

排序算法汇总
这里记录一下各种排序算法的比较和特性,主要摘自维基百科
稳定的
- 冒泡排序(bubble sort) — O(n2)
- 鸡尾酒排序 (Cocktail sort, 双向的冒泡排序) — O(n2)
- 插入排序 (insertion sort)— O(n2)
- 桶排序 (bucket sort)— O(n); 需要 O(k) 额外空间
- 计数排序 (counting sort) — O(n+k); 需要 O(n+k) 额外空间
- 合并排序 (merge sort)— O(n log n); 需要 O(n) 额外空间
- 原地合并排序 — O(n2)
- 二叉排序树排序 (Binary tree sort) — O(n log n)期望时间; O(n2)最坏时间; 需要 O(n) 额外空间
- 鸽巢排序 (Pigeonhole sort) — O(n+k); 需要 O(k) 额外空间
- 基数排序 (radix sort)— O(n·k); 需要 O(n) 额外空间
- Gnome 排序 — O(n2)
- 图书馆排序 — O(n log n) with high probability, 需要 (1+ε)n 额外空间
不稳定
- 选择排序 (selection sort)— O(n2)
- 希尔排序 (shell sort)— O(n log n) 如果使用最佳的现在版本
- 组合排序 — O(n log n)
- 堆排序 (heapsort)— O(n log n)
- 平滑排序 — O(n log n)
- 快速排序 (quicksort)— O(n log n) 期望时间, O(n2) 最坏情况; 对于大的、乱数列表一般相信是最快的已知排序
- Introsort — O(n log n)
- Patience sorting — O(n log n + k) 最坏情况时间,需要 额外的 O(n + k) 空间,也需要找到最长的递增子串行(longest increasing subsequence)
不实用的排序算法
- Bogo排序 — O(n × n!),最坏的情况下期望时间为无穷。
- Stupid sort — O(n3); 递归版本需要 O(n2) 额外存储器
- 珠排序(Bead sort) — O(n) or O(√n), 但需要特别的硬件
- Pancake sorting — O(n), 但需要特别的硬件
平均时间复杂度
平均时间复杂度由高到低为:
- 冒泡排序 O(n2)
- 插入排序 O(n2)
- 选择排序 O(n2)
- 归并排序 O(n log n)
- 堆排序 O(n log n)
- 快速排序 O(n log n)
- 希尔排序 O(n1.25)
- 基数排序 O(n)
说明:虽然完全逆序的情况下,快速排序会降到选择排序的速度,不过从概率角度来说(参考信息学理论,和概率学),不对算法做编程上优化时,快速排序的平均速度比堆排序要快一些。
实际测试结果
OS: winxp, Compiler: vc8, CPU:Intel T7200, Memory: 2G 不同数组长度下调用6种排序1000次所需时间(秒) length shell quick merge insert select bubble 100 0.0141 0.359 1.875 0.204 0.313 0.421 1000 0.218 0.578 2.204 1.672 2.265 4 5000 1.484 3.25 14.14 41.392 63.656 101.703 10000 3.1 7.8 23.5 253.1 165.6 415.7 50000 21.8 40.6 121.9 411.88 6353.1 11648.5 100000 53.1 89 228.1 16465.7 25381.2 44250 结论: 数组长度不大的情况下不宜使用归并排序,其它排序差别不大。 数组长度很大的情况下Shell最快,Quick其次,冒泡最慢。
简要比较
| 名称 | 数据对象 | 稳定性 | 时间复杂度 | 空间复杂度 | 描述 | ||
|---|---|---|---|---|---|---|---|
| 平均 | 最坏 | ||||||
| 插入排序 | 数组、链表 | √ | 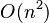 |
O(1) | (有序区,无序区)。把无序区的第一个元素插入到有序区的合适的位置。对数组:比较得少,换得多。 | ||
| 直接选择排序 | 数组 | × | |
O(1) | (有序区,无序区)。在无序区里找一个最小的元素跟在有序区的后面。 对数组:比较得多,换得少。 | ||
| 链表 | √ | ||||||
| 堆排序 | 数组 | × | O(nlogn) | O(1) | (最大堆,有序区)。从堆顶把根卸出来放在有序区之前,再恢复堆。 | ||
| 归并排序 | 数组、链表 | √ | O(nlogn) | O(n) +O(logn) , 如果不是从下到上 | 把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。可从上到下或从下到上进行。 | ||
| 快速排序 | 数组 | × | O(nlogn) | |
O(logn) ,O(n) | (小数,枢纽元,大数)。 | |
| Accum qsort | 链表 | √ | O(nlogn) | |
O(logn) ,O(n) | (无序区,有序区)。把无序区分为(小数,枢纽元,大数),从后到前压入有序区。 | |
| 决策树排序 | √ | O(logn!) | O(n!) | O(n) <O(logn!) <O(nlogn) | |||
| 计数排序 | 数组、链表 | √ | O(n) | O(n+m) | 统计小于等于该元素值的元素的个数 i,于是该元素就放在目标数组的索引 i位。(i≥0) | ||
| 桶排序 | 数组、链表 | √ | O(n) | O(m) | 将值为 i 的元素放入i 号桶,最后依次把桶里的元素倒出来。 | ||
| 基数排序 | 数组、链表 | √ | O(k*n),最坏:O(n^2) | 一种多关键字的排序算法,可用桶排序实现。 | |||
- 均按从小到大排列
- k 代表数值中的"数位"个数
- n 代表数据规模
- m 代表数据的最大值减最小值
排序算法
| ||
|---|---|---|
| 理论 |  |
|
| 交换排序法 | ||
| 选择排序法 | ||
| 插入排序法 | ||
| 归并排序法 | ||
| 分布排序法 | ||
| 混合排序法 | ||
| 其他 | ||

