
java线程基础巩固---分析Thread的join方法详细介绍,结合一个典型案例
关于Thread中的join方法貌似在实际多线程编程当中没怎么用过,在当初学j2se的时候倒时去学习过它的用法,不过现在早已经忘得差不多啦,所以对它再复习复习下。
首先先观察下JDK对它的介绍:

其实就是等待一个线程结束,对它记忆中还是有印象的,下面实践一下:
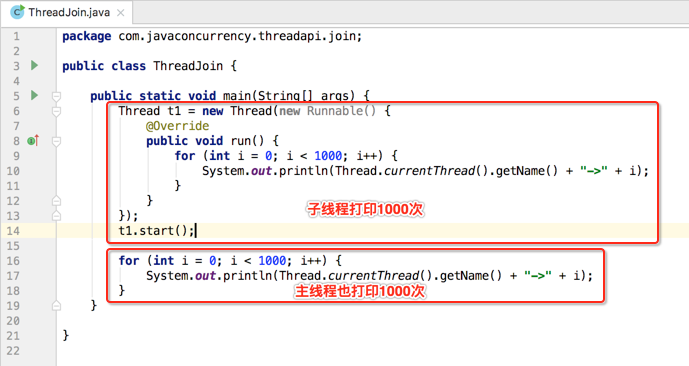
这时很显然打印是交替进行的:
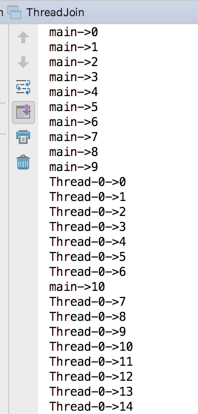
那如果我们想让子线程执行完了之后再执行主线程呢?这时就可以用join来实现啦,如下:

这时结果就是先输出子线程的,然后再输出主线程的了,那join的主要作用就是会等待线程执行完,另外需要注意:join()必须是在start()之后:

接下来对其代码进行修改:

那t1和t2打印结果会是顺序的么,也就是只有t1打印完了才会打印t2?看结果:
