

聚类算法实现(二)DBSCAN
根据上面第二个数据集的簇的形状比较怪异,分簇结果应该是连起来的属于一个簇,但是k-means结果分出来很不如人意,所以这里介绍一种新的聚类方法,此方法不同于上一个基于划分的方法,基于划分主要发现圆形或者球形簇;为了发现任意形状的簇,用一个基于密度的聚类方法,这类方法将簇看做是数据空间中被低密度区域分割开的稠密对象区域,这一理念刚好也符合数据集的特征。
DBSCAN:一种基于高密度连通区域的基于密度的聚类方法,该算法将具有足够高密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇。它将簇定义为密度相连的点的最大集合;为了理解基于密度聚类的思想,首先要掌握以下几个定义:
给定对象半径r内的邻域称为该对象的r邻域;
如果对象的r邻域至少包含最小数目MinPts的对象,则称该对象为核心对象;
给定一个对象集合D,如果p在q的r邻域内,并且q是一个核心对象,则我们说对象p从对象q出发是直接密度可达的;
如果存在一个对象链p1,p2,p3,...,pn,p1=q,pn=p,对于pi属于D,i属于1~n,p(i+1)是从pi关于r和MinPts直接密度可达的,则对象p是从对象q关于r和MinPts密度可达的;
如果存在对象o属于D,使对象p和q都是从o关于r和MinPts密度可达的,那么对于对象p到q是关于r和MinPts密度相连的;
密度可达是直接密度可达的传递闭包,这种关系非对称,只有核心对象之间相互密度可达;密度相连是一种对称的关系;
有了以上的概念接下来就是算法描述了:DBSCAN通过检查数据库中每点的r邻域来搜索簇。如果点p的r邻域包含的点多余MinPts个,则创建一个以p为核心对象的新簇。然后,DBSCAN迭代的聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并。当没有新的点可以添加到任何簇时,该过程结束;
具体的伪代码描述如下(摘自维基百科):

1 DBSCAN(D, eps, MinPts) 2 C = 0 //类别标示 3 for each unvisited point P in dataset D //遍历 4 mark P as visited //已经访问 5 NeighborPts = regionQuery(P, eps) //计算这个点的邻域 6 if sizeof(NeighborPts) < MinPts //不能作为核心点 7 mark P as NOISE //标记为噪音数据 8 else //作为核心点,根据该点创建一个类别 9 C = next cluster 10 expandCluster(P, NeighborPts, C, eps, MinPts) //根据该核心店扩展类别 11 12 expandCluster(P, NeighborPts, C, eps, MinPts) 13 add P to cluster C //扩展类别,核心店先加入 14 for each point P' in NeighborPts //然后针对核心店邻域内的点,如果该点没有被访问, 15 if P' is not visited 16 mark P' as visited //进行访问 17 NeighborPts' = regionQuery(P', eps) //如果该点为核心点,则扩充该类别 18 if sizeof(NeighborPts') >= MinPts 19 NeighborPts = NeighborPts joined with NeighborPts' 20 if P' is not yet member of any cluster //如果邻域内点不是核心点,并且无类别,比如噪音数据,则加入此类别 21 add P' to cluster C 22 23 regionQuery(P, eps) //计算邻域 24 return all points within P's eps-neighborhood
这个算法的时间复杂度的限制主要在于邻域的计算,如果存在索引,则能够降低时间复杂度,如果不存在索引,则邻域计算需要遍历所有点,这样时间复杂度就比较高,相当于双层的n的循环,所以时间复杂度为O(n2);
不过针对相同时间复杂度的时间,每个人的算法的运行时间也不尽相同,如果能够做很多的优化,一些常数时间的减少也能够减少时间,由于我这里仅仅是针对伪代码的实现,没有进行数据结构的优化,相对的数据结构也是利用了k-means用的数据结构进行了一些补充,比如添加一些基于密度需要的属性,比如是否被访问,是否为噪音,是否被添加至邻域中等等,跑起来针对数据集1的规模能够很快的得出结果,但是针对数据集2的数据量30W左右的点就存在很多问题,时间很慢,甚至不能容忍,release优化下好一些,debug下基本上无法等待出结果的,所以任何程序都要进行优化的,优化到你个人的最优;
