

java
● static方法为什么不能访问普通方法?
因为访问普通方法实际上是通过this来调用的,this代表本方法的对象,而static方法是类的方法,不专属于某个对象,因此通过this找不到对象
● 字符编码与字符集
字符集:通常的字符集是指字符的集合,例如,汉字的集合,是一个字符集。数字的集合也可以构成一个字符集。
编码字符集:有一堆字符的集合,并且为每个字符提供一个代码值。例如假设字符集为{1,2,中,国},为这个字符集中的每个字符提供一个代码值,例如,它们分别对应100,101,102,103。则就形成了一个编码字符集。一个常见的编码字符集是Unicode,它为世界上所有国家使用的字符(组成一个字符集),都提供一个唯一的代码值。除此之外,还有ASCII、GB2312,GBK等。
字符编码:以Unicode字符集为例,每个字符都对应一个代码值。但是只有这个代码值是不够的,因为如果将这些代码值存储在磁盘内,是无法区分字符的。这个原因是,有些字符只需要一个字节就能够表示,有些字符需要2~4个字节才能够表示,如果对每个字符统一使用4个字节来存储,会浪费存储空间。所以我们就想办法,让有些字符用1个字节存储,有些字符用2个,有些用3个……,原则是,只要能够区分字符,尽量用最少的字节来存储每个字符。这样就出现了字符编码。例如,对于Unicode字符集,使用UFT-8的编码方式,就可以实现字符的存储。在UTF-8中,英文字符占1个字节,汉子占两个字节,其他字符可能占3~4个字节。每个Unicode字符,假设它的代码值是x,它使用UTF-8编码后,会得到一个新的代码值y,这两个代码值,是很容易相互转化的。java语言,字符在内存中都以Unicode代码值(x)存储。当它写入磁盘后,如果文件指定的字符编码方式是UTF-8,则会转化成对应的UTF-8代码值(y)后再存储。此后,如果把这个字符从磁盘读取到内存,会发生UTF-8代码值(x)到Unicode代码值(y)的转化。
代码点:每个字符对应的Unicode代码值
代码单元:两个字节
Java使用UFT-16编码方案来编码字符(在内存中)。最早16位(一个代码单元)就可以表示所有字符,16位不够用,就出现了增补字符。所以UTF-16使用一个或两个代码单元来编码字符,用一个代码单元来表示16位能够表示的,不能够表示的,就使用两个代码来表示。
代码点在U+0000到U+FFFF之间的字符集被称为基本多语言面(BMP),在U+10000至U+10FFFF范围之间的字符称为增补字符。
字符串的length()方法返回的是代码单元的个数,而不是字符的个数。有些字符不止一个代码单元,所以使用length方法返回的结果可能会与我们想象的不一样。如果要返回字符的个数可以用str.codePointCount(0, str.length()),返回指定位置的字符可以使用str.codePointAt(i),codePointAt返回的是int型,而不是char,因为增补字符不能够用char表示
参考:https://www.cnblogs.com/vinozly/p/5155304.html
https://ygong.iteye.com/blog/1311811
https://blog.csdn.net/nlznlz/article/details/80950596
https://www.cnblogs.com/vinozly/p/5155304.html
● foreach
for可以用来遍历数组和集合
● 数组
数组也是一种数据类型,是一种引用类型。例如 int []。
定义应用数组变量时,不能指定长度:
int[] a; //正确
int[2] a; //错误
静态初始化:
int[] a = {1, 2}; //静态初始化。这种方式,只能是定义的时候同时初始化。
int[] b;
b = new int[]{1, 2}; //静态初始化。这种方式,可以先定义,再初始化。
动态初始化:定义的时候,只指定数组的长度。系统会自动为每个元素分配初始值:
String s[] = new String[2];
Object Obj[] = new String[3];