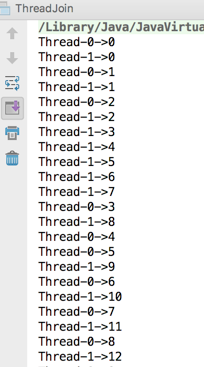
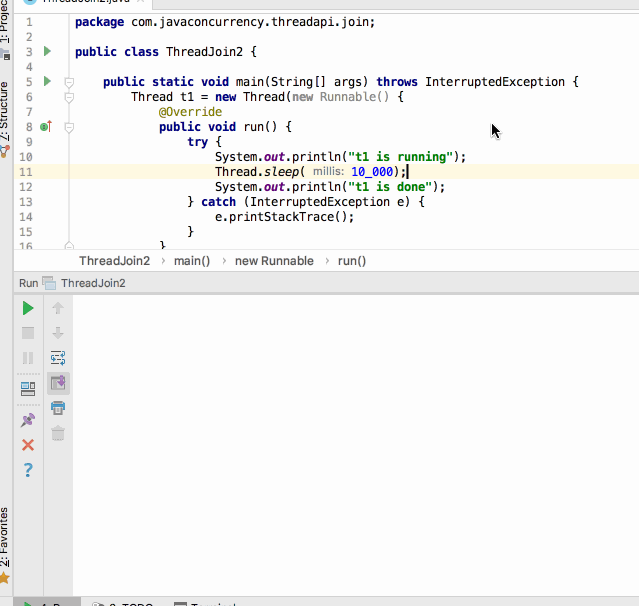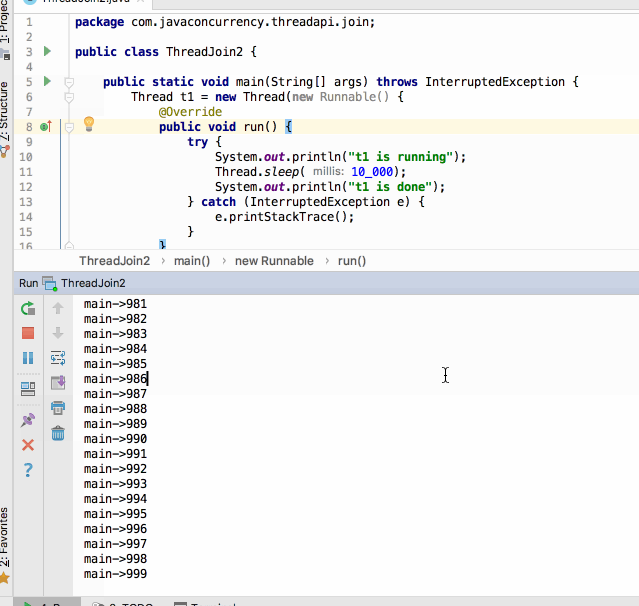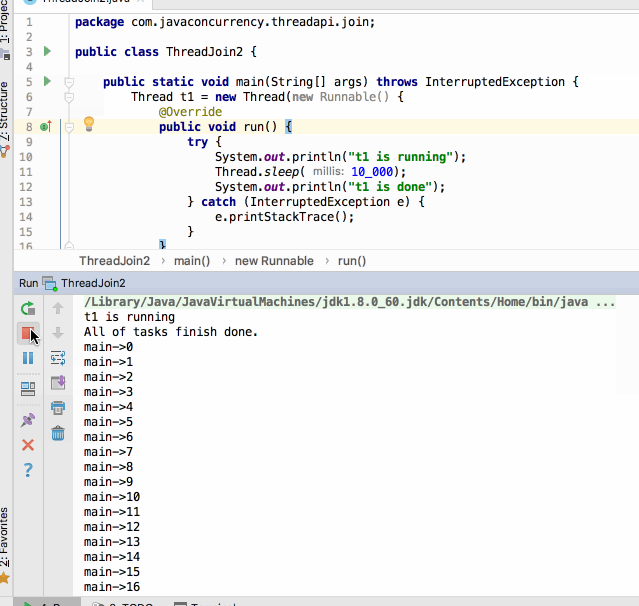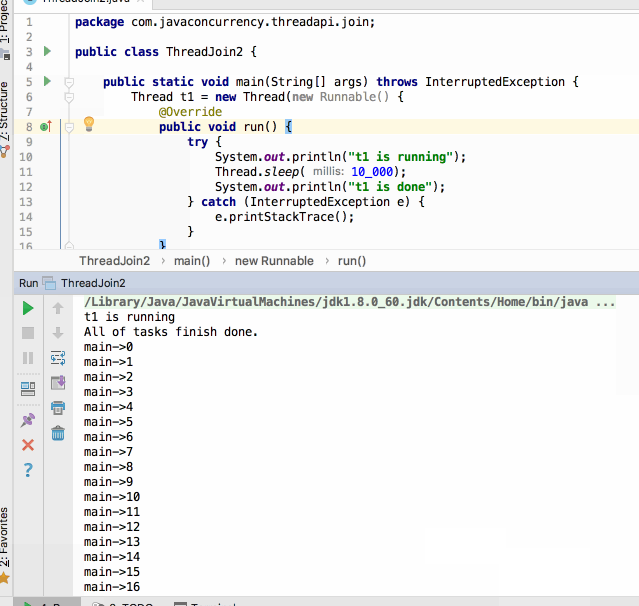
很显然是并行交替执行的,但main线程是在等t1和t2线程结束之后再执行的么?这个应该比较容易猜到,当然是啦:
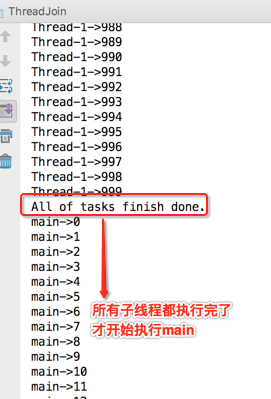
接下来用一下join()的另外两个重载:

这时编译运行:
可以看到只等了100ms程序就开始往下执行main线程了,并且当子线程过了10s之后程序才退出,当然也可以给join传入一个ns:

具体就不运行了,这里看下面这种写法:
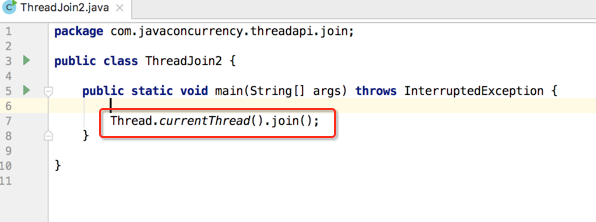
那运行之后会怎样?
