
在做参数估计的时候,常采用的是最大似然方法。最大似然法就是使样本点在估计的概率密度函数上的概率值最大。由于概率值一般都很小,N 很大的时候, 连乘的结果非常小,容易造成浮点数下溢。所以我们通常取log,将目标改写成:
")
也就是最大化对数似然函数,完整形式为:
")
一般用来做参数估计的时候,我们都是通过对待求变量进行求导来求极值,在上式中,log函数中又有求和,你想用求导的方法算的话方程组将会非常复杂,没有闭合解。可以采用的求解方法是EM算法——将求解分为两步:第一步,假设知道各个高斯模型的参数(可以初始化一个,或者基于上一步迭代结果),去估计每个高斯模型的权值;第二步,基于估计的权值,回过头再去确定高斯模型的参数。重复这两个步骤,直到波动很小,近似达到极值(注意这里是极值不是最值,EM算法会陷入局部最优)。具体表达如下:
注释:这是需要求得参数有两类:(每个模型权重W)(每个模型的参数),这是按照EM思想,首先假定(参数)把每个样本点分类计算(权重),然后通过分类的样本点计算新的(参数),接着对比假设参数和计算的参数是否符合精度,符合结束,不符合就继续上面的操作去迭代。
A、(E step)
对于第i个样本xi 来说,它由第k 个model 生成的概率为:
")
在这一步,假设高斯模型的参数和是已知的(由上一步迭代而来或由初始值决定)。
B、(M step)
C、重复上述两步骤直到算法收敛。
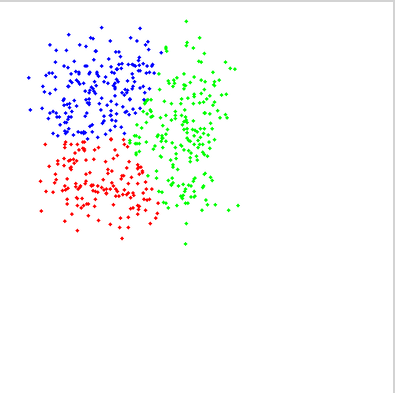
聚类实例:
1 #include <opencv2/opencv.hpp> 2 #include <iostream> 3 4 using namespace cv; 5 using namespace std; 6 7 int main(int argc, char** argv) { 8 Mat img(500, 500, CV_8UC3); 9 RNG rng(12345); 10 const int Max_nCluster = 5; 11 Scalar colorTab[] = { 12 Scalar(0, 0, 255), 13 Scalar(0, 255, 0), 14 Scalar(255, 0, 0), 15 Scalar(0, 255, 255), 16 Scalar(255, 0, 255) 17 }; 18 //int numCluster = rng.uniform(2, Max_nCluster + 1);//随机类数 19 int numCluster = 3; 20 int sampleCount = rng.uniform(5, 1000);//样本点数量 21 Mat matPoints(sampleCount, 2, CV_64FC1);//样本点矩阵:sampleCount X 2 22 Mat labels; 23 Mat centers; 24 // 生成随机数 25 for (int k = 0; k < numCluster; k++) { 26 Point center;//随机产生中心点 27 center.x = rng.uniform(0, img.cols); 28 center.y = rng.uniform(0, img.rows); 29 Mat pointChunk = matPoints.rowRange(k*sampleCount / numCluster, 30 (k + 1)*sampleCount / numCluster); 31 //-----符合高斯分布的随机高斯 32 rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y, 0, 0), Scalar(img.cols*0.05, img.rows*0.05, 0, 0)); 33 } 34 randShuffle(matPoints, 1, &rng);//打乱高斯生成的数据点顺序 35 // EM Cluster Train 36 Ptr<ml::EM> em_model = ml::EM::create(); 37 em_model->setClustersNumber(numCluster); 38 em_model->setCovarianceMatrixType(ml::EM::COV_MAT_SPHERICAL); 39 em_model->setTermCriteria(TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 100, 0.1)); 40 em_model->trainEM(matPoints, noArray(), labels, noArray()); 41 42 // 用不同颜色显示分类 43 img = Scalar::all(255); 44 for (int i = 0; i < sampleCount; i++) { 45 int index = labels.at<int>(i); 46 Point p = Point(matPoints.at<double>(i,0), matPoints.at<double>(i,1)); 47 circle(img, p, 2, colorTab[index], -1, 8); 48 } 49 // classify every image pixels 50 Mat sample(1, 2, CV_32FC1); 51 for (int row = 0; row < img.rows; row++) { 52 for (int col = 0; col < img.cols; col++) { 53 sample.at<float>(0) = (float)col; 54 sample.at<float>(1) = (float)row; 55 int response = cvRound(em_model->predict2(sample, noArray())[1]); 56 Scalar c = colorTab[response]; 57 circle(img, Point(col, row), 1, c*0.75, -1); 58 } 59 } 60 imshow("Demo", img); 61 waitKey(0); 62 return 0; 63 }

图像分割:
