

实验一 计算机是怎样工作的 SA*****369 张*铭
实验环境:ubuntu 12.04 LTS
实验目的:通过分析一个简单的C程序由编译到最后在计算机上的执行过程,来分析计算机具体是怎么工作的。
PS:本文仅基于最经典的冯诺依曼体系结构(即仅包括处理器和存储器(这里仅认为是内存)的计算机体系结构)。
example.c源码如下:

一、 GCC编译过程
这里首先介绍一下对于一个C语言的源程序通过GCC编译器进行编译最终生成可执行文件的过程。

GCC(GNU Compiler Collection)是一套由GNU工程开发的支持多种编程语言的编译器。这里,很多人有一个误区,认为GCC只是一个C编译器,其实,GCC可以支持多种高级编程语言,如:C、C++、ADA、Object C、Java、Fortran、Pascal等。
GCC是一个强大的工具集合,它包含了cpp预处理器、编译器(1、gcc--符合ISO等标准的C编译器;2、g++--基本符合ISO标准的C++编译器;3、gcj--GCC的java前端;4、gnat--GCC的GNU ADA 95前端等等)、汇编器、链接器等组件。GCC会根据输入文件的类型和传递给GCC的参数调用其他组件。
一般情况下,C程序的编译过程分为:预处理阶段;编译成汇编代码阶段;汇编代码汇编成目标代码阶段;将目标代码链接成可执行文件阶段。
1、预处理阶段
gcc后使用-E参数,输出的文件的后缀为.cpp。 即:gcc -E -o example.cpp example.c

然后通过vim打开example.cpp预处理文件,可以看到

通过与源代码进行对比,可以发现,所谓的预处理即是在进行编译的第一遍扫描(词法扫描和语法扫描)时,对以符号“#”开头的预处理命令进行翻译,这里面包括三类主要的处理:
*1、在调用宏的地方进行宏替换,即将宏名替换为所定义的相应的字符串;
*2、用实际值替代“define”的文本;
*3、将include包含的标题文件和头文件的具体的内容拷贝到相应的源代码中;
经过上面三个任务过程,最终生成了.cpp预处理文件。我们可以通过wc命令来对比一下.c源文件与预处理后的.cpp预处理文件在字节大小上的区别:

其中,第一列表示相应文件中的行数,第二列表示相应文件中的单词数,第三列表示相应文件中的字节数。通过对比,可以看到预处理之后的.cpp文件,较之前的源文件在字节数上有很大的变化,这就是将stdio.h头文件的具体内容拷贝过来的结果。
2、编译成汇编代码阶段
由最上面的编译流程图可以看出,编译生成.s汇编文件有两种方法:
*1、可以使用-S参数说明生成汇编代码后停止工作,由.c源文件直接编译生成.s汇编文件;即 gcc -S -o example.s example.c

*2、可以使用-x参数说明根据指定的步骤进行工作,然后由cpp-output指明从预处理得到的文件,同时使用-S参数说明生成汇编代码后停止工作;即 gcc -x cpp-output -S -o example.s example.cpp

可以看到两种方法都成功的生成了.s汇编文件,打开两个汇编文件进行比较:


可以看到两种方法生成的汇编文件完全一样,其实,这两种方法实际上是一种方法,只不过是是否忽略中间过程的区别。
3、编译生成目标代码文件阶段
同样,由上面的编译过程流程图可以看出,生成目标文件可以有两种方法
*1、可以使用-c参数,直接由.c源文件编译生成目标文件;即 gcc -c example.c -o example.o

*2、可以使用-x参数说明根据指定的步骤进行工作,然后由assembler指明由汇编文件生成相应的文件,同时使用-c参数说明生成目标文件后停止;即 gcc -x assembler -c example.s -o example.o

可以看到两种方法均生成了相应的.o目标文件。
这里还将介绍第三种方法,即使用GCC自带的as汇编器,直接由汇编文件编译生成目标文件。即 as -o example.o example.s