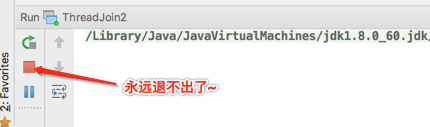
这是由于join()在等main线程退出,但是main线程又由于这句话永远退不出,所以就死循环了,这个在有些场合会用得到,先对这种写法有个大致的印象。
接下来通过一个小案例进一步来体会下join的用法:就是分别采集不同服务器的数据,而每台服务器数据的采集由一个单独的线程进行处理,每采集一条数据则需要将这数据进行入库,其中统计总数据采集的开始时间与结束时间,下面用代码来模拟下:
public class ThreadJoin3 { public static void main(String[] args) throws InterruptedException { long startTime = System.currentTimeMillis(); Thread t1 = new Thread(new CaptureRunnable("M1", 5000L)); Thread t2 = new Thread(new CaptureRunnable("M2", 7000L)); Thread t3 = new Thread(new CaptureRunnable("M3", 10000L)); t1.start(); t2.start(); t3.start(); long endTime = System.currentTimeMillis(); System.out.printf("Save data begin time is:%s, end time is:%s\n", startTime, endTime); } } /** * 采集数据的业务代码 */ class CaptureRunnable implements Runnable { /* 采集的机器名 */ private String machineName; /* 采取花费的时间,直接由外部传过来模拟了 */ private long spendTime; public CaptureRunnable(String machineName, long spendTime) { this.machineName = machineName; this.spendTime = spendTime; } @Override public void run() { //do the really capture data; try { Thread.sleep(spendTime); System.out.printf(machineName + " completed data capture at time [%s] and successfully.