1 #include <opencv2/opencv.hpp> 2 #include <iostream> 3 4 using namespace cv; 5 using namespace cv::ml; 6 using namespace std; 7 8 int main(int argc, char** argv) { 9 Mat src = imread("toux.jpg"); 10 if (src.empty()) { 11 printf("could not load iamge...\n"); 12 return -1; 13 } 14 char* inputWinTitle = "input image"; 15 namedWindow(inputWinTitle, CV_WINDOW_AUTOSIZE); 16 imshow(inputWinTitle, src); 17 18 // 初始化 19 int numCluster = 3; 20 const Scalar colors[] = { 21 Scalar(255, 0, 0), 22 Scalar(0, 255, 0), 23 Scalar(0, 0, 255), 24 Scalar(255, 255, 0) 25 }; 26 27 int width = src.cols; 28 int height = src.rows; 29 int dims = src.channels(); 30 int nsamples = width*height; 31 Mat points(nsamples, dims, CV_64FC1); 32 Mat labels; 33 Mat result = Mat::zeros(src.size(), CV_8UC3); 34 35 // 图像RGB像素数据转换为样本数据 36 int index = 0; 37 for (int row = 0; row < height; row++) { 38 for (int col = 0; col < width; col++) { 39 index = row*width + col; 40 Vec3b rgb = src.at<Vec3b>(row, col); 41 points.at<double>(index, 0) = static_cast<int>(rgb[0]); 42 points.at<double>(index, 1) = static_cast<int>(rgb[1]); 43 points.at<double>(index, 2) = static_cast<int>(rgb[2]); 44 } 45 } 46 47 // EM Cluster Train 48 Ptr<EM> em_model = EM::create(); 49 em_model->setClustersNumber(numCluster); 50 em_model->setCovarianceMatrixType(EM::COV_MAT_SPHERICAL); 51 em_model->setTermCriteria(TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 100, 0.1)); 52 em_model->trainEM(points, noArray(), labels, noArray()); 53 54 // 对每个像素标记颜色与显示 55 Mat sample(1, dims, CV_64FC1);// 56 double time = getTickCount(); 57 int r = 0, g = 0, b = 0; 58 for (int row = 0; row < height; row++) { 59 for (int col = 0; col < width; col++) { 60 index = row*width + col; 61 62 b = src.at<Vec3b>(row, col)[0]; 63 g = src.at<Vec3b>(row, col)[1]; 64 r = src.at<Vec3b>(row, col)[2]; 65 sample.at<double>(0, 0) = static_cast<double>(b); 66 sample.at<double>(0, 1) = static_cast<double>(g); 67 sample.at<double>(0, 2) = static_cast<double>(r); 68 int response = cvRound(em_model->predict2(sample, noArray())[1]); 69 Scalar c = colors[response]; 70 result.at<Vec3b>(row, col)[0] = c[0]; 71 result.at<Vec3b>(row, col)[1] = c[1]; 72 result.at<Vec3b>(row, col)[2] = c[2]; 73 } 74 } 75 printf("execution time(ms) : %.2f\n", (getTickCount() - time) / getTickFrequency() * 1000); 76 imshow("EM-Segmentation", result); 77 78 waitKey(0); 79 return 0; 80 }


参考:
http://www.mamicode.com/info-detail-466443.html(用大白文叙述GMM,娱乐的看看还好)
http://blog.pluskid.org/?p=39(讲的很好)
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html(高斯混合模型的EM算法推导公式,感兴趣可以看看,反正我没看)
代码参考贾志刚老师的资料,他的代码有的不行,自己改了一下就可以了。
-------------------------------------------
个性签名:衣带渐宽终不悔,为伊消得人憔悴!
如果觉得这篇文章对你有小小的帮助的话,记得关注再下的公众号,同时在右下角点个“推荐”哦,博主在此感谢!