可以看到直接生成了.o目标文件。
4、链接生成可执行文件
由最上面的编译过程流程图可以清楚的看到,编译生成可执行文件同样有两种比较常用的方法
*1、使用-o参数,直接由.c源文件编译链接生成可执行文件;

*2、使用-o参数,由.o目标文件链接生成可执行文件;

可见两种方法均可正确地编译链接生成可执行文件。
链接阶段主要是将各个.o目标文件链接起来,形成具体的可执行文件。
二、分析汇编程序在CPU上的执行过程
首先通过调用objdump -d 对可执行文件进行反汇编,可以得到汇编代码如下:

看到上面的汇编源码,想到这里面涉及到一些相关的基础知识,在这里介绍一下:
首先是寄存器,%eax为累加器,%ebx为基地址寄存器,%ecx为计数寄存器,%edx为数据寄存器,%ebp为栈基地址指针寄存器,%esp为栈栈顶指针寄存器。
然后是栈相关的几个重要的操作命令:
*1、首先是push操作,拿pushl %eax举例,相当于执行了 subl $4,%esp 和 movl %eax,(%esp)两条指令,这里因为栈在内存空间中是由高地址向低地址生长的,所以在入栈过程中,栈顶是向低地址增长的,所以是%esp - 4。pushl %eax实际上就是将%eax寄存器中存储的值入栈。因此首先栈顶指针%esp要向低地址生长4个字节,以留出存储入栈数据所需要的内存空间,然后通过执行movl操作,将%eax寄存器中的数据,存储到%esp所指向的内存空间中。这样一个过程即实现了数据的入栈操作。
*2、接着是pop操作,同样是拿popl %eax举例,相当于执行了movl (%esp),%eax和addl $4,%esp两条指令,因为栈在内存空间中是由高地址向低地址生长的,所以出栈过程,栈顶是返回到高地址的,所以是%esp + 4。popl %eax实际上就是将当前处于栈顶的值存储到%eax寄存器中。因此首先执行movl操作,将当前栈顶的值存储到%eax寄存器中,然后,栈顶指针%esp上移4个字节,以释放空闲的栈内存空间。这样一个过程即实现了数据的出栈操作。
*3、call 0x12345,这里思考一个问题,如果需要指令不按照顺序一条一条的向下执行, 而是从一个位置立刻跳转到另外一个位置,该怎么实现呢?这就需要使用call指令实现指令的调用。执行call 0x12345相当于执行了pushl %eip和movl $0x12345,%eip,这里的0x12345即为所要调用跳转到的地址。通过上面的语句分析可以看到,这个过程首先是先把此刻%eip寄存器的值入栈,那么%eip存储的又是什么值呢?其实%eip中存储的是当前调用跳转指令的下一条指令,即调用跳转返回后该执行的指令,因此先将%eip值入栈保存,以待以后恢复执行使用。然后将0x12345保存到%eip中,即下一条将要执行的是地址0x12345处的指令,即所要调用的指令。
*4、ret,这里ret指令相当于执行了popl %eip,由上面对pop指令的分析,可以知道,是将当前栈顶存储的值存储在%eip寄存器中,然后将栈顶指针上移,即实现了出栈操作,恢复%eip的值到调用跳转返回后所要执行的指令的位置处。
*5、leave,这里再介绍一个非常重要的指令,在实际的程序操作中经常使用,那就是leave指令。执行leave指令相当于执行了movl %ebp,%esp和popl %ebp两条指令。由上述语句描述可以看出,leave首先是将栈基地址寄存器%ebp中当前的值存储到栈顶指针寄存器%esp中,然后对%ebp进行出栈操作。这样即实现了由一个任务返回到调用它的任务的内存栈空间的操作。
了解了上面的基础知识之后,开始从内存栈角度解析所给的example.c源码所对应的汇编代码在计算机中的执行过程。因为源码都是从main函数开始执行的,所以,先从main函数反汇编出的汇编代码开始。