\n", System.currentTimeMillis()); } catch (InterruptedException e) { e.printStackTrace(); } } public String getResult() { return machineName + " finish."; } }
编译运行:
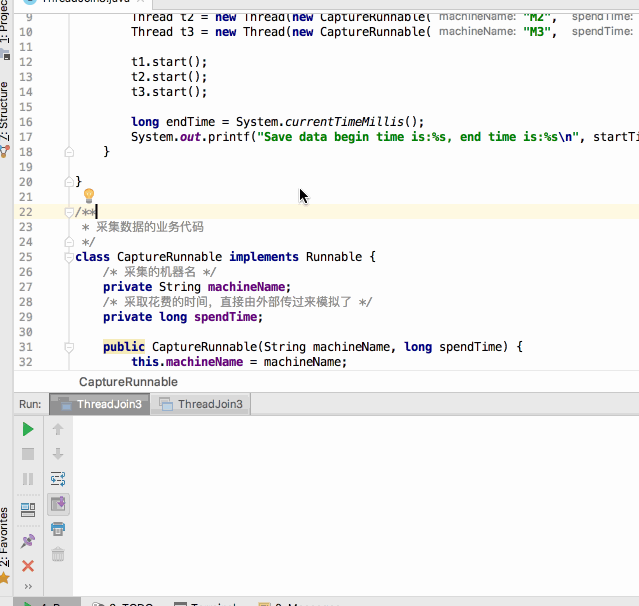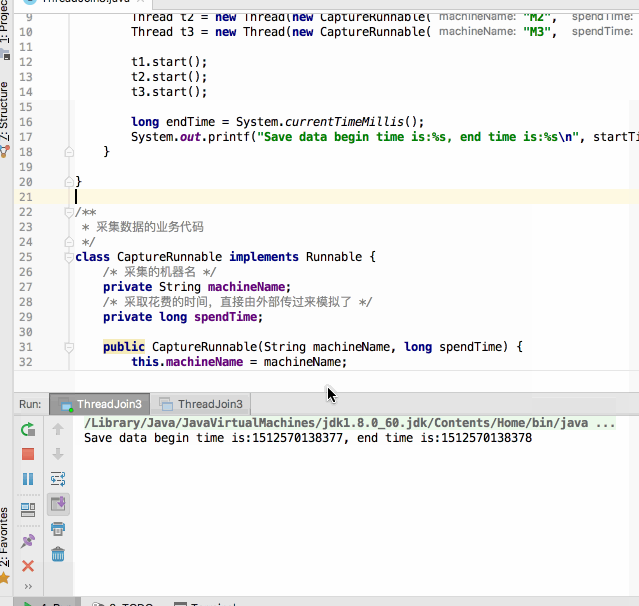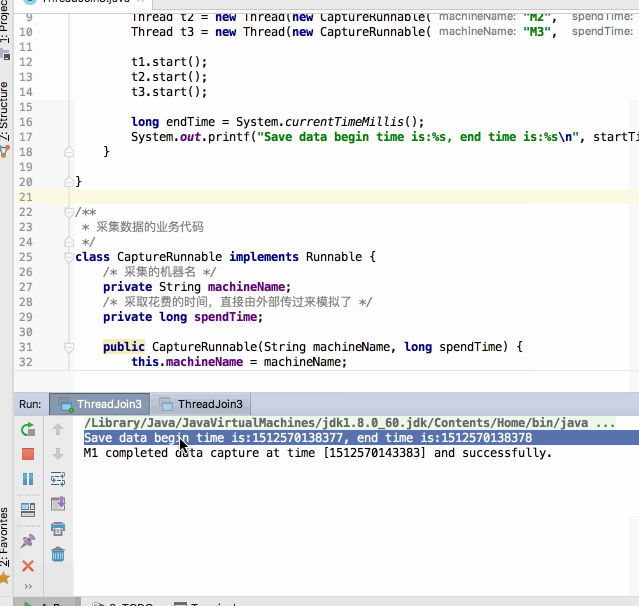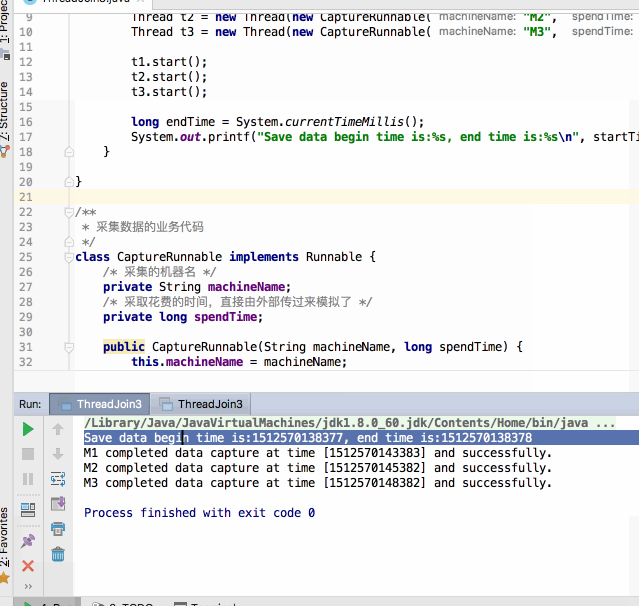
呃~~还没运行完其统计的开始时间与结束时间就已经提前打印出来了,那不是我们期望的,这时join()就可以很好的解决这个问题啦,修改代码如下:
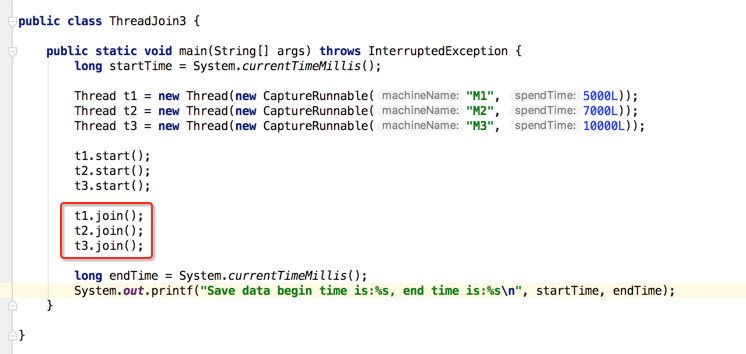
编译运行:
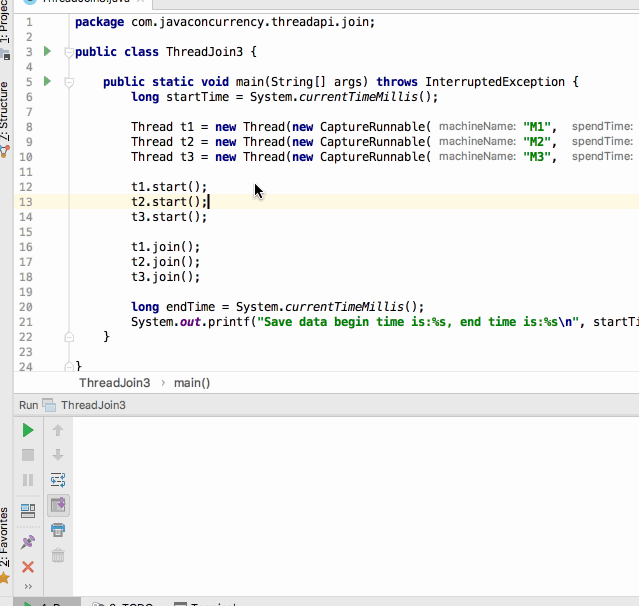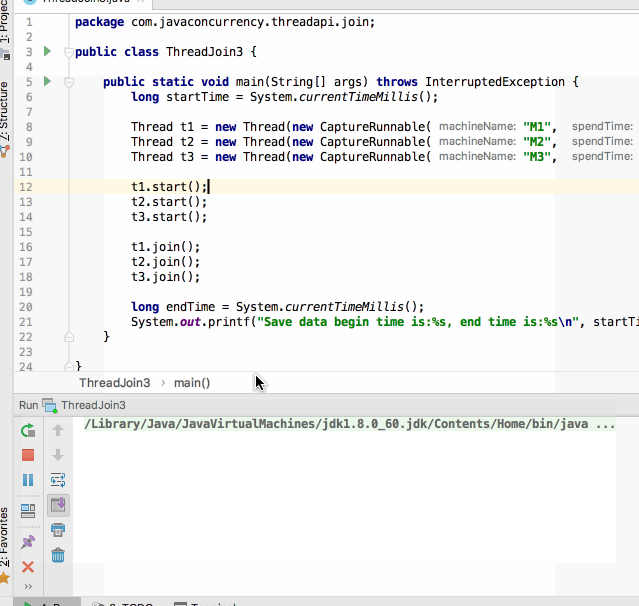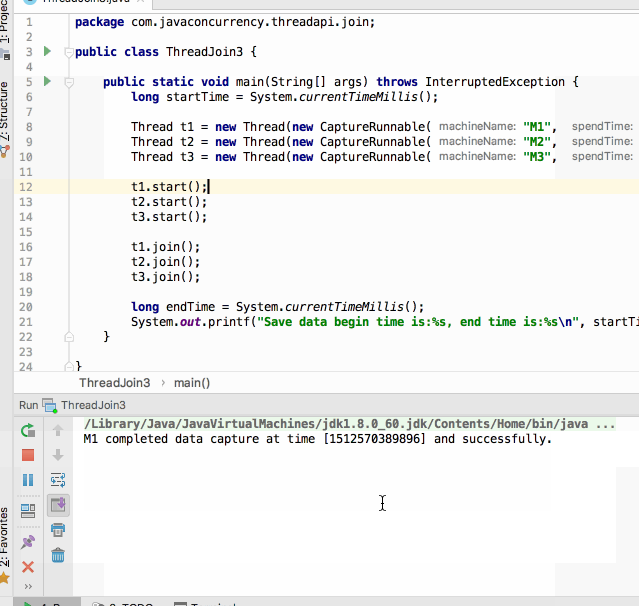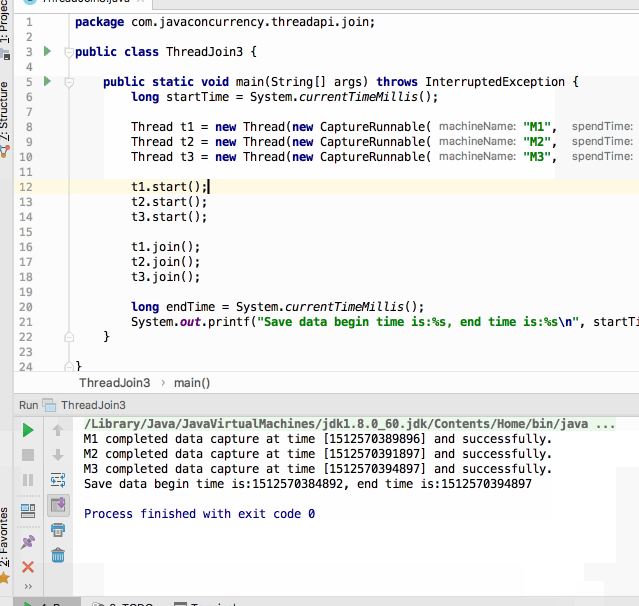
嗯~~完美解决~~