接下来是这个算法的具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 | COLORREF colorfultmp[]={RGB(192,192,192),RGB(255,255,0),RGB(227,207,87),RGB(255,153,18),RGB(235,142,85),RGB(255,227,132),RGB(255,97,0),RGB(176,224,230),RGB(65,105,230),RGB(0,255,255),RGB(56,94,15),RGB(8,46,84),RGB(128,42,42),RGB(34,139,34),RGB(160,32,240),RGB(255,0,0),RGB(176,48,96),RGB(176,23,31),RGB(0,0,0)};void Cluster::dbscan(vector<AbstractDataPT*> pts,double eps,int MinPts){ int categroy=0; int i,length=pts.size(); vector<AbstractDataPT*> neightpts,tmpneightpts; //遍历所有的点 for (i=0;i<length;i++) { //Sleep(1000); //如果没有访问,标记为访问 if (!pts[i]->m_bVisited) { pts[i]->m_bVisited=TRUE; //计算邻域 neightpts=pts[i]->regionQuery(pts,pts[i],eps); //include //噪音标记 if (neightpts.size()<MinPts) { pts[i]->categroy=0;//NOISE pts[i]->m_isNoise=TRUE; pts[i]->m_colorPT=colorfultmp[pts[i]->categroy%18]; } else { //核心点,聚类 categroy++; pts[i]->categroy=categroy; pts[i]->m_colorPT=colorfultmp[pts[i]->categroy%18]; //邻域内的点标记已经被添加 for (int k=0;k<neightpts.size();k++) { neightpts[k]->m_isInclude=TRUE; } //继续扩大此聚集类 int j=1; //因为邻域的规模组建增大,所以利用while while (j<neightpts.size()) { //没有类别则加入该类别,扩大的类别 if (neightpts[j-1]->categroy==0) { neightpts[j-1]->categroy=categroy; neightpts[j-1]->m_colorPT=colorfultmp[neightpts[j-1]->categroy%18]; } //标记访问 if (!neightpts[j-1]->m_bVisited) { neightpts[j-1]->m_bVisited=TRUE; //计算邻域 tmpneightpts=neightpts[j-1]->regionQuery(pts,neightpts[j-1],eps); //合并核心点的邻域 if (tmpneightpts.size()>=MinPts) { //合并 int m,n; //已经添加则不进行添加 for (m=0;m<tmpneightpts.size();m++) { /* if (tmpneightpts[m]->categroy==0) { neightpts.push_back(tmpneightpts[m]); } */ //不重复添加 //感觉这里限制程序时间的瓶颈 if (!tmpneightpts[m]->m_isInclude) { neightpts.push_back(tmpneightpts[m]); tmpneightpts[m]->m_isInclude=TRUE; } /* BOOL exist=FALSE; for (n=0;n<neightpts.size();n++) { if (tmpneightpts[m]==neightpts[n]) { exist=TRUE; } } if (!exist) { neightpts.push_back(tmpneightpts[m]); } */ } } } //继续 j++; } } } }} |
计算邻域的代码如下(循环所有点进行计算):
1 2 3 4 5 6 7 8 9 10 11 12 13 | vector<AbstractDataPT*> DataPT2D::regionQuery(vector<AbstractDataPT*> pts,AbstractDataPT* pt,double eps){ vector<AbstractDataPT*> neighbor; int i,length=pts.size(); for (i=0;i<length;i++) { if (pt->calculateD(pts[i])<=eps) { neighbor.push_back(pts[i]); } } return neighbor;} |
时间表现非常慢,仍需要改进;