图.1
由图.1可以看到是main函数中的第一条语句push %ebp的执行过程,可以看到当前%ebp中保存的是前一个进程执行时所在的内存栈空间的基地址,因此为了保证在example.c程序执行完毕之后,CPU能正确恢复到之前所执行的进程中去继续执行,必须对前一个进程的上下文环境进行保存,这里即将前一个进程所占用的栈空间的基地址保存起来,从而实现了对前一个进程上下文环境的保存。这里我们假设前一个进程的栈基地址值为ebp1。

图.2
如图.2所示,为执行第二条语句mov %esp,%ebp的栈状态,可以看到,这条语句的结果是将栈顶指针寄存器%esp中存储的值传递给栈基地址指针寄存器%ebp,现在,%ebp和%esp指向栈的同一个位置,均指向当前的栈顶。

图.3
图.3所示为执行第三条语句sub $0x4,%esp之后的栈的状态。
综合上面图.1、图.2、图.3,可以看出,前三条语句主要的作用是,先保存前一个进程执行的上下文环境,然后通过将栈基地址指针指向当前栈的栈顶,相当于为当前将要执行的新进程分配了一块新的栈空间。

图.4
如图.4为执行第四条语句movl $0x8,(%esp)之后栈的状态,可以看到将立即数8保存到了栈的栈顶空间中。

图.5
图.5中示出的为执行了第五条指令call 80483bf后栈的状态,如前所述,执行call指令相当于执行了两条指令:push %eip和movl $0x80483bf,%eip。首先,执行push指令将%eip寄存器中存储的值入栈保存,以保证在调用返回之后可以继续执行源程序中调用指令的下一条指令,这里当前%eip寄存器中保存的是call指令的下一条指令的地址,即add $0x1,%eax指令的地址,为80483e4。将这一地址设为eip1,因此可以看到,push指令执行结束之后,栈顶空间中保存的就是这一地址值。然后执行movl指令,即将所要调用的函数的入口地址保存到%eip寄存器中,以保证下一条实际上执行的指令为被调用函数的第一条指令。这里可以看到,80483bf实际上就是所要调用的函数f的入口地址,即函数f的第一条指令的地址。有上述分析可以看出,此时,已经实现了函数的调用跳转,即程序是非顺序执行的。
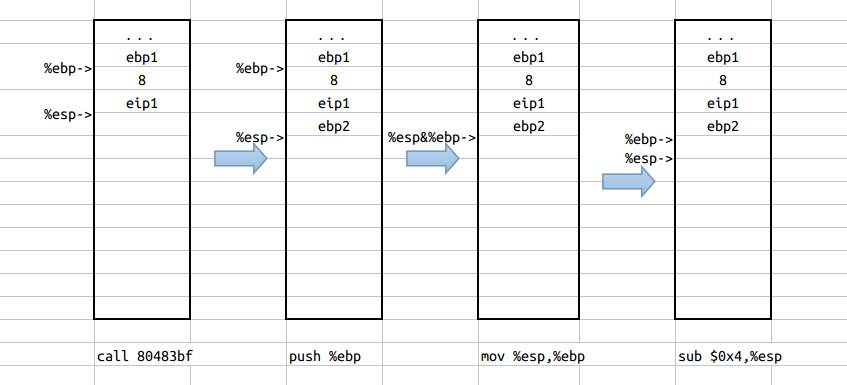
图.6
如图.6所示,经过调用跳转之后,现在跳转到函数f中执行,从函数f的反汇编代码可以看到,前三条语句与main函数的反汇编代码的前三条语句相同,分别为push %ebp,mov %esp,%ebp和sub $0x4,%esp。这里主要是实现了对main函数的栈空间状态进行保存,以确保在从被调用函数中返回时,能正确的继续执行main函数。然后,为被调用执行的新函数f分配新的内存空间,主要是通过修改栈基地址指针寄存器%ebp的值实现的,然后将栈顶指针寄存器%esp下移。具体的过程,在前面的main函数的反汇编代码的分析中已经具体说明,这里不再详细解释。

