
花样试用微软语音服务晓晓
 受微软美女员工 Grace Peng 邀请(也可能是套路???),参加微软神经语音(没错,就是神经)晓晓的试用,首先是看到了群里面的消息,然后就是发送申请,等待回复,过了几天后,收到了一个机器人发来的账号密码,告诉我已经帮我申请了免费试用的账号,直接登录即可使用了。其实一直都有接触各种 TTS 的服务,但是在测试微软晓晓的过程中发现,在拟人方面,晓晓的发音似乎被训练得很不错
受微软美女员工 Grace Peng 邀请(也可能是套路???),参加微软神经语音(没错,就是神经)晓晓的试用,首先是看到了群里面的消息,然后就是发送申请,等待回复,过了几天后,收到了一个机器人发来的账号密码,告诉我已经帮我申请了免费试用的账号,直接登录即可使用了。其实一直都有接触各种 TTS 的服务,但是在测试微软晓晓的过程中发现,在拟人方面,晓晓的发音似乎被训练得很不错
前言
受微软美女员工 Grace Peng 邀请(也可能是套路???),参加微软神经语音(没错,就是神经)晓晓的试用,首先是看到了群里面的消息,然后就是发送申请,等待回复,过了几天后,收到了一个机器人发来的账号密码,告诉我已经帮我申请了免费试用的账号,直接登录即可使用了。其实一直都有接触各种 TTS 的服务,但是在测试微软晓晓的过程中发现,在拟人方面,晓晓的发音似乎被训练得很不错,在语法方面,晓晓支持 SSML 语法,具体参见:https://www.w3.org/TR/speech-synthesis/ 什么是 SSML,来自百度百科 语音合成标记语言 的解释。
1. 准备工作
话不多说,马上开始,首先登录 Azure portal,
1.1 选择 “认知服务”,添加一个新的 Speech 订阅 命名为:MySpeechService
1.2 等待部署完成
1.3 Speech 部署完成后
点击左侧列表中的 “所有资源”连接,进入资源管理面板

1.4 选择资源,查看密钥
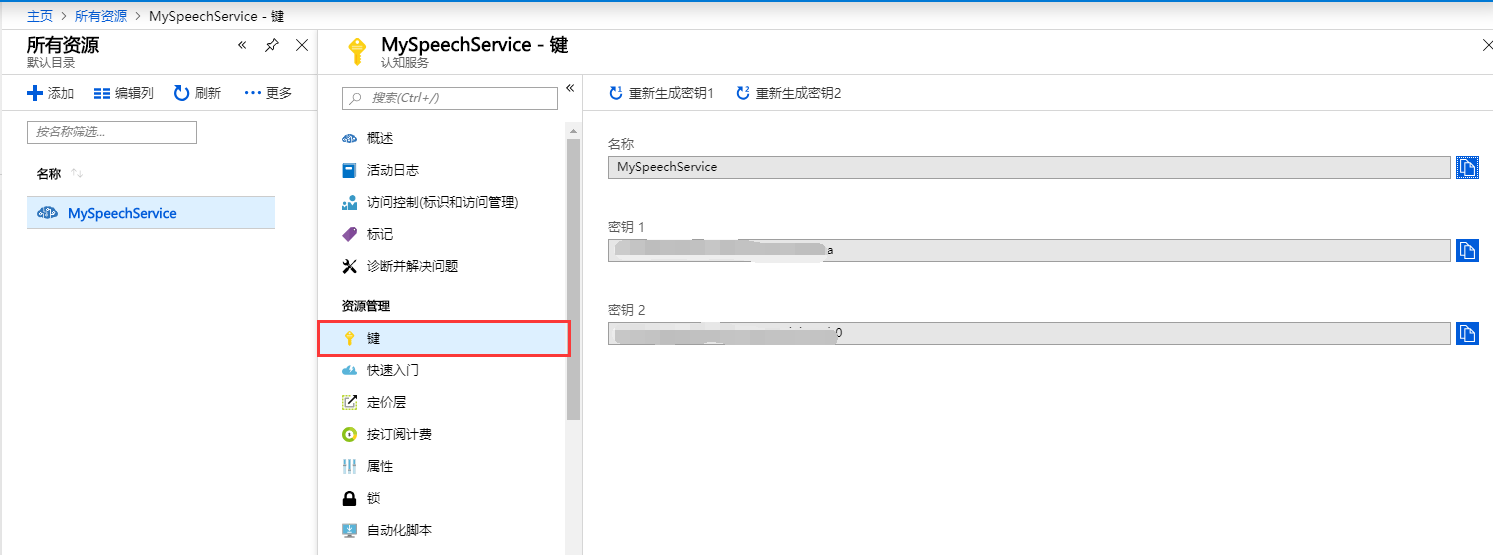
在资源面板点击刚才创建好的 MySpeechService,进入详情后点击 “键”(keys),可以看到已经生成好的密钥,等一下调用 Speech 服务的时候需要用到,好了,准备工作已经完成了,下面就写两行代码试试。
2. 开始试用
创建一个控制台项目:MySpeechApp,进行一些简单的编码工作,在正式编码之前,需要来了解一下调用流程
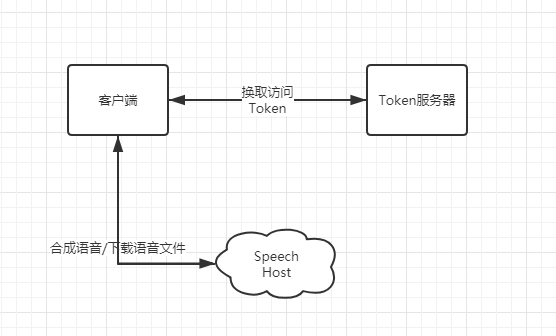
从上面的流程图可以了解到,首先,我们需要使用创建好的 Speech 服务中的密钥去换取访问 Token ,然后,使用 Token 调用 Speech 主机,传递文本,下载语音文件,整个流程结束。
- 注意:通过上面的流程,只能合成 10 分钟以内的语音文件。
好了,流程已经看懂了,下面正式开始编码。
2.1 定义公共的变量备用
class Program
{
private const string TOKEN_URI = "https://southeastasia.api.cognitive.microsoft.com/sts/v1.0/issuetoken";
private const string SUB_KEY = "36290bbded8f4cb59e34e50ed7be60b0";
private const string HOST = "https://southeastasia.tts.speech.microsoft.com/cognitiveservices/v1";
private const string RESOURCE_NAME = "MySpeechService";
}
TOKEN_URI:换取 Token 调用的 URL
SUB_KEY:资源密钥,就是 1.4 中的 键(keys)
HOST:Speech 主机,因为给我分配的是东南亚的,所以这里地区也必须选择 southeastasia,资源面板上也没有说明,一开始使用的是 westus ,总是提示身份验证异常,坑了好几分钟。
