
CS231n 2016 通关 第二章-KNN
 2、KNN
2、KNN首先是KNN中用到的距离计算公式,L1和L2如下:

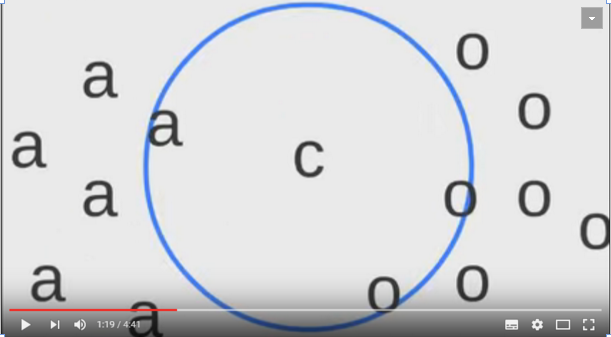
图示KNN的计算过程:
图中有种类 a o,当需要确定c属于哪个种类时,可以使用KNN


计算c到所有a和所有o的距离,L1或者L2均可。如图示取K为3,即取到3个较小值。

因为较小值中包含在o种类的数量多,所以确定c种类为o:
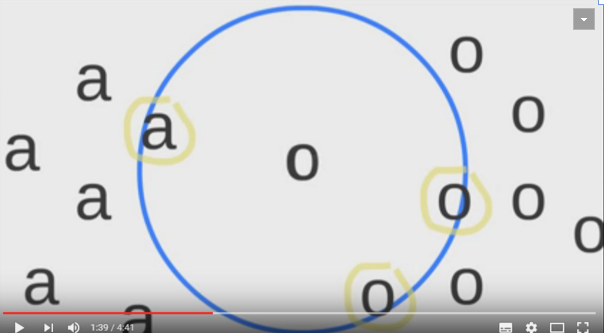
当K为1时,即为最近邻。同时KNN需要注意的点:
1.取K为奇数
2.K个较小值中尽量包含少的种类
3.在实际中需要权衡训练时间和测试时间,最近邻不需要训练时间,但是需要很多的测试时间。


可以使用KNN运算库:ANN 来进行计算。在数据可视化中会使用KNN.
reference:https://www.youtube.com/watch?v=UqYde-LULfs
2.3 cross-validation 交叉验证
KNN中K的取值是不确定的,称之为hyperparameter,即超参数。通过cross-validation即交叉验证的方式来选取合适的K值。
选取validation集:将原始训练集拆分成多个数据集合,使用其中之一作为验证集。
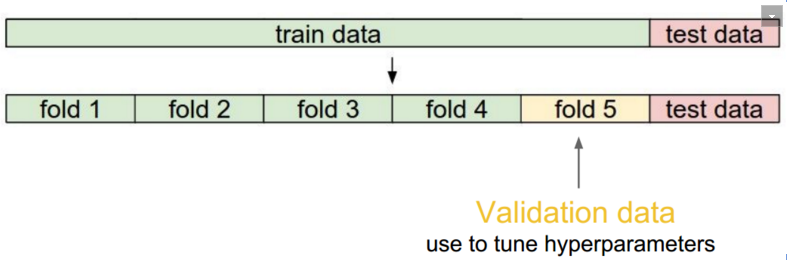
验证过程:选取K后,对验证集进行计算,得到不同验证集上的准确率,对准确率取平均值,平均准确率较好的K值为合适的超参数。

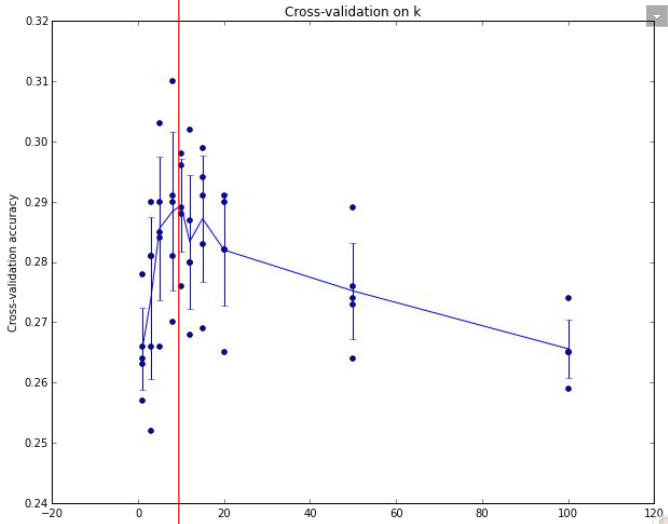
绘制准确率曲线,得到合适的超参数:此处选择K = 7
当然最重要的是课程的最后总结:

瞬间爆炸。。。
3、线性分类器
所谓线性分类器,是对输入数据进行线性的计算,最终得到预测label的概率值:

参数设置:注意此时加了bias也就是截距 b:

对线性分类器进行分类界面的可视化:
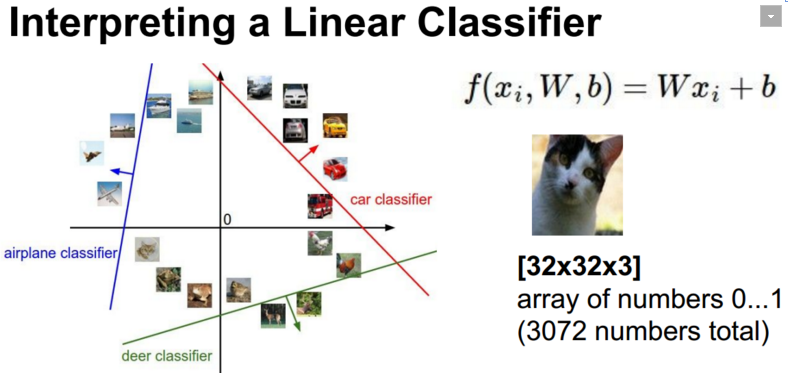
那么问题来了:解释加bias的原因?
如果没有bias,所有的分类界面均经过原点。可区分性降低。
bias在CNNs中也会使用。原因类似。
线性分类器总结:
图片来源:CS231n winter 课件。
附:通关CS231n企鹅群:578975100 validation:DL-CS231n