图.7
图.7中示出的是执行被调用函数f的第四条语句mov 0x8(%ebp),%eax之后的栈和相应的寄存器的状态,首先间接访问地址%ebp+8栈空间中的值,因为栈空间是由高地址向低地址生长的,所以%ebp+8所指向的地址如图.7中所示,该栈空间中保存的值为立即数8,然后这一值保存在寄存器%eax中,所以%eax当前保存的值为8。

图.8
图.8中示出的为执行被调用函数f第五条语句mov %eax,(%esp)之后的栈空间的状态,可以看到将%eax寄存器中保存的值8入栈,保存在了栈顶空间中。

图.9
图.9中示出的为执行函数f中第六条语句call 80483b4之后栈空间的状态。call语句的具体执行过程这里不详细解释,在执行call语句之前,%eip寄存器中的值为f中call语句下一条语句的地址,即80483d0处,这里假设这一地址值为eip2,首先将这一地址入栈,以保证当调用返回之后,可以继续执行f函数中call语句的下一条指令。然后将所要跳转到的地址值保存到%eip寄存器中,以实现下一条将要执行的指令为跳转后的指令,这里即地址80483b4处的指令,可以看到,80483b4实际上就为g函数的入口地址,即g函数的第一条指令的地址。所以这一系列的操作完成了函数的跳转,下一步执行将开始执行g函数。

图.10
图.10中示出的为执行了被调用函数g的前两条语句之后的栈空间的状态,同样的保存调用函数的执行上下文栈环境,为被调用函数分配新的栈空间,因此,这里不再赘述。

图.11
图.11中示出了执行了g函数中mov 0x8(%ebp),%eax语句之后的栈和相应的寄存器的状态,上面也详细解释过,这里不再多说。然后在g函数中执行add $0x3,%eax,这时%eax寄存器中保存的值为8+3=11。

图.12
图.12示出了执行g函数中pop %ebp语句之后栈空间的状态。由上面对pop指令的介绍可以知道,执行pop操作相当于执行了movl (%esp),%ebp和addl $4,%esp两条指令,可以看到,首先将栈顶指针寄存器%esp中的值保存到%ebp寄存器中,可以看到,未执行pop操作前,%esp寄存器中保存的是调用函数f的栈基地址,因此,将函数f的栈基地址保存到%ebp中,即恢复函数f的执行栈空间环境,然后%esp指针上移4个字节。这时所执行的栈空间即为函数调用前的函数f的栈空间。

图.13
如图.13所示,为执行g函数中最后一条语句ret之后的栈空间的状态。在上面的介绍中知道,ret指令相当于执行了pop %eip,而pop %eip又相当于执行了movl (%esp),%eip和addl $4,%esp,即将当前栈顶空间中的值eip2保存到%eip寄存器中,由上面的分析可以知道,这里的eip2即为函数f中call语句的下一条语句leave的地址,将这一地址保存到%eip中,可以保证在调用返回后,继续执行f函数中call语句的下一条指令。然后%esp上移4个字节,继续指向此时的栈顶。到此,执行过程已经完全从被调用函数g中返回到f中继续执行了。

图.14
图.14给出了由被调用函数g中返回到函数f中继续执行call语句下一条leave指令后的栈空间的状态。这里的过程有些复杂,首先执行leave指令相当于执行了movl %ebp,%esp和popl %ebp。首先由图中ret指令之后栈的状态可以看到,执行movl %ebp,%esp是让%esp上移一位同%ebp指向同一个地址,然后执行pop指令又相当于执行了movl (%esp),%ebp和addl $4,%esp两条指令。在%esp上移后,%esp指向的空间中保存的是ebp2值,即由图可以看出,是main函数栈空间的基地址,因此mov指令将main的栈空间的基地址保存到%ebp寄存器中,即相当于恢复了main函数执行的栈内存空间环境,然后%esp再次+4上移一位。因此得到最后的结果状态。

