


Hadoop集群搭建
最近通过网上的视频学习了Hadoop的知识,学的比较琐碎,所以在这里做一个归纳、整理。
一、linux虚拟机的安装
1.虚拟机用的是VMWare12,这个版本只能安装在64位系统里,具体安装过程没什么好说的。
2.linux安装,我用的是CentOS-6.5-x86_64.minimal.iso
a.安装选择的是自定义的安装模式——稍后安装操作系统——网络选择NAT模式,其余的配置都按照默认的来就行了
b.到了disc found界面选择skip,然后一路默认,选择时区什么的
c.到了磁盘分区的界面,选择最后一个“Create Custom Layout”,然后点击create(两次)进入目录添加界面,给/boot路径(mount point)分配200MB,给SWAP(File System Type)分配2048MB,剩下的全部分给/
二、基本配置
1.ip配置:linux系统的ip在/etc/sysconfig/network-scripts/ifcfg-eth0(具体看是第几块网卡)。配置如下,其中IPADDR要根据NAT的虚拟网卡地址来设置。
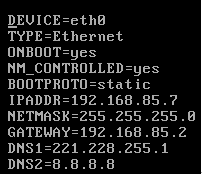
2.接着拍快照,并通过快照再克隆3个虚拟机,克隆的方法选“链接克隆”。接着去新创建的虚拟机配置ip。然后在4个虚拟机上分别把/etc/udev/rules.d/70-persistent-net.rules文件删掉,因为这个文件会把MAC地址和ip绑定,造成MAC地址重复。
3.修改host:在/etc/hosts文件添加地址解析,相当于Windows中C:\Windows\System32\drivers\etc\hosts文件。
4.设置防火墙开机不启动:我用的是命令行模式,启动级别是3。所以运行chkconfig --level 3 iptables off。
5.添加信任关系:即让4个节点之间互相通信而不需要输入密码。首先在4个节点上分别运行ssh-keygen,生成秘钥。然后创建authorized_keys,/home/username/.ssh/id_rsa.pub里边的内容复制进去。这里不建议用vi命令编辑,用重定向比较好。我用vi命令编辑以后访问还是需要密码,文件权限什么的检查都没有问题。最后才知道是vi的时候添加了换行,郁闷了很久。最好是用ssh-copy-id XXX,把当前节点的公钥复制给XXX(这个命令会自动创建authorized_keys文件)。
6.添加环境变量:在/etc/profile里把java、hadoop、zookeeper的一起添加好。保存退出以后要source /etc/profile让环境变量生效。

三、软件安装
1.安装jdk1.8,我用的是解压安装。安装成功后,并且前面的环境变量已经配置成功。运行jps会看到jps的进程。
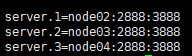
2.安装hadoop3.1.1、zookeeper-3.4.5:同样是解压安装,不赘述。zookeeper需要配置conf/zoo.cfg如下:
四、参数配置
我采用的是HA高可用的配置,一共需要配置6个文件
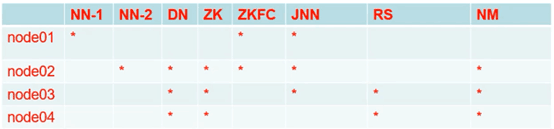
1.hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.nameservices</name> <value>bbxcluster</value> </property> <property> <name>dfs.ha.namenodes.bbxcluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.bbxcluster.nn1</name> <value>node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.bbxcluster.nn2</name> <value>node02:8020</value> </property> <property> <name>dfs.namenode.http-address.bbxcluster.nn1</name> <value>node01:9870</value> </property> <property> <name>dfs.namenode.http-address.bbxcluster.nn2</name> <value>node02:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node01:8485;node02:8485;node03:8485/bbxcluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.bbxcluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/hadoop/ha/journalnode</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
2.core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://bbxcluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop/ha</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node02:2181,node03:2181,node04:2181</value> </property>
3.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_191
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4.works
node02
node03
node04
5.yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>bbxcluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node04</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node03:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node04:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node02:2181,node03:2181,node04:2181</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> <description>Ratio between virtual memory to physical memory when setting memory limits for containers</description> </property>
6.mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property>
五、初始化集群
1.首先在node02、03、04上启动zookeeper,命令zkServer.sh start,可用通过zkServer.sh status来查看运行情况;
2.等zookeeper启动以后,按照规划启动journalnode,在node01、02、03上运行hdfs --daemon start journalnode。运行以后会创建hdfs-site.xml里dfs.journalnode.edits.dir所配置的路径;
3.因为是首次运行,需要先格式化hdfs。任选一个规划中的namenode节点(比如node01)运行hdfs namenode -format。这样会在core-site.xml中hadoop.tmp.dir配置的路径下创建dfs文件夹;
4.在node01上启动hdfs,运行hdfs --daemon start namenode。这样node01上会看到namenode进程,但是node02上依然没有;
5.把元数据同步到node02,在node02上运行hdfs namenode -bootstrapStandby。执行同步必须确保已经有一个namenode成功启动了;
6.初始化zookeeper,在node01上运行hdfs zkfc -formatZK。前提是zookeeper已经成功启动了;
7.至此初始化工作全部完成。
六、启动集群
1.在node02、03、04运行zkServer.sh start;
2.在node01运行start-dfs.sh,dfs启动后再运行start-yarn.sh。如果node03、04的ResourceManager没有启动,可以在这两节点分别运行yarn-daemon.sh start resourcemanager;
3.在浏览器输入node01:9870,node03:8088就能访问hdfs和yarn的web界面。
七、Windows开发环境配置
1.在环境变量中添加HADOOP_HOME、HADOOP_USER_NAME=root,并在path中引用HADOOP_HOME\bin
