

文件
文件打开方式
f = open(file='文件路径+文件名', mode='打开方式', encoding='文件编码') # 打开 #操作 pass f.close() #关闭
打开方式:'r'(读)、'w'(写)、'a'(追加),默认以'r'方式打开
以'r'打开,只能读不能写
以'w'打开,只能写不能读,如果文件不存在则创建文件,如果文件已存在,则清空重写,慎用
以'a'打开,追加写,打开文件在文件的末尾追加写入内容
f = open('yesterday.txt','a',encoding = 'utf-8')#文件句柄
使用('a')append可以在已存在的文件里写入,不可读
使用('w')创建一个新文件来写入,不可读,如果文件已存在,清空重写
使用('r')读取文件,不可写入
使用('r+')读,追加可写,常用
使用('w+')写读,没用
使用('a+')追加可读
以'a+'打开,文件指针位于末尾,如果要读需要先移动指针
使用('rb') 用于二进制文件,不传encoding参数#用于网络传输
使用('wb') 二进制写,不传encoding参数
f = open('yesterday.txt','r+',encoding = 'utf-8')#文件句柄 data = f.read() data2 = f.read() print(data) print(data2) # 读过一次之后光标移动到读过的内容的最后, # 再次读,只能读光标之后的内容 # 所以第二次读文件没有输出 f.write('-----data2-------') f.write('\nabc') print(data) f.close()
可指定读取字符数


1 f = open('yesterday.txt','r+',encoding = 'utf-8')#文件句柄 2 data = f.read(4) 3 data2 = f.read() 4 print(data) 5 print('*********') 6 print(data2) 7 8 >>>:-啊-- 9 ********* 10 --data2------- 11 abc 12 13 文件 14 -啊----data2------- 15 abc
逐行读取
for line in f: print(line.strip())
文件打开with模式,自动关闭
with open('yesterday.txt',encoding = 'utf-8') as c: a = c.read() print(a) 默认r方式打开
文件编码问题:文件以什么编码写入,就要以什么编码读取,否则会乱码
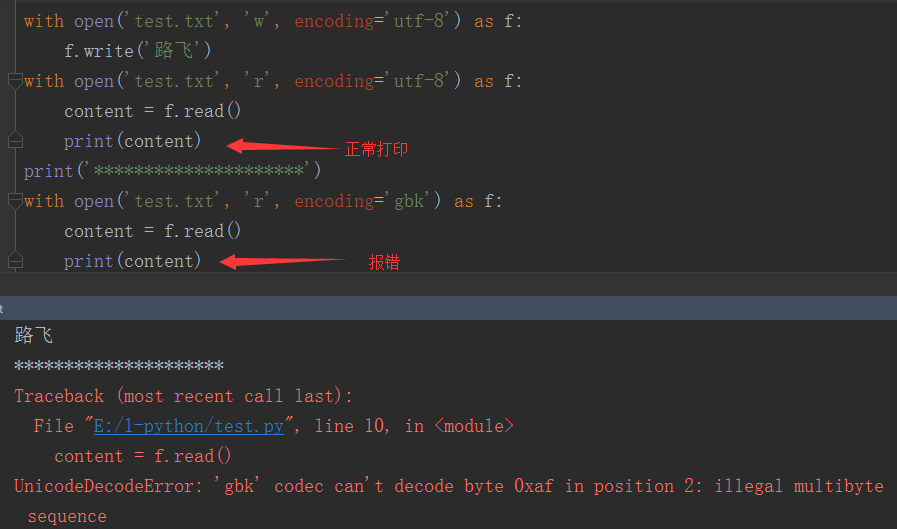
如果不知道文件是以什么编码写的怎么办?
import chardet # 第三方工具 with open('test.txt', 'rb') as f: # 必须以二进制模式打开 content = f.read() result = chardet.detect(content) print(result) 返回结果: {'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}
其他
print(f.readline())#返回一个生成器,调用一次读一行 print(f.tell())#.tell()查找光标位置 f.seek(0)#.seek()把光标移到指定位置,然后可再次读取 print(f.readlines())#整个文件以列表形式返回,一行为列表的一个元素 print(f.encoding)#.encoding()打印文件编码 print(f.name)#打印文件名字 print(f.seekable())#判断文件是否能移动光标 print(dir(f.flush())) #刷新,没什么用 a=f.truncate(x)#从文件第一个字符开始截取x
遍历文件
f = open('yesterday.txt','r',encoding = 'utf-8') 1.高效方法 count = 0 for line in f: if count == 9: print('------') else: print(line) count += 1 2.low方法 #print(f.readlines())#f.readlines()把文件生成列表,但是占内存 for index,line in enumerate(f.readlines()):#找列表元素的索引 #f.readlines()只适用于小文件,太占内存 if index == 9: print('-------') continue print(line.strip())
缓慢输出(进度条)
import sys,time for i in range(20): sys.stdout.write('#') sys.stdout.flush() time.sleep(0.1)
文件修改
一、占硬盘方式(读到硬盘上修改)
import os f = open('yesterday.txt','r',encoding='utf-8') f_new = open('yesterday2.txt','w',encoding='utf-8') for line in f: if 'radio,' in line: line = line.replace('radio','---') #对部分进行修改 f_new.write(line) f.close() f_new.close os.rename('yesterday2.txt','yesterday.txt') #把新文件名替换成旧文件名,并删除旧文件
二、占内存方式(读到内存上修改,如果文件太大,此方法不适用)
with open('alex.txt', 'r+', encoding='utf-8') as f: content = f.read() # 文件内容全部读到内存,返回字符串,不能逐行遍历 if 'alex' in content: content = content.replace('alex', 'a') f.seek(0) # 指针移动到文件头位置 f.truncate(0) # 文件字节长度发生变化,需要把文件清空重写 f.write(content)
f.seek(0)和f.truncate(0) 联合使用

