


Hadoop2.6.0安装—单机/伪分布
目录
作者: vincent_zh
时间:2016-10-16
出处:http://www.cnblogs.com/vincentzh/p/5967274.html
声明:本文以学习、研究和分享为主,如需转载,标明作者和出处,非商业用途!
环境准备
此处准备的环境是Virtual Box虚拟机下的Ubuntu14.04 64位系统,Hadoop版本为Hadoop2.6.0。装好Hadoop运行的基础Linux环境后,还需要做以下准备:
- 创建hadoop用户;
- 更新apt;
- 配置SSH免密登陆;
- 安装配置Java环境。
创建hadoop用户
如果安装系统时配置的并非是“hadoop”用户,就需要新增加一个“hadoop”用户。
1 $ sudo useradd -m hadoop -s /bin/bash
该命令创建新的“hadoop”用户,并指定 /bin/bash 作为其shell。
如需更改hadoop用户密码,可通过如下命令进行:
1 $ sudo passwd hadoop
同样,为避免后期安装过程中的用户权限问题,可直接给“hadoop”用户添加上管理员权限:
1 $ sudo adduser hadoop sudo
之后,需切换到hadoop用户下进行下面操作。
更新apt
切换到hadoop用户之后,需要先更新一下apt,后续需要通过apt安装其他软件,直接在命令行安装会方便很多,如果没有更新,一些软件可能安装不了。可参考以下命令进行更新:
1 $ sudo apt-get update
Linux 的编辑工具,当然非 vim 莫属了,先装上 vim 后期改参数配置文件时用的到。
1 $ sudo apt-get install vim
遇到命令行的 [ yes/no] 或者 [Y/N] 选项,直接yes进行安装。
配置SSH免密登陆
单点/集群都需要安装SSH。一方面是远程登陆,可一再本机通过SSH直接连接虚拟机的系统,这样也便于后期在Windows环境下使用 Eclipse 进行配置开发 MapReduce 程序;另一方面,在配置Hadoop集群时,集群工作过程中主机和从机、从机和从机之间都通过SSH进行授权登陆工作通信。Ubuntu系统默认已经安装了SSH Client,需要额外安装SSH Server。
1 $ sudo apt-get install openssh-server
首次登陆SSH会有首次登陆提示,键入yes,按提示输入hadoop用户密码即可登陆。

配置免密登陆。一方面,我们通过ssh登陆时比较方便,不需重新输入密码;另一方面,在集群方式工作时,主机与从机通信过程或从机与从机之间进行文件备份时是需要越过密码验证这一环节的,所以需要提前生成公钥,在集群工作时,可以直接自动登陆。
1 $ exit #推出刚刚登陆的 localhost 2 $ cd ~/.ssh #若无此目录,请先进行一次ssh 登陆 3 $ ssh-keygen -t rsa #会有很多提示,全部回车即可 4 $ cat ./id_rsa.pub >> ./authorized_keys #将公钥文件加入授权
再次通过 ssh 登陆就不需要输入密码了。
安装配置Java环境
Java环境,Oracle JDK 和 OpenJDK都可以,此处直接通过命令安装OpenJDK1.7(其中包含 jre 和 jdk):
1 $ sudo apt-get install openjdk-7-jre openjdk-7-jdk
配置环境变量:
安装好JDK后,需要配置Java环境变量,通过以下命令寻找Java安装路径:
1 $ dpkg -L openjdk-7-jdk | grep '/bin/javac'
该命令会输出一个路径,除去路径末尾的 “/bin/javac”,剩下的就是JDK的安装路径了。

在.bashrc文件中配置环境变量:
1 $ vi ~/.bashrc
需要在.bashrc文件中添加如下环境变量:

生效并检验环境变量配置是否正确:
1 $ source ./.bashrc #生效环境变量 2 $ echo $JAVA_HOME #查看环境变量 3 $ java -version 4 $ $JAVA_HOME/bin/java -version #验证与java -version 输出一致
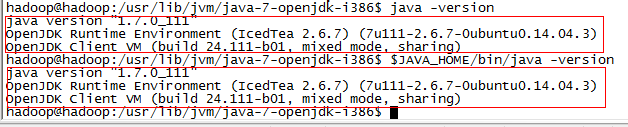
OK,Java环境安装配置完成。
安装Hadoop
通过http://mirrors.cnnic.cn/apache/hadoop/common/ 可下载Hadoop稳定版 hadoop-2.x.y.tar.gz 文件都是编译好的,建议同时下载hadoop-2.x.y.tar.gz.mds,此mds文件是为了检验在下载和移动文件过程中文件的完整性。
通过验证文件的md5值去检验文件的完整性:
1 $ cat ./hadoop-2.6.0.tar.gz.mds | grep 'MD5' 2 $ md5sum ./hadoop-2.6.0.tar.gz | tr 'a-z' 'A-Z'

