[pytorch][stepbystep]在pytorch上实现卷积神经网路(CNN)的裁剪(purning)
利用VGG-16对Dogs-vs-Cats数据集进行训练,裁剪VGG-16可以获得3x的运算加速和4x的模型减小
简介
puring神经网络是一个古老的idea,具体可以追溯到1990年(与Yann LeCun的最佳脑损伤[1]工作)。这个想法是,在网络中的许多参数中,有些是冗余的,对输出没有太大贡献。
如果您可以根据它们贡献的数量对网络中的神经元进行排名,那么您可以从网络中删除低级神经元,从而产生更小更快的网络。
获得更快/更小的网络对于在移动设备上运行这些深度学习网络非常重要。
可以根据神经元权重的L1/L2均值、平均激活值、在某些验证集上神经元不为零的次数以及其他创造性方法来进行排名。 在修剪之后,准确度将可能会下降(如果排名足够好就不会下降太多),并且网络通常重训练以恢复。
如果一次性裁剪过多,那么神经网络将被破坏而无法恢复。因此,在实践中,这是一个迭代的过程——通常称为“迭代剪枝”:修剪/训练/重复。
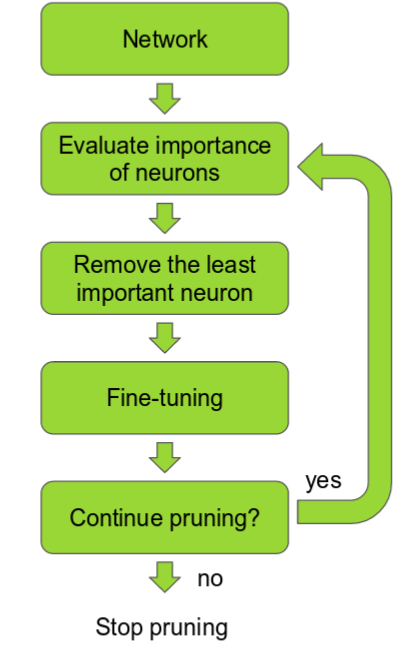
purning没有流行的原因
有很多关于修剪的论文,但我从未在现实生活深度学习项目中遇到过修剪。
考虑到在移动设备上运行深度学习的所有努力,这是令人惊讶的。 我想原因是:
- 直到现在,排名方法还不够好,导致精度下降太大。
- 实现起来很复杂。
- 那些使用修剪的人,保留它作为一个秘密或者优势。
所以,我决定自己实现purning,看看能不能用它取得好成绩。
在这篇文章中,我们将介绍一些修剪方法,然后深入研究最近一种方法的实现细节。
我们将微调一个VGG网络,对Kaggle的Dogs vs Cats数据集中的猫/狗进行分类,这代表了一种在实践中很常见的迁移学习。
然后我们将修剪网络并将得到了近3x的运算加速和4x的模型减小。
purning网络得到更快更小的模型
在VGG16中,90%的权重位于完全连接的层中,但这些权重仅占总浮点运算的1%。
直到最近,大部分工作都集中在修剪完全连接的层上。 通过修剪它们,可以显着减小模型尺寸。
我们将重点关注在卷积层中修剪整个滤波器(译者注:也即是一个kernel)。
但这也有减少记忆的冷静副作用。 正如在[2]论文中所观察到的那样,越深的网络就越容易被修剪。
这意味着最后的卷积层将被修剪很多,并且跟随它的完全连接层中的许多神经元也将被丢弃!
