
【AKKA 官方文档翻译】为什么现代系统需要一个新的编程模型
为什么现代系统需要一个新的编程模型
akka版本2.5.8
版权声明:本文为博主原创文章,未经博主允许不得转载。
actor模型是由Carl Hewitt在数十年前提出的,这个模型提供了一种在高性能网络中进行并行处理的方式,然而这种环境在当时还尚不存在。现如今,硬件和基础设置的性能已经达到并超越了Hewitt的愿景。一些组织在构建具有苛刻要求的分布式系统时经常会遇到挑战,这些问题已经无法使用传统OOP编程模型来完全解决。这种情况下,他们可以在actor模型中获得帮助。
现在actor模型已经成为了一种公认的高效解决方案,并且在一些要求最苛刻的系统中得到了证明。为了体现actor模型的价值,本节主要讨论在现代多线程、多CPU结构之上使用传统编程手段的一些问题。
封装的挑战
OOP编程的核心是封装。封装要求对象内的数据不能被外部直接访问,它们只能通过方法调用被改变。对象有义务对外提供安全的操作方法以维持其内部封装数据的特性。
例如,一个有序二叉树的操作不能改变其内部元素顺序不变的性质,在做树的查询时,调用者会依赖这些性质进行程序的操作。
当我们分析OOP运行时的行为时,我们可以绘制以下的信息序列图来表现方法的调用:

不幸的是,上面的图并不能准确地表示程序生命周期的执行过程。实际上,这些程序是在单线程上执行的,并且这些OOP内部不变特性的执行发生在调用该方法的相同线程上,图表中加入执行线程如下:

当我们尝试使用多线程进行建模时,我们会发现我们的图表变得不那么合适了。以下是多线程同时访问同一个示例的图表:

有两个线程同时调用了同一个方法。但是在这种情况下,对象的封装模型并不能保证该调用得到预期的结果。两个线程执行的指令可能以任意的方式进行交错,因此在没有正确协调两个线程的情况下,对象的内部不变特性在运行之后是不可预知的,更不用说在多个线程同时调用下的结果了。
通常情况下,为了解决这个问题,我们会为这个方法添加一个锁。锁可以保证在任何时刻只会有一个线程进入这个方法。但是这是一种很消耗资源的策略:
1、锁严重限制了线程的并发。加锁在现代CPU架构上是一个很消耗资源的方式,需要操作系统挂起线程在之后进行恢复,这对操作系统来说是一个重担。
2、调用线程会被阻塞,因此这个线程在这段时间内不能去做其他工作。即使在桌面应用程序中,这也是不可接受的。我们希望在后台即使有耗时很长的程序运行情况下,用户界面也可以响应。对后端而言,线程阻塞是一种极大的浪费,有人认为这个情况可以通过启动一个新的线程来进行补偿,但是线程也是一个昂贵的抽象。
3、锁会引入一个新的威胁:死锁
这些问题导致出现了一些纠结的情形:
1、如果没有足够的锁,状态会被多线程破坏
2、如果加入了大量的锁,程序的性能会受到很大的影响,并且很容易产生死锁。
另外,锁只能在本地很好地运行。当我们涉及到多台机器协作时,唯一的办法只能是使用分布式锁。不幸的是,分布式锁的效率要比本地锁低几个数量级,并且通常情况下对机器的扩展性限制很大。分布式锁协议需要在多台机器之间通过网络进行多次往返通信,因此延迟会飞速增长。
在面向对象语言中,我们很少会去考虑线程的执行路径。我们经常将系统设想为一个对象实例的网络。它对方法调用作出反应,并修改它们的内部状态。然后通过方法调用相互通信,从而驱动整个应用程序运行:

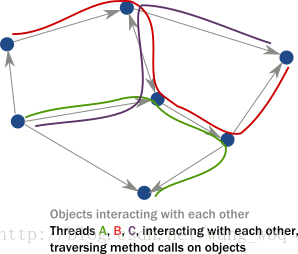
然而,在多线程分布式环境下,线程像下图一样通过方法调用来“遍历”对象实例网络。结果线程成为真正的程序驱动:
总结:
1、对象只能在单线程访问时保证封装(保护其内部不变特性),多线程执行几乎总是导致内部状态的破坏。对象内部的不变特性可能被两个执行同一代码的竞争线程改变。
2、在当前看来,锁似乎是维护多线程先对象封装的自然选择。但实际上它们效率低下,并且它们很容易导致死锁。
3、锁工作在本地,试图把他们扩展到分布式系统中,但是限制了扩展能力。
在现代计算机体系结构上共享内存的错觉
在80-90年代的编程模型的概念中,写入一个变量意味着直接写入内存中的一个地址(局部变量可能只存在于寄存器中)。在现代架构上,我们稍微简化一下,CPU写入缓存(cache line)中而不是直接写入内存。大多数这些高速缓存是存在于CPU核心本地的,也就是说一个核写入的数据是对其他核不可见的。为了使内核的本地修改对其他核可见,从而可以对其他线程可见,需要将高速缓存传送到另一个内核的高速缓存中。
在JVM上,我们必须通过使用volatile标记或者Atomic包来明确指出这些内存地址是要被线程间共享的。否则,我们只能使用锁在临界区访问它们。这么看来为什么我们不把所有的变量都声明为volatile变量呢?因为在不同的核之间传递缓存是非常昂贵的操作,这会潜在地拖慢所涉及到的核心的运行,并导致高速缓存一致性协议的瓶颈(CPU使用这个协议在主存储器和其他CPU间传递高速缓存行),最终导致的运行效率剧烈下降。
即使开发人员意识到这种情况,在何处使用volatile或者何处使用atomic结构依旧是个难题。
总结:
1、再也没有真正的共享内存了。CPU内核就像网络上的计算机一样,将数据块(缓存行)显式地传递给对方。CPU间的通信和网络通信有很多共同之处。它们通过标准来传递消息。
2、更好的方法是在线程本地保持状态,并且使用可并发的对象发送信息的方式向其他线程显式地传递数据或事件。用这种方式替代一些volatile标记和atomic结构是更好的选择。
调用堆栈的错觉
今天,我们经常使用堆栈结构,但是它们是在一个并发编程并不重要的时代发明的,因为在那时候多CPU系统并不常见。堆栈不会被跨线程调用,因此不需要模拟异步调用链。
当线程打算将任务委托给一个“后台”时出现了问题。实际上,这意味着任务委托给了另一个线程。这种委托和方法调用是不同的,因为方法调用是严格在同一个线程本地进行的。我们经常看到调用者将一个对象放入一个和工作线程共享的内存位置,然后工作线程在某个事件循环中进行拾取。这允许调用者线程不被阻塞继续进行内其他的任务。
但是我们要如何通知调用者该任务已经完成了?并且,如果一个任务失败并且产生了一个异常,则会出现更严重的问题。异常会传播到什么地方?它将传播到工作线程的异常处理程序里,完全忽略调用者是谁:
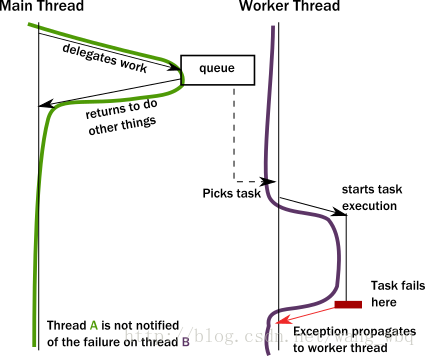
这是一个严重的问题,工作先称该如何处理这种情况?因为它通常不知道这个失败的任务是为了做什么。这时需要通过某种方式通知调用者,但是没有调用堆栈来解除异常。失败通知只能被另外的通道处理,例如把错误码放在调用者取结果的地方。如果这个结果没有放到位,调用者就永远得不到任务失败通知,从而导致任务丢失。这种情况与联网系统的工作方式非常相似,即消息/请求可能在没有任何通知的情况下丢失/失败。
当真正的错误发生或者运行在线程上的工作者由于bug导致不可恢复的失败时,情况会变得更糟。举例来说,当一个bug引起一个内部的异常,并且异常冒泡到线程根部导致线程关闭。问题来了,应该由谁来重启这个线程所运行的服务?怎样恢复它到一个正确的状态?这看起来似乎是可以解决的,但是还有另一个问题,线程失败的时候正在运行的这个任务、其运行状态已经完全丢失了,我们丢失了一个信息,即使这是一个本地通通信,没有涉及到网络。
总结:
1、为了在当今系统上实现好的并发,线程需要使用高效的方式来给其他线程委托工作,并且不被阻塞。在这种使用任务委托方式进行并发(在网络化/分布式计算中更是如此)调用情况下,基于堆栈的错误处理将会崩溃,一个新的明确的错误信号机制需要被引入。失败需要成为领域模型的一部分。
2、工作委托下的并发系统需要处理服务故障,并且有方法去恢复它们。这些服务的客户端需要知道在重新启动期间,任务/消息可能会丢失。即使没有丢失,响应也可能会被之前很长的任务队列、GC等延迟。面对这些情况,并发系统需要像网络/分布式系统一样加入超时机制来处理响应的期限。
接下来,让我们一起看看actor模型是如何应对这些挑战的。