文件验证无误,将文件解压到安装目录:
1 $ cd /usr/lcoal #切换到压缩文件所在目录 2 $ sudo tar -zxf ./hadoop-2.6.0.tar.gz ./ #解压文件 3 $ sudo mv ./hadoop-2.6.0 ./hadoop #将文件名改为较容易辨认的 4 $ chown -R hadoop ./hadoop #修改文件权限
在.bashrc文件中配置hadoop相关环境变量:
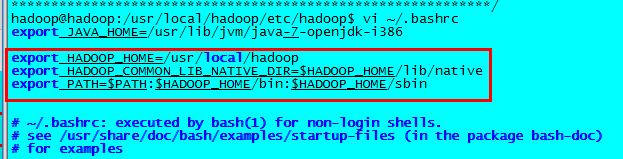
生效环境变量,并验证Hadoop安装成功。
1 $ source ~/.bashrc 2 $ hadoop version
Hadoop单机/伪分布配置
单机Hadoop
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
注:单机、伪分布、集群的区别:
单机:故名思意,Hadoop运行再单台服务器上,并且此时的Hadoop读取的是本地的文件系统,并没有使用自己的HDFS。
伪分布:单机版集群,单台服务器既是NameNode,也是DataNode,并且也只有这一个DataNode,文件是从HDFS读取。
集群:单机和伪分布说了集群就简单了。一般单独分配一台服务器作为NameNode,并且NameNode一般不会同时配置为DataNode,DataNode一般在其他服务器上,另外对大型集群,为体现Hadoop集群的高可用性,也会单独设置一台服务器作为集群的SecondaryNameNode,也就是NameNode的备份,主要用于NameNode失效时的快速恢复。
伪分布Hadoop
Hadoop 伪分布式的方式是在单节点上运行的,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件,Hadoop 进程以分离的 Java 进程来运行。
Hadoop 的配置文件位于 $HADOOP_HOME/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。另外如果要启动YARN,需要再修改 mapred-site.xml 和 yarn-site.xml 两个配置文件。
通过编辑器或 vim 对xml配置文件进行修改。
修改 core-site.xml 配置文件:

1 <configuration> 2 <property> 3 <name>hadoop.tmp.dir</name> 4 <value>file:/usr/local/hadoop/tmp</value> 5 <description>Abase for other temporary directories.</description> 6 </property> 7 <property> 8 <name>fs.defaultFS</name> 9 <value>hdfs://localhost:9000</value> 10 </property> 11 </configuration>
修改 hdfs-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 </property> 6 <property> 7 <name>dfs.namenode.name.dir</name> 8 <value>file:/usr/local/hadoop/tmp/dfs/name</value> 9 </property> 10 <property> 11 <name>dfs.datanode.data.dir</name> 12 <value>file:/usr/local/hadoop/tmp/dfs/data</value> 13 </property> 14 </configuration>
修改 mapred-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration>
修改 yarn-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>yarn.nodemanager.aux-services</name> 4 <value>mapreduce_shuffle</value> 5 </property> 6 </configuration>
启动Hadoop
配置完成,首次启动Hadoop时需要对NameNode格式化:
1 $ hdfs namenode -format
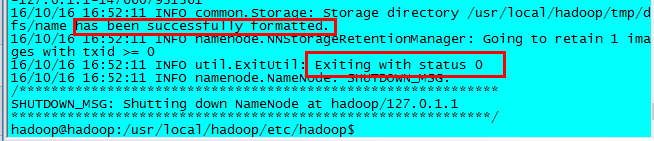
有这两个标志,则表示配置没问题,namenode已经格式化,可以启动Hadoop了。如果格式化错误,需要检查配置文件配置是否正确,最常见的问题就是配置文件里的拼写错误。
启动守护进程:
1 $ start-dfs.sh #启动hdfs,含NameNode、DataNode、SecondaryNameNode守护进程 2 $ start-yarn.sh #启动yarn,含ResourceManager、NodeManager 3 $ mr-jobhistory-daemon.sh start historyserver #开启历史服务器,才能在Web中查看任务运行情况
守护进程的启动情况可通过 jps 命令查看,查看所有的守护进程是否都正常启动。如果有未启动的守护进程,需要去 $HADOOP_HOME/logs 目录查看对应的守护进程启动的日志查找原因。
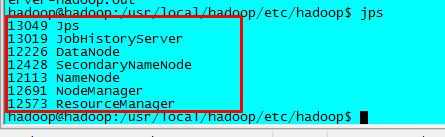
成功启动所有守护进程之后,通过Web界面 http://server_ip/50070 查看NameNode 和 DataNode 的信息,还可以在线查看HDFS文件。
YRAN启动之后(即 ResourceManager 和 NodeManager),也可以通过 http://server_ip/8088 查看管理资源调度,和查看Job的执行情况。
停止Hadoop
1 $ stop-dfs.sh 2 $ stop-yarn.shResourceManager、NodeManager 3 $ mr-jobhistory-daemon.sh stop historyserver
Note:Hadoop常用的服务器管理命令脚本都可以在 $HADOOP_HOME/bin 和 $HADOOP_HOME/sbin 目录中找到。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步