RESOURCE_NAME:资源名称,就是我们创建的服务名,这没什么好说的
2.2 换取访问Token
private static async Task<string> GetTokenAsync()
{
using (var httpClient = new HttpClient())
{
httpClient.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", SUB_KEY);
var builder = new UriBuilder(TOKEN_URI);
var result = await httpClient.PostAsync(builder.Uri.AbsoluteUri, null);
return await result.Content.ReadAsStringAsync();
}
}
代码比较简单,就是一个 Http 请求的封装而已,核心内容是 httpClient.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", SUB_KEY);,把资源密钥加入请求头中。
2.2 合成语音
private static async Task RequestSSML(string authToken, string text, string fileName)
{
Console.WriteLine("准备中...");
using (var httpClient = new HttpClient())
{
var body = "<speak xmlns=\"http://www.w3.org/2001/10/synthesis\" xmlns:mstts=\"http://www.w3.org/2001/mstts\" version=\"1.0\" xml:lang=\"zh-CN\"><voice name=\"Microsoft Server Speech Text to Speech Voice (zh-CN, XiaoxiaoNeural)\">" + text + "</voice></speak>";
var request = new HttpRequestMessage()
{
Method = HttpMethod.Post,
RequestUri = new Uri(HOST),
Content = new StringContent(body, Encoding.UTF8, "application/ssml+xml")
};
request.Headers.Add("Authorization", "Bearer " + authToken);
request.Headers.Add("Connection", "Keep-Alive");
request.Headers.Add("User-Agent", RESOURCE_NAME);
request.Headers.Add("X-Microsoft-OutputFormat", "riff-24khz-16bit-mono-pcm");
Console.WriteLine("正在进行远程过程调用...");
var response = await httpClient.SendAsync(request);
if (response.StatusCode != System.Net.HttpStatusCode.OK)
{
Console.WriteLine("The Response {0}", response.StatusCode);
return;
}
using (var stream = await response.Content.ReadAsStreamAsync())
{
stream.Position = 0;
Console.WriteLine("正在下载语音文件 {0} ...", fileName);