每个数组都有一个length成员,指明数组的长度。
数组变量存储在栈区,数组元素存储在堆区。位于栈区的引用变量,引用位于堆区的数据。
如果堆内存中的数组不再有引用变量引用它,则会被垃圾回收机制回收。所以如果要让垃圾回收机制回收一个数组的空间,可以将该数组引用变量赋为null。
定义并初始化一个数组后,会分配两个空间:一个存放该数组引用变量,另一个存储实际的数组。
本质上,java没有多维数组。例如,int[][],可以看出int[]类型的一维数组,而int[]实际上是一个引用类型。因此java本质上只有一维数组。
二维数组的声明和初始化:
int[][] a = new int[2][];
a[0] = new int[3];
a[1] = new int[4];
java二维数组的存储排列
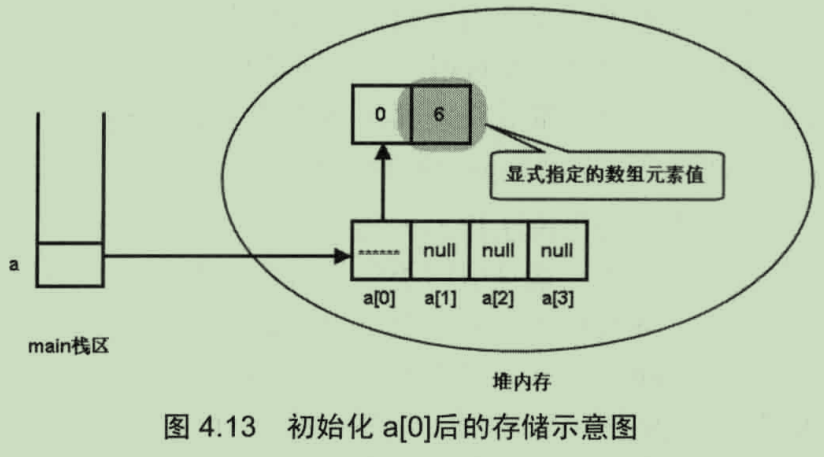
● break,continue
break label;可以跳出外层循环,只要把标签放到外层循环前面就可以
continue label;可以结束标签标识的外层循环的本次循环,只要把标签放到外层循环前面就可以
● 运算符
java中有以下几类运算符:
算术运算符;
赋值运算符;
比较运算符;
逻辑运算符;
位运算符;
类型相关运算符。
%:求余运算符,需要做一次除法,因此若两个操作数都是整数,则出生不能为0。若两个操作数不都为整数,则出生可以为0,求余的结果为NaN。
++:若++在变量左边,则先把变量加一,再放到表达式中参与运算。若在右边,则先放到表达式中参与运算,再加一。
++,--都只能操作变量,不能操作常量、直接量、表达式。
-:除减法运算符外,开可以作为求相反数的运算符。
位运算符:&、|、~、^、<<、>>、>>>

