



数据分组,就是相同值放在一起。比如按部门分组,就是将部门字段相同的记录放在一起。对于标准的分组比较简单,因为SQL语句中就提供GROUP命令。但现实中有时会有一些不规则分组的情况。下面列举一下:
1 随机分成多个区间,比如年龄字段分成:0到15,15到30,30到40,40到50,50以上。
如下图所示:

当然这种分成多个区间的情况也可以通过写复杂的SQL语句来实现,考虑到SQL语句还要实现其它一些逻辑,所以这样的话会大大的加大写SQL语句的工作量。实际上这种分多个区间的不规则分组还是有些规律的。所以最好还是象e表这样专门做一个函数来解决这种情况比较好。下面列出这个函数的说明:
scope
函数说明:
根据完全划分进行分组
语法:
datasetName.scope( selectExp, listExp[, filterExp][, eqExp][, ascExp] )
参数说明:
selectExp 取值表达式
ListExp 返回同valueExp数据类型相同的数组,要求其中元素从小到大排列
filterExp 过滤表达式
eqExp 返回布尔值的表达式,缺省为false,表示与元素比较时不包含等于
ascExp 返回布尔值的表达式,缺省为true,表示listExp返回的数组按从小到大排,否则为从大到小排
特别说明:
ascExp为true(即listExp从小到大排列)时,eqExp为true时,与元素比较时采用<=,eqExp为false时,采用<;
ascExp为false(即listExp从大到小排列)时,eqExp为true时,与元素比较时采用>=,eqExp为false时,采用>
示例:
ds1.scope(age,[15,30,40,50])
2 前面枚举几个固定值,最后来一个其它。比如产品分组为:CPU,内存,硬盘,其它。即其它类中的内容为除CPU,内存,硬盘这三个之外的所有内容。这也是中国式报表中的一种常见的不规则分组。
3 地区分组时,象这样:北京,河北,山东,其中:青岛,江西。即在山东后面要加上一个青岛,其它都是正常的分组。如下图所示:
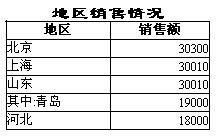
加一个青岛后可就比较麻烦了。往往会被迫要写程序来准备特定的数据集来实现。e表是如何在不用写代码的情况下解决此问题的呢?
e表内部有一个内建数据集的工具,有人往大了说它是一个小数据库。实际上只是一个简单的编辑表数据的工具而已。最早设计内建数据集的初衷是为了方便自己做e表的技术支持,因为有它后,用户只需要将一个出了错的报表文件发给我们,我们就可以在e表中打开并运行它。而不需要用户把数据库发给我们。后来发现内建数据集可以作数据词典用,正好可以相对简单(不用编程)地解决这个问题。即只要将 北京,河北,山东,其中:青岛,江西 作成一个数据词典,保存在内建数据集中即可解决此问题。
在上一个专题中重点分析了数据集中的数据应如何在静态的报表上展开。在展开后,往往还应能在报表上找到哪些展开了的数据,以便进行再计算。这一阶段的报表运算中最典型的部分就是跨行组运算了。
跨行组运算,直观来理解就是跨行(指记录行)或跨组(指分组的组,一个数据集的所有记录合起来也可认为是一个组)的运算了。下面来详细说明一下:
跨行运算,即需要取到别的记录行的数据,典型例子是要取上一记录行的数据。比如:财务软件中常有的当前行的余额等于上一行的余额+本行的借方金额-本行的贷方金额。即累积运算。如下图所示:

其中累积金额列应等于上一行的累积金额加上本行的合同金额。要实现此累积运算,只需要设置公式为:E3公式 = D3+E3[-1] //其中 E3[-1] 表示取E3扩展出的上一行的单元格的值,是单元格的扩展坐标中相对坐标的概念。
跨组运算,在多级分组的情况下,常常需要取得某一级下的当前组的单元格集合来进行计算。如计算排名,占比,上期比同期比等等。下图为上期比同期比的示例。

想详细看看本文的报表示例的朋友可以到北京方成公司的网站上在线试用或下载到本地试用。
总结:
本专题主要讲了讲报表数据运算的后续部分,即不规则分组和跨行组运算。在下一专题中,将讲一些轻松的话题。下周一将发布web报表开发技术专题四:开发报表设计器的背后故事。
相关链接:
[原创]web报表开发技术专题一:序号问题
[原创]web报表开发技术专题二:报表工具的核心---数据集的变换
web报表工具的制表效率分析