修剪卷积滤波器时,另一种选择是减少每个滤波器的权重,或者删除单个内核的特定维度。你可以得到稀疏的过滤器,但是并不容易使计算速度提升。 最近的paper提倡“结构稀疏性”,其中整个过滤器被修剪。
这些论文中的一些重要的一点是,通过训练然后修剪一个更大的网络,特别是在迁移学习的情况下,他们得到的结果比从头开始训练一个较小的网络要好得多。
现在让我们简要回顾几种裁剪方法。
Pruning Filters for Efficient ConvNets[3]
在这项工作中,他们主张修剪整个卷积滤波器。 修剪索引为k的过滤器会影响它所在的层以及下一层。 必须删除下一层中索引k处的所有输入通道,因为在修剪之后它们将不再存在。
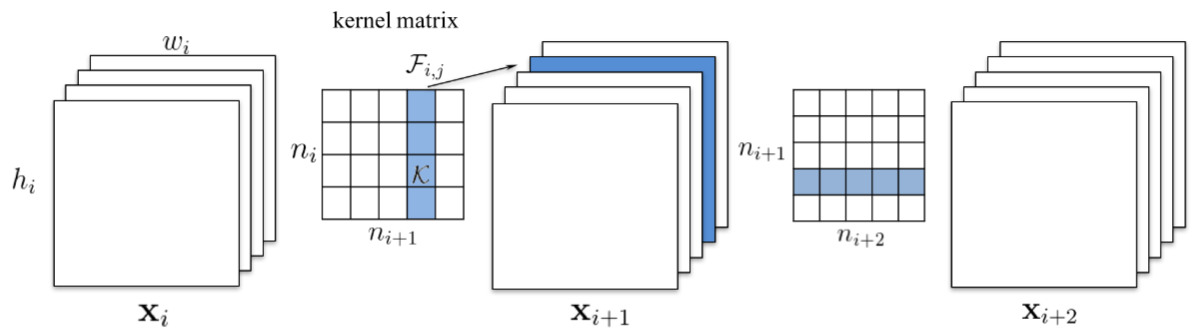
如果下一层是完全连接的层,并且该通道的特征图的大小将是MxN,则从完全连接的层移除MxN神经元。
这项工作中的神经元排名非常简单。 它是每个滤波器权重的L1范数。
在每次修剪迭代时,他们对所有过滤器进行排名,在所有层中全局修剪m个最低排名过滤器,重新训练和重复。
Structured Pruning of Deep Convolutional Neural Networks[4]
这项工作看似相似,但排名要复杂得多。 他们保留了一组N个粒子滤波器,它们代表N个卷积滤波器被修剪。
当粒子表示的过滤器未被遮盖时,基于验证集上的网络准确度为每个粒子分配分数。 然后根据新分数,对新的修剪掩模进行采样。
由于运行此过程很繁重,他们使用一个小的验证集来测量粒子分数。
Pruning Convolutional Neural Networks for Resource Efficient Inference[2]
这是来自Nvidia的非常酷的作品。
首先,他们将修剪问题称为组合优化问题:选择权重B的子集,以便在修剪它们时,网络成本变化将是最小的。
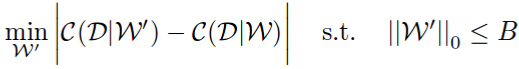
注意他们如何使用绝对差异而不仅仅是差异。 使用绝对差异强制修剪的网络不会过多地降低网络性能,但也不应该增加它。 在论文中,他们表明这会产生更好的结果,大概是因为它更稳定。
现在所有排名方法都可以通过此成本函数来判断。
Oracle Purning
VGG16有4224个卷积滤波器。 “理想”排名方法将是强力 - 修剪每个过滤器,然后观察在训练集上运行时成本函数如何变化。 由于他们来自Nvidia并且他们可以访问数以千计的GPU,他们就是这样做的。 这被称为oracle排名 - 最小化网络成本变化的最佳排名。 现在,为了衡量其他排名方法的有效性,他们计算了与oracle的spearman相关性。 令人惊讶的是,他们提出的排名方法(下面描述)与oracle最相关。
他们提出了一种新的神经元排序方法,该方法基于网络成本函数的第一阶(意味着快速计算)泰勒展开。
修剪滤波器h与将其归零相同。
当网络权重设置为W时,C(W,D)是数据集D上的平均网络成本函数。现在我们可以将C(W,D)评估为C(W,D,h = 0)附近的扩展。 它们应该非常接近,因为移除单个过滤器不应该太大地影响成本。
h的等级则是abs(C(W,D,h = 0)-C(W,D))。
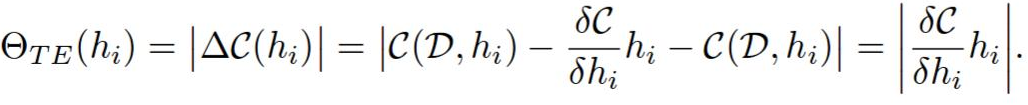
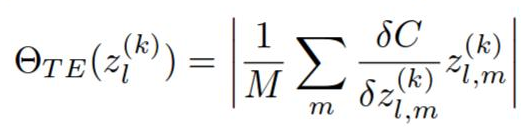
然后,通过该层中的等级的L2范数对每个层的排名进行归一化。 我想这种经验,我不知道为什么需要它,但它会极大地影响修剪的质量。
这个等级非常直观。 我们可以使用激活和渐变作为排序方法。 如果它们中的任何一个很高,那意味着它们对输出很重要。 如果渐变或激活非常低或高,则将它们相乘给我们提供抛出/保持滤波器的方法。
这让我感到奇怪 - 他们是否将修剪问题归结为最小化网络成本的差异, 然后提出泰勒扩展方法,或者是其他方式 ,并且网络成本的差异oracle是一种备份方式他们的新方法? 😃
在论文中,他们的方法在准确性方面也优于其他方法,因此看起来oracle是一个很好的指标。
无论如何,我认为这是一个比编码和测试更友好的方法,比如粒子滤波器更友好,所以我们将进一步探索这个!