图.15
由图.15可以看出,最后执行了函数f中的最后一条语句ret,具体的语句执行的过程上面也已经详细解释过,这里不再赘述。自ret执行结束之后,整个函数调用过程即结束了,再次返回到最初的调用函数main函数中继续执行,ret的执行正好保证了调用返回时可以从call调用函数的下一条语句继续执行,因为保存到%eip寄存器中的值eip1正是main函数中call指令的下一条指令add $0x1,%eax的地址80483e4。
然后顺序执行add $0x1,%eax,执行add指令之前,%eax中保存的值为11。则在执行完add语句之后,%eax中的值为11+1=12。

图.16
图.16为main函数执行leave语句之后的栈空间的状态。可以看到执行leave语句将%ebp栈基址寄存器的值赋为ebp1,而由前面的分析我们知道,ebp1即为在执行main函数之前,所执行的程序的栈空间上下文环境的基地址,因此可以看到执行leave语句将执行的程序的栈空间环境恢复到执行main函数之前的进程的栈空间环境。最后再执行一个ret语句,以保证该进程能够从执行main函数之前的那条语句的下一条语句继续执行。
到此为止,从栈空间的角度分析C程序的执行过程就结束了。
三、讨论单任务计算机是如何工作的。
由上述的example.c源程序的执行过程,我们可以看到单任务计算机执行的大体过程。首先,对于单任务计算机来说,不存在中断。程序是运行在线性地址空间当中。每个函数的执行都有自己相应的栈空间。%ebp栈基址寄存器中保存的是当前执行函数的栈空间的基地址,%esp栈顶指针寄存器中保存的是当前的栈的栈顶。当程序执行时,基本原则是从上到下顺序的执行当前执行函数中的每一条指令,当存在函数调用时,主要是通过call指令。call指令会首先保存当前执行函数中的call指令下一条指令的地址,即当前%eip寄存器中的值,然后将所要调用的函数的地址保存到%eip当中,作为实际上将要执行的下一条指令,即为所要跳转到的函数的第一条指令的地址。
通常,跳转到的函数的前两条指令是push %ebp和mov %esp,%ebp。先将%ebp中的值入栈,即保存调用函数的栈空间的基地址,这样做的目的是保护调用函数的栈空间上下文环境,以保证在调用返回时,能够正确的恢复到调用函数中继续执行。然后,将%esp所指向的地址赋给%ebp,即让%ebp指针和%esp指针指向同一处栈地址,也即为此时的栈顶位置。这样做相当于为被调用函数分配了一块新的栈空间。然后被调用函数再接着按照从上到下的顺序,顺序执行每一条语句。
当被调用函数执行完毕后,会执行leave指令来将栈空间恢复到调用函数的栈空间当中,并且释放被调用函数所占的栈空间。然后调用ret指令来将%eip的值恢复到调用函数中call指令的下一条指令的地址值。这样就可以保证调用返回后,可以正确的从调用函数的call指令的下一条指令继续开始执行。
上述分析,大体上说明了一个程序在单任务计算机中的执行过程。
四、引申到多任务计算机工作方法的分析
多任务计算机,顾名思义,就是可以同时有多个进程在运行,并且支持中断等机制。
由上述的单任务计算机的分析,可以想到,多任务计算机的理念也应该大体相同,即多任务中的每一个任务的执行过程与原理,和单任务计算机中的一个任务的执行过程应该是相同的,但是关键在于同时有多个进程在运行,各个进程之间,如果一个进程在执行,另一个进程忽然之间打断了它的执行应该怎么处理。
通过上面的分析,我们就可以很容易的想到,只要当由一个进程切换到另外一个进程执行时,我们可以先将第一个进程的硬件上下文,包括各个寄存器的值,进程所占栈空间的状态等信息保存起来,以保证在由第二个进程恢复到第一个进程时,能够正确的恢复第一个进程的各个寄存器的值以及对应的栈空间的状态。然后切换到第二个进程中去执行,当第二个进程执行结束之后,会恢复栈空间和相应寄存器到进程切换之前时,第一个进程执行所处的状态,然后再从第一个进程被打断处继续执行。
由此原理,就实现了多任务计算机的工作过程,可以看到,思想上同单任务计算机中每个任务执行过程的思想是相似的。

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步