using (var fs = new FileStream(fileName, FileMode.Create, FileAccess.Write, FileShare.ReadWrite))
{
await stream.CopyToAsync(fs);
fs.Close();
}
}
Console.WriteLine("文本转换语音成功");
Console.WriteLine("===============\n");
}
}
这段代码也非常的简单,首先是构造一个 SSML 文件格式的 Body,并在请求头中加入 AuthToken 还有其它的一些头部标识,然后就开始正式的请求语音文件,最后将合成好的语音文件保存到本地。
2.3 开始调用过程
static void Main(string[] args)
{
var result = GetTokenAsync().ConfigureAwait(false).GetAwaiter();
string token = result.GetResult();
var text1 = "你好,我是来自博客园的技术爱好者 Ron Liang;很高兴可以试用 Speech,希望一切顺利。";
var task1 = RequestSSML(token, text1, "1.wav");
task1.ConfigureAwait(false).GetAwaiter().GetResult();
var text2 = "小哥哥,来一发<prosody rate=\"-40.00%\" volume=\"-80.00%\" duration=\"1.5s\">吗?</prosody>";
var task2 = RequestSSML(token, text2, "2.wav");
task2.ConfigureAwait(false).GetAwaiter().GetResult();
var text3 = "蒿嗨偶,肝绝忍僧衣襟捣打的高草,肝绝忍僧衣襟捣打了巅峰。蒿赠寒,蒿朵母,蒿悬猜。";
var task3 = RequestSSML(token, text3, "3.wav");
task3.ConfigureAwait(false).GetAwaiter().GetResult();
Console.WriteLine("按任意键退出");
Console.ReadKey();
}
上面有3段文本,对应合成3段语音,1和3是纯粹捣乱的,第二段文本中加入了SSML标记prosody,其属性表示:rate=-40%(降低语速),volume=80%(降低音量),duration=1.5s(延时1.5s)
2.3 按 F5 运行程序

非常完美的运行成功,我们得到了3个语音文件,分别是:
- 正常版:
- 你好,我是来自博客园的技术爱好者 Ron Liang;很高兴可以试用 Speech,希望一切顺利。
- 撩人版:
- 小哥哥,来一发
吗?
- 方言版:
- 蒿嗨偶,肝绝忍僧衣襟捣打的高草,肝绝忍僧衣襟捣打了巅峰。蒿赠寒,蒿朵母,蒿悬猜。
结束语
整体来说,在普通的语境环境下,晓晓的表现还是不错的,整体令人满意,但是在自定义 SSML 的时候,就非常的麻烦,我调整了不下30分钟,都没有达到一个令人满意的结果;当然,晓晓还有别的优点,比如可以自定义语音字体,你可以请声优来训练专业你自己的语音字体,只为你一个人服务。
代码托管在GitHub上了
https://github.com/lianggx/Examples/tree/master/MySpeechApp

欢迎关注收取阅读最新文章
好看点个推荐呗~
- 出处:http://www.cnblogs.com/viter/
- 本文版权归作者和博客园共有,欢迎个人转载,必须保留此段声明;商业转载请联系授权,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
- 欢迎大家关注我的微信公众号,一起学习一起进步