使用泰勒级数排名重要度然后purning
因此,假设我们有一个转移学习任务,我们需要从相对较小的数据集创建分类器。 就像在这篇Keras博客文章[5]中一样。
我们可以使用像VGG这样强大的预训练网络进行传输学习,然后修剪网络吗?
如果在VGG16中学到的许多功能都是关于汽车,人和房屋 - 它们对简单的狗/猫分类器有多大贡献?
这是一个我认为很常见的问题。
作为训练集,我们将使用Kaggle Dogs vs Cats数据集[6]中的1000张猫图像和1000张狗图像。作为测试集,我们将使用400张猫的图像和400张狗的图像。
最终结果:
准确率从98.7%下降到97.5%。
网络大小从538 MB减少到150 MB。
在i7 CPU上,单个图像的推理时间从0.78减少到0.277秒, 几乎减少了x3倍!
step1. 训练一个大的网络
我们将采用VGG16,丢弃完全连接的层,并添加三个新的完全连接的层。 我们将固定卷积层,并仅重新训练新的完全连接的层。 在PyTorch中,新的网络层看起来像这样:
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(25088, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 2))
在使用数据增强训练20个时刻之后,我们在测试集上获得了98.7%(实际上 译者获得了98.8%)的准确度。
step2. 对网络中的参数进行排名
为了计算泰勒级数,我们需要在我们的数据集上执行前向+后向传递(如果它太大,则需要在它的较小部分上执行,但由于我们只有2000个图像可以直接使用它)。
现在我们需要以某种方式获得渐变和卷积层的激活。 在PyTorch中,我们可以在梯度计算上注册一个钩子,因此在它们准备就绪时会调用一个回调:
for layer, (name, module) in enumerate(self.model.features._modules.items()):
x = module(x)
if isinstance(module, torch.nn.modules.conv.Conv2d):
x.register_hook(self.compute_rank)
self.activations.append(x)
self.activation_to_layer[activation_index] = layer
activation_index += 1
现在我们在self.activations中进行了激活,当渐变准备就绪时,将调用compute_rank:
def compute_rank(self, grad):
activation_index = len(self.activations) - self.grad_index - 1
activation = self.activations[activation_index]
values = \
torch.sum((activation * grad), dim = 0).\
sum(dim=2).sum(dim=3)[0, :, 0, 0].data
# Normalize the rank by the filter dimensions
values = \
values / (activation.size(0) * activation.size(2) * activation.size(3))
if activation_index not in self.filter_ranks:
self.filter_ranks[activation_index] = \
torch.FloatTensor(activation.size(1)).zero_().cuda()
self.filter_ranks[activation_index] += values
self.grad_index += 1
这对批处理中的每个激活和它的梯度进行了逐点乘法,然后对于每次激活(即卷积的输出),除了输出的维度之外,我们在所有维度上求和。
例如,如果批量大小为32,则特定激活的输出数为256,激活的空间大小为112x112,激活/梯度形状为32x256x112x112,则输出将为256大小的向量,表示排名该层中的256个过滤器。
现在我们有了排名,我们可以使用最小堆来获得N个最低排名的过滤器。 与Nvidia论文不同,他们在每次迭代时使用N = 1,为了更快地获得结果,我们将使用N = 512! 这意味着每次修剪迭代时,我们将从4224个卷积滤波器的原始数量中删除12%。
低排名过滤器的分布很有意思。 被修剪的大多数过滤器来自更深层。 以下是第一次迭代后修剪过滤器的方法:
| 层数 | 修剪过的修剪过滤器数量 |
|---|---|
| 第0层 | 6 |
| 第2层 | 1 |
| 第5层 | 4 |
| 第7层 | 3 |
| 第10层 | 23 |
| 第12层 | 13 |
| 第14层 | 9 |
| 第17层 | 51 |
| 第19层 | 35 |
| 第21层 | 52 |
| 第24层 | 68 |
| 第26层 | 74 |
| 第28层 | 73 |
step3. 微调网络并重复裁剪
在这个阶段,我们解冻所有层并重新训练网络10个epoches,这足以在此数据集上获得良好的结果。 然后我们使用修改后的网络返回步骤1,并重复。
这是我们支付的实际价格 - 这是用于训练网络的epoc数量的50%,在一次迭代中。 在这个玩具数据集中,我们可以使用它,因为数据集很小。 如果您正在为大型数据集执行此操作,则最好使用大量GPU。
引用
[1]. http://yann.lecun.com/exdb/publis/pdf/lecun-90b.pdf
[2]. https://arxiv.org/abs/1611.06440
[3]. https://arxiv.org/abs/1608.08710
[4]. https://arxiv.org/abs/1512.08571
[5]. https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html

