
[读书笔记] R语言实战 (五) 高级数据管理
1. 数值函数
1) 数学函数


2) 统计函数

3. 数据标准化
scale() 函数对矩阵或者数据框的指定列进行均值为0,标准化为1的标准化
mydata <- data.frame(c1=c(1,2,3),c2=c(4,5,6),c3=c(7,8,9)) #对所有列进行标准化 mydata <- scale(mydata) #对指定列进行标准化 mydata <- data.frame(c1=c(1,2,3),c2=c(4,5,6),c3=c(7,8,9)) mydata <- transform(mydata,c1 = scale(c1))
4. 概率函数
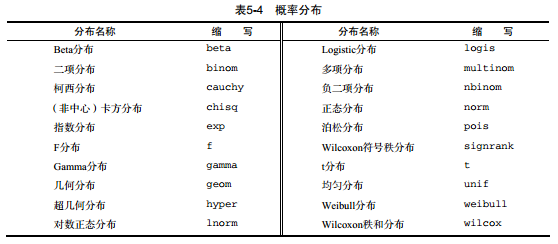
设定随机数种子:每次生成随机数的时候函数都会使用不同的种子,因此也会有不同的结果,可以通过set.seed()显示指定种子,让结果可以重现。
runif() 函数用来生成0到1区间上服从均匀分布的伪随机数
runif(5) runif(5) set.seed(1234) runif(5) set.seed(1234) runif(5)
5. 字符处理函数


apply 函数 可以将任意一个函数应用到矩阵数组,数据框的任何维度上:
apply(x, MARGIN, FUN, ... )
mydata <- matrix(rnorm(30),nrow=6) mydata #计算每行的均值 apply(mydata,1,mean) #计算每列的均值 apply(mydata,2,mean)
一个综合的例子
#限定输出小数点后两位
options(digits=2)
Student <-c("Jhon Davis","Angela Williams","Bullwinkle None",
"David Jones","Janice Markhammer","Chervl Cushing",
"Reuven Ytzrhak","Greg Knox","Joel England","Mary Rayburn")
Math <- c(502,600,412,358,495,512,410,625,573,522)
Science <- c(95,99,80,82,75,85,80,95,89,86)
English <- c(25,22,18,15,20,28,15,30,27,18)
roster <- data.frame(Student,Math,Science,English,stringsAsFactors = FALSE)
#将数学,科学,英语分数标准化,便于比较
z <- scale(roster[,2:4])
#计算行均值,每一个人的平均分
score <- apply(z,1,mean)
#将平均分
roster <- cbind(roster,score)
#计算80%,60%,40%,20%分位线
y <- quantile(score,c(.8,.6,.4,.2))
roster$grade[score>=y[1]]<-'A'
roster$grade[score<y[1] & score>=y[2]]<-'B'
roster$grade[score<y[2] & score>=y[3]]<-'C'
roster$grade[score<y[3] & score>=y[4]]<-'D'
roster$grade[score<y[4]]<-'F'
#将姓,名分开
name <- strsplit(roster$Student," ")
#抽取姓和名,'['提取对象一部分的函数
firstname <- sapply(name,"[",2)
lastname <- sapply(name,"[",1)
#将第一列剔除(下标使用-1),列拼接名和姓
roster <-cbind(firstname,lastname,roster[,-1])
roster <- roster[order(lastname,firstname),]
roster
6. 控制流
1) for 循环:for (var in seq) statement
2) while循环: while(cond) statement
3) 条件 if-else ifelse switch
7. 用户自编函数
mystats <- function(x, parametric=TRUE, print=FALSE){
if(parametric){
#计算均值和标准差
center <- mean(x); spread <- sd(x)
}else
{
#中位数和绝对中位差
center <- median(x);spread <- mad(x)
}
if (print & parametric){
cat("Mean=",center,"\n","MAD=",spread,"\n")
}
result <- list(center=center,spread=spread)
return(result)
}
set.seed(1234)
#生成服从正态分布,大小为500的样本
x <- rnorm(500)
y <- mystats(x,print=TRUE)
8. 重构与整合
1) 矩阵转置 t()
2) aggregate() 函数, aggregate(x,by,FUN), x 是待折叠的数据对象, by 是变量名组成的列表,这些变量被去掉形成新的观测,FUN,生成描述性统计量的标量函数,用来计算新观测中的值
by中的变量必须在一个列表中
options(digits=3) attach(mtcars) #按照cly 和 gear分类形成新的观测 aggdata <- aggregate(mtcars, by=list(Group.cyl=cyl,Group.gear=gear),FUN=mean,na.rm=TRUE) detach(mtcars)
3) reshape包
先对数据进行融合melt():每个观测变量单独占一行,行中有唯一确定这个测量需要的标识符变量
在对数据进行重铸cast():读取已经融合的数据,使用你提供的公式和一个可选的用于整合数据的函数将其重塑
#载入reshape包
library(reshape)
#创建数据框
mydata <- data.frame(ID = c(1,1,2,2),Time = c(1,2,1,2),X1 = c(5,3,6,2),X2 = c(6,5,1,4))
#以ID和Time为标识融合数据
md <- melt(mydata,id=(c("ID","Time")))
#以ID为标识对变量求均值,可以看到ID为1的X1均值为4,X2均值为5.5
cast(md,ID~variable,mean)
#对不同ID和Time下的观测变量X进行平均
cast(md,ID~Time,mean)