位运算符只操作整数。进行运算的时候,对补码进行运算
● 直接量
能指定直接量的类型只有三种:基本类型、字符串、null类型。
当程序第一次使用某个字符串直接量时,编译器会使用常量池来缓存该字符串,后面再使用到的时候,就直接从常量池中获取。(保存在静态存储区)
● 类型的自动提升
一个表达式中的各个操作数的类型会被自动提升到该表达式中最高等级的操作数的类型,因此表达式的值的类型就是最高等级的操作数的类型。(解释:int n = 4 / 3;)
例如下面的语句会产生语法错误:
byte b = 2;
b = b - 1;
● java为8种基本类型都提供了对应的包装类:Boolean、Byte、Short、Integer、Long、Character、Float、Double。每个包装类都有一个parseXXX,将字符串转换成基本数据类型
● 基本数据类型的转换
分为:自动转换和强制转换。
自动转换:把表示范围小的数赋给表示范围大的数,会完成自动转换
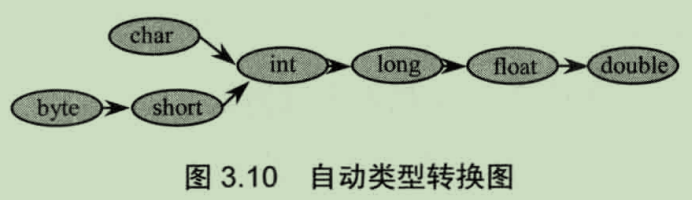
任何基本类型的值与字符串连接,都将转换成字符串。
● bool类型:boolean
boolean类型只有true和false两个值,且只能小写。
像if这种判断条件的地方,只能出现true和false两个值,不能像c语言那样,用0代表false,非0代表true。
Boolean主要用于流程控制:
if、while、do、for
● java 7以后,整数和浮点数的数字之间可以随意插入下划线:
int n = 12_23_5;
float f = -1.1_2f
只能在数字与数字之间,不能在开头和结尾,也不能在数字与小数点之间
● 浮点类型:float、double
浮点类型值默认为double,因此下面的语句会报错:
float f = 1.2;//错误
float f = 1.2f;//正确。
正浮点数除以0,得到正无穷大;
负浮点数除以0,得到负无穷大;
0.0 / 0.0, 得到NaN
整数除以0,会抛出异常
● 如果把一个没有超过char范围的int值赋给char变量,会自动转换成char型,不会报错:
char c = 97;
但如果如果超过char的范围,则会报错:
char c = 65536;//报错:将int转换到char可能会有损
● 字符型值的三种表示方式:
直接使用单个字符:'a';
通过转义字符表示特殊字符:'\n','\t';
使用Unicode值:'\uxxxx',例如'\u0061',代表'a'
● java使用16位的Unicode字符集。
Unicode为每个字符指定一个二进制代码。如果单纯将Unicode码存储在磁盘中,是无法区分字符的,因为不知道某个字符是一个字节还是多个字节。
UTF-8(包括其他编码方式,例如UTF-16)是Unicode的一种实现形式,它设计了每个字符在磁盘如何存储,使得可以区分哪些字节是属于同一个字符的(具体参考UTF-8的规则)。
getBytes(charset); 方法的作用是将字符串用charset的编码方式表示出来。它存储在磁盘中的编码方式可能不是charset
● java中整数的四种表示方式:
二进制:0b或0B开头;
八进制:0开头;
十六进制:0x或0X开头;
十进制:
byte n = 0b10000001;//这条语句会报错,因为0b10000001默认为int型,超出了byte的范围。
如果定义变量的时候用二进制、八进制、十六进制,则数值为变量在内存的实际存在形式(补码),需要转换成原码后才知道这个变量为多少:
byte n = 0b00000011;//0b00000011为补码,虽然整数的补码与原码相同;
int n = 0b10000000000000000000000000000011;内存中实际存储的就是0b10000000000000000000000000000011,它是一个负数的补码,转换成原码后才是它的真实值
● 直接给定一个整数n,默认为int。
但如果将n赋给byte和short类型的变量,如果n没有超过byte和short的表示范围,则编译器会自动把n当作byte和short类型来处理,不会报错。
如果n超过了int表示的范围,将n赋给long类型的变量,则会报错,因为n为int型。如果在n后面加一个l或L,直接指定这个数是long型,再赋给long型变量,就不会报错。
当n没有超过int范围,将n赋给long类型变量,则不会报错,因为n会自动转换成long类型。
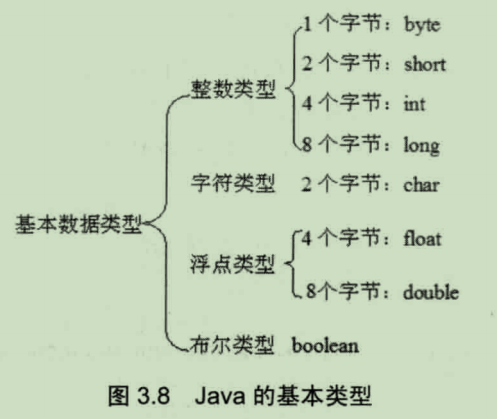
● 数据类型
数据类型分为:基本类型和引用类型。
基本类型分为:boolean类型和数值类型。
数值类型分为:整数类型和浮点类型。
整数类型包括:byte、short、int、long、char。
浮点类型包括:float、double。
引用类型包括:类、接口、数组、空类型。
空类型没有名称,所以不能声明变量。空类型变量只有一个唯一的值:null。可以将null看成引用类型的一个字面量,即空引用。null只能被转换成引用类型,不能转换成基本类型。
引用类型的变量存的是地址。
● 变量包括成员变量和局部变量
● 强类型的含义:1.变量必须先声明,后使用;2.变量只能接受对于类型的值
● 若要运行某个java类,则该类必须包含一个main方法
● java源文件命名
一个java源文件可能包含多个类,但最多只能包含一个用public修饰的类。如果有一个类被public修饰,那么源文件名必须和这个类的类名一致。如果不含有用public修饰的类,则源文件名可以是任意的。
● JDK1.5以后,编译和运行的时候,会自动搜索当前目录和lib\dt.jar、lib\tools.jar,因此可以不配置classpath环境变量。但如果配置了classpath,就会严格按照classpath来搜索类,所以如果这三项没有配置全,就可能会出错。所以,要么不配,要么配全。
● java程序运行机制
先编译,后解释。源程序先编译成字节码,再由java虚拟机解释执行字节码。
● javac命令

java执行:

● eclipse断点调试
打断点,右键源文件,选择debug as ,Java Application
● Class.forName(name)
用来动态加载名为name的类,并返回,如果该类有静态代码,则会执行。newInstance方法会创建一个对象。
Class c = Class.forName(name);
Object o = c.newInstance();
jdbc连接数据库的时候,会出现这样的代码:
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url, user, password);
并没有创建对象。
这是因为类com.mysql.jdbc.Driver已被注册到了DriverManager。
所以上面使用的DriverManager,实际上是com.mysql.jdbc.Driver这个类。
