
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
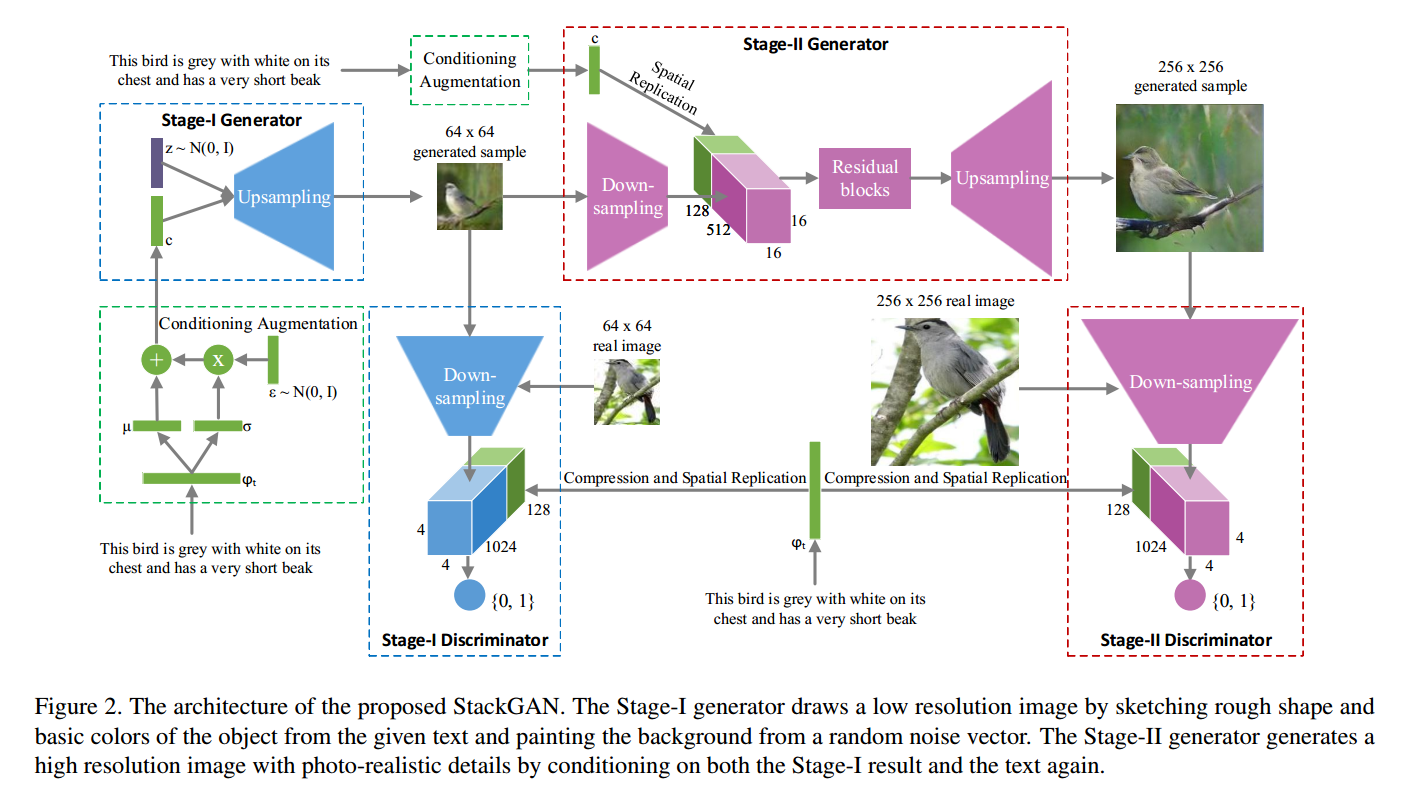
本文将利用 GANs 进行高质量图像生成,分为两个阶段进行,coarse to fine 的过程。据说可以生成 256*256 的高清图像。
基于文本生成对应图像的工作已经有了,比如说 Attribute2Image,以及 最开始的基于文本生成图像的文章等等。

Stacked Generated Adversarial Networks.
所涉及到的两个阶段分别为:
Stage-I GAN:基于文本描述,我们得到初始的形状,基础的色彩;然后从随机 noise 绘出背景分布,产生低分辨率的图像;
Stage-II GAN:通过在此的结合文本描述,进行图像的细致化绘制,产生高质量的 Image。
为了缓解条件文本描述 t 产生的高维的 latent space,但是有限的训练数据,可能导致 latent data manifold 的非连续性,
这对于训练产生器来说,可能不是很好。
为了解决这个问题,作者引入了 条件增强技术 来产生更多的条件变量。从一个独立的高斯分布 N 中随机的采样 latent variables,其均值 $\mu$ 和 对角协方差矩阵 是 text embedding 的函数。所提出的公式可以进一步的提升对小的扰动的鲁棒性,并且在给定少量 image-text pairs 的条件下,产生更多的训练样本。为了进一步的提升平滑性,给产生器的目标函数,添加了一个正则化项:

其中,上式就是 标准高斯分布 和 条件高斯分布的 KL-散度。
基于高斯条件变量 c0,阶段一的 GAN 迭代的进行两个目标函数的训练:

第二个阶段的 GAN 和第一阶段的非常类似。

不同的地方,在于产生器不再以 noise Z 作为输入,而是 s0 = G0(z,c0)。





整体来说,个人感觉并没有太多的创新,不过这个实验结果,的确是非常 impressive。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号