

python 列表的sorted方法与排序算法的差异
一个初学python的小白考虑算法和时间复杂的空间复杂度太远了。
在家看书看到一个小问题说到了冒泡排序,本着急切想了解高大上算法的python小白就去研究了一下
冒泡排序算法:
lis = [9, 6, 8, 7, 5, 3, 1, 2]
for i in range(len(lis)):
for j in range(len(lis)):
if a[i] >= a[j]:
pass
else:
lis[i], lis[j] = lis[j], lis[i]
print(lis)
结果如下:
[1, 2, 3, 5, 6, 7, 8, 9]
然后就是python的sroted方法:
print(sroted(lis,reverse=False)
结果如下:
[1, 2, 3, 5, 6, 7, 8, 9]
发现没有,两个方法得到的结果完全一样有木有?一个用了7行代码,而另一个就只有一行代码?我脑子瓦特啦?还用算法,还那么难学
第二天早上就迫不及待的找到导师问了一下:
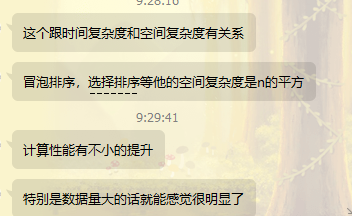
导师给到的解答是这样的,简单理解来说就是,你就几个数据,用啥方法都行,你要是有巨量的数据你再试试?
然后我还真的找了大量的数据试了一下,π的数据100万位。
然后然后刺激的来了sorted运行时间为:
时间:0.014961004257202148
冒泡排序的运行时间为:
时间:45.61460757255554
what????算法比用sorted方法整整多了四十多秒?
又去网上找了一下sorted的底层实现算法,发现用了一种
归并排序
def merge(left,right):
merged = []
i,j = 0,0
left_len,right_len = len(left),len(right)
while i<left_len and j<right_len:
if left[i] <= right[j]:
merged.append(left[i])
i += 1
else:
merged.append(right[j])
j += 1
merged.extend(left[i:])
merged.extend(right[j:])
return merged
def mergeSort(a):
if len(a) <= 1:
return a
else:
mid = len(a) // 2
left = mergeSort(a[:mid])
right = mergeSort(a[mid:])
merge(left,right)
return merge(left,right)
def main():
a = [59,12,77,64,72,69,46,89,31,9]
a1 = mergeSort(a)
print(a1)
if __name__ == '__main__':
main()
看着就比冒泡排序高级好吗?
总的来说,冒泡排序是很基础的排序方式,运算速度还是比较慢的,从上面看到两个方法的时间可以看到算法与算法之间的巨大差异。
同志们加油学习吧,加油,好好学习,天天向上!!!
自己不知道要干什么的时候就想想你想要什么。
不知道想要什么的时候。
就多想想,说不定想着想着就知道自己想要什么了。
想好了就去试试,说不定你就能拿到你想要的对象了,你不试一下,你就是想你怎么想也拿不到! anyway ..... what ever....