数据类型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | #pragma once#include <vector>using namespace std;class AbstractDataPT{public: AbstractDataPT(void); virtual ~AbstractDataPT(void); virtual double calculateD(AbstractDataPT* otherPT)=0; virtual void drawSelf(CDC* pDc)=0; virtual void drawNormalSelf(CDC* pDc)=0; virtual vector<AbstractDataPT*> calculateMeans(vector<AbstractDataPT*> pts,int k)=0; virtual double calculateE(vector<AbstractDataPT*> pts,vector<AbstractDataPT*> kMeans)=0; virtual vector<AbstractDataPT*> regionQuery(vector<AbstractDataPT*> pts,AbstractDataPT* pt,double eps)=0;public: //属于哪一个类别 int categroy; COLORREF m_colorPT; BOOL m_bVisited; BOOL m_isInclude; BOOL m_isNoise;};#pragma once#include "abstractdatapt.h"class DataPT2D : public AbstractDataPT{public: DataPT2D(void); DataPT2D(double cx,double cy); DataPT2D(double cx,double cy,COLORREF color); ~DataPT2D(void); double calculateD(AbstractDataPT* otherPT); void drawSelf(CDC* pDc); void drawNormalSelf(CDC* pDc); vector<AbstractDataPT*> calculateMeans(vector<AbstractDataPT*> pts,int k); double calculateE(vector<AbstractDataPT*> pts,vector<AbstractDataPT*> kMeans); vector<AbstractDataPT*> regionQuery(vector<AbstractDataPT*> pts,AbstractDataPT* pt,double eps); double m_fCX; double m_fCY;}; |
release下经过N久之后终于有结果了,截图如下:

结果有点诡异,因为颜色只定义了18种,类别循环使用的颜色
修正:第二题目预处理的时候这里忽略了一些数据的问题,所以第二个数据集聚类出效果不是很好,这里修正一下,不只是取出白色的点,这里过滤条件增强,去除稍微浅色的点,这里暂时设置如下:
1 2 3 4 | if (nCR>235&&nCG>235&&nCB>235) { continue; } |
这样处理还有一个好处就是过滤了一部分点,点的数量降低了;
这样就可以得到一个比较清晰的图像了,截图如下,这里图形进行了放大,所以显示出来有部分没有显示:

这里找到了一种提高时间效率的方法,书中给出的DBSCAN提高时间效率的方法是利用空间索引,这里查到一种RTree的方法,但是实现代价比较昂贵,而且不知道如何实现,下载了RTree实现的源代码有时间学习学习这一个数据结构~
这里存在另外一种方法同样提高效率,针对这个数据同样能够降低很多时间复杂度,针对此数据实现的较好应该能够达到线性时间,这里能够在5分钟内跑出结果,其实这也是很慢的了,因为我的程序实现很多地方比较冗余,比较杂乱,程序写的修改质量不高,也不好修改,5分钟已经达到我的目标,所以我就不进行修改了,如果你看到这个利用这个原理,也许能够达到一分钟以内的哟,亲;
原理如下,针对每个点,计算其邻域的时候首先按照半径将图划分成矩形的格子;然后每个点只需要计算其周围的9个格子的内容,针对此数据可以看错做常数时间~预处理为线性;
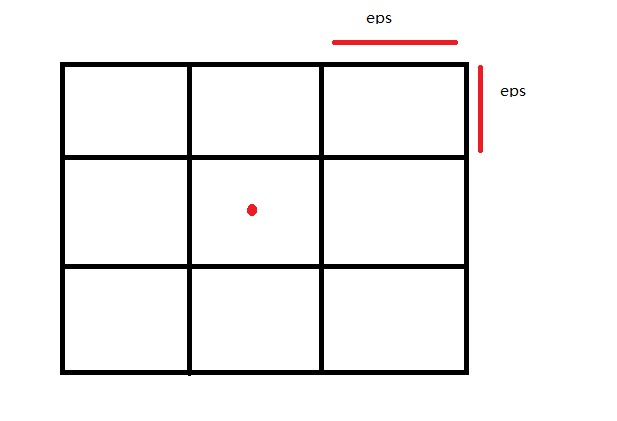
主要代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | vector<AbstractDataPT*> DataPT2D::regionQuery(vector<AbstractDataPT*> pts,AbstractDataPT* pt,double eps){ int index = regionNum(pt,eps); //index-1-x_2d_max/eps,index-x_2d_max/eps;index+1-x_2d_max/eps //index-1,index,index+1 //index-1+x_2d_max/eps,index+x_2d_max/eps;index+1+x_2d_max/eps int num = x_2d_max/eps; vector<AbstractDataPT*> tmp; int i,j,k,length=pts.size(); for (i=-1;i<2;i++) { for (j=-1;j<2;j++) { int tmpindex = index+i+num*j; if (tmpindex<0) { tmpindex=0; } int size = Region[tmpindex]->regionBy.size(); for (k=0;k<size;k++) { tmp.push_back(Region[index+i+num*j]->regionBy[k]); } } } vector<AbstractDataPT*> neighbor; length=tmp.size(); for (i=0;i<length;i++) { if (pt->calculateD(tmp[i])<=eps) { neighbor.push_back(tmp[i]); } } return neighbor;}int DataPT2D::regionNum(AbstractDataPT* pt,double eps){ //转换 DataPT2D* tmpDatapt=(DataPT2D*)pt; int x_index=tmpDatapt->m_fCX/eps; int y_index=tmpDatapt->m_fCY/eps; int num = x_2d_max/eps; int result=x_index+y_index*num; return result;} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 | void Cluster::dbscan(vector<AbstractDataPT*> pts,double eps,int MinPts){ //清空region数据结构 Region.clear(); int categroy=0; int i,length=pts.size(); //初始化region数据结构 //这里直接将region初始化足够长,偷懒 for (i=0;i<BIGMAX;i++) { Region.push_back(new regionvector()); } //根据半径初始化Region数据 for(i=0;i<length;i++) { Region[pts[i]->regionNum(pts[i],eps)]->regionBy.push_back(pts[i]); //? } vector<AbstractDataPT*> neightpts,tmpneightpts; //遍历所有的点 for (i=0;i<length;i++) { //Sleep(1000); //如果没有访问,标记为访问 if (!pts[i]->m_bVisited) { pts[i]->m_bVisited=TRUE; //计算邻域 neightpts=pts[i]->regionQuery(pts,pts[i],eps); //include //噪音标记 if (neightpts.size()<MinPts) { pts[i]->categroy=0;//NOISE pts[i]->m_isNoise=TRUE; pts[i]->m_colorPT=colorfultmp[pts[i]->categroy%18]; } else { //核心点,聚类 categroy++; pts[i]->categroy=categroy; pts[i]->m_colorPT=colorfultmp[pts[i]->categroy%18]; //邻域内的点标记已经被添加 for (int k=0;k<neightpts.size();k++) { neightpts[k]->m_isInclude=TRUE; } //继续扩大此聚集类 int j=1; //因为邻域的规模组建增大,所以利用while while (j<neightpts.size()) { //没有类别则加入该类别,扩大的类别 if (neightpts[j-1]->categroy==0) { neightpts[j-1]->categroy=categroy; neightpts[j-1]->m_colorPT=colorfultmp[neightpts[j-1]->categroy%18]; } //标记访问 if (!neightpts[j-1]->m_bVisited) { neightpts[j-1]->m_bVisited=TRUE; //计算邻域 tmpneightpts=neightpts[j-1]->regionQuery(pts,neightpts[j-1],eps); //合并核心点的邻域 if (tmpneightpts.size()>=MinPts) { //合并 int m,n; //已经添加则不进行添加 for (m=0;m<tmpneightpts.size();m++) { /* if (tmpneightpts[m]->categroy==0) { neightpts.push_back(tmpneightpts[m]); } */ //不重复添加 //感觉这里限制程序时间的瓶颈 if (!tmpneightpts[m]->m_isInclude) { neightpts.push_back(tmpneightpts[m]); tmpneightpts[m]->m_isInclude=TRUE; } /* BOOL exist=FALSE; for (n=0;n<neightpts.size();n++) { if (tmpneightpts[m]==neightpts[n]) { exist=TRUE; } } if (!exist) { neightpts.push_back(tmpneightpts[m]); } */ } } } //继续 j++; } } } }} |
只是增加了根据半径初始化格子的代码,修改计算时候的部分,其他的均未修改;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架