Python文件处理
文件操作分为读、写、修改,我们先从读开始学习
文件在硬盘上是以某种编码格式的 “010101010101001” 保存在硬盘上。
读文件
f = open('python_file.txt','r',encoding='utf-8') # 文件路径 只读模式 以什么样的编码方式去读或写 data = f.read() #表示读取所有内容,内容是已经转换完毕的字符串。 print(data) f.close() #关闭文件 # PS: 此处的encoding必须和文件在保存时设置的编码一致, # 不然“断句”会不准确从而造成乱码。
f = open('python_file.txt','rb') # 'rb'以二进制模式读取 data = f.read() print(data) # b'python\xe5\xbe\x88\xe6\xa3\x92' print(data.decode()) # python很棒 f.close()
当不知道文件以哪种编码时 import chardet
result = chardet.detect(open('python_file.txt',mode='rb').read()) print(result)
#{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}
循环文件
f = open("python_file",'r',encoding="utf-8") for line in f: print(line) f.close()
写文件
f = open('python_file.txt',mode='w',encoding='utf-8') f.write('life is short ') f.close()
二进制写
f = open('二进制写.txt','wb') f.write('life is short ,I chose python'.encode('utf-8')) # 表示写入内容,写入的内容必须字节类型 f.close()
追加
把内容追加到文件尾部 f = open("python_file.txt",'a',encoding="utf-8") f.write("linux is not unix") f.close() 文件操作时,以 “a”或“ab” 模式打开,则只能追加,即:在原来内容的尾部追加内容 写入到硬盘上时,必须是某种编码的0101010, 打开时需要注意: ab,写入时需要直接传入以某种编码的0100101,即:字节类型 a 和 encoding,写入时需要传入unicode字符串,内部会根据encoding制定的编码将unicode字符串转换为该编码的 010101010
读写模式
先读后写,注意光标的移动
f = open("pythoner.txt",'r+',encoding="utf-8") data = f.read() #此时读完,光标已经在最后了 print("content",data) f.write("\nnewline 1 python is good") f.write("\nnewline 2 life is short") f.write("\nnewline 3 I chose python") f.write("\nnewline 4 linux is not unix") print("new_content") print(f.read()) f.close() output>>> content newline 1 python is good newline 2 life is short newline 3 I chose python newline 4 linux is not unix new_content #后面的内容呢。。。 解释如下
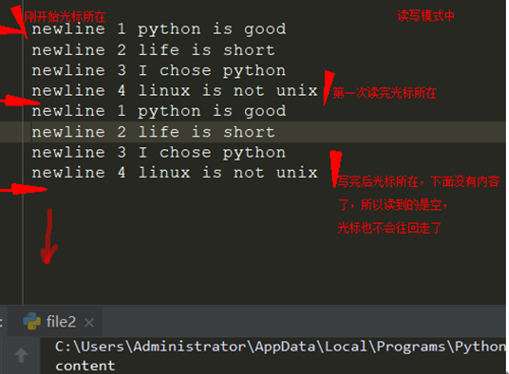
写读模式(一般用不到)
f = open("pythoner.txt",'w+',encoding="utf-8") data = f.read() print(data) f.write("\nnewline 1 python is good") f.write("\nnewline 2 life is short") f.write("\nnewline 3 I chose python") f.write("\nnewline 4 linux is not unix") print("content",f.read()) f.close()
w+会先把文件清空,再写新内容,相比w模式,只是支持了一个读功能,且还只能读已经写入的新内容
总结:跟光标的移动有关,能不能读到内容
文件操作的其它功能


def fileno(self, *args, **kwargs): # real signature unknown 返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到 def flush(self, *args, **kwargs): # real signature unknown 把文件从内存buffer里强制刷新到硬盘 def readable(self, *args, **kwargs): # real signature unknown 判断是否可读 def readline(self, *args, **kwargs): # real signature unknown 只读一行,遇到\r or \n为止 def seek(self, *args, **kwargs): # real signature unknown 把操作文件的光标移到指定位置(字节) *注意seek的长度是按字节算的, 字符编码存每个字符所占的字节长度不一样。 如“路飞学城” 用gbk存是2个字节一个字,用utf-8就是3个字节,因此以gbk打开时,seek(4) 就把光标切换到了“飞”和“学”两个字中间。 但如果是utf8,seek(4)会导致,拿到了飞这个字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用utf8处理不了了,因为编码对不上了。少了一个字节 def seekable(self, *args, **kwargs): # real signature unknown 判断文件是否可进行seek操作 def tell(self, *args, **kwargs): # real signature unknown 返回当前文件操作光标位置 返回(字节) def truncate(self, *args, **kwargs): # real signature unknown 按指定长度截断文件 *指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉。 def writable(self, *args, **kwargs): # real signature unknown 判断文件是否可写 f.read()是读一个字符
修改文件
尝试直接以r+模式打开文件,默认会把新增的内容追加到文件最后面(最新测试r+会从头覆盖,测试代码如下)
open("python_file.txt",'w',encoding='utf-8') f1.write("[元贞]") f1.close() f2 = open("python_file.txt",'r+',encoding="utf-8") # print(f2.read()) #先读后写就不会被覆盖,而是追加,因为刚开始光标在最开头,读一下操作光标会移到最后,在写就不会覆盖掉之前的内容 f2.write('fade_walk') f2.close()

seek,之所以内容会追加到最后面,是因为,文件一打开,要写的时候,光标会默认移到文件尾部,再开始写
f = open("contact.txt",'r+',encoding="utf-8") f.seek(6) f.write("mysql") f.close()
但是执行后插入的内容把插入处后面的内容覆盖掉
这是硬盘的存储原理导致的,当你把文件存到硬盘上,就在硬盘上划了一块空间,存数据,等你下次打开这个文件 ,seek到一个位置,每改一个字,就是把原来的覆盖掉,如果要插入,是不可能的,因为后面的数据在硬盘上不会整体向后移。所以就出现 当前这个情况 ,你想插入,却变成了会把旧内容覆盖掉。
问:但是人家word, vim 都可以修改文件呀,你这不能修改算个什么玩意?
当然可以,就是不要在硬盘上修改,把内容全部读到内存里,数据在内存里可以随便增删改查,修改之后,把内容再全部写回硬盘,把原来的数据全部覆盖掉。vim word等各种文本编辑器都是这么干的。
如果不想占内存,只能用另外一种办法啦,就是边读边改, 什么意思? 不是不能改么?是不能改原文件 ,但你可以打开旧文件 的同时,生成一个新文件呀,边从旧的里面一行行的读,边往新的一行行写,遇到需要修改就改了再写到新文件 ,这样,在内存里一直只存一行内容。就不占内存了。 但这样也有一个缺点,就是虽然不占内存 ,但是占硬盘,每次修改,都要生成一份新文件,虽然改完后,可以把旧的覆盖掉,但在改的过程中,还是有2份数据 的

