
概率论06 连续分布
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明。谢谢!
在随机变量中,我提到了连续随机变量。相对于离散随机变量,连续随机变量可以在一个连续区间内取值。比如一个均匀分布,从0到1的区间内取值。一个区间内包含了无穷多个实数,连续随机变量的取值就有无穷多个可能。
为了表示连续随机变量的概率分布,我们可以使用累积分布函数或者密度函数。密度函数是对累积分布函数的微分。连续随机变量在某个区间内的概率可以使用累积分布函数相减获得,即密度函数在相应区间的积分。
在随机变量中,我们了解了一种连续分布,即均匀分布(uniform distribution)。这里将罗列一些其他的经典连续分布。
指数分布
指数分布(exponential distribution)的密度函数随着取值的变大而指数减小。指数分布的密度函数为:
$$f(x) = \left\{ \begin{array}{rcl} \lambda e^{-\lambda x} & if & x \ge 0 \\ 0 & if & x < 0 \end{array} \right.$$
累积分布函数为:
$$F(x) = 1 - e^{-\lambda x}, x \ge 0$$
我们绘制一个指数分布[$\lambda = 0.2$],如下:
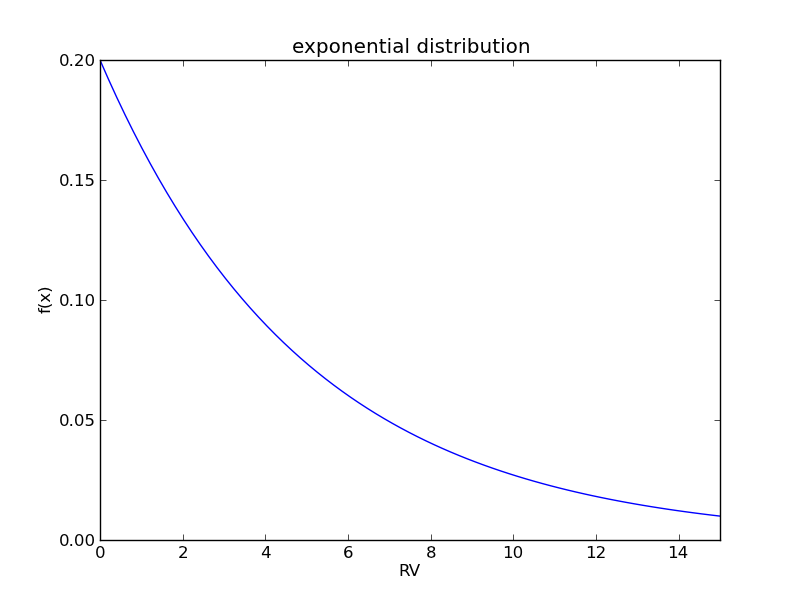
这样一种分布在生活中很常见。比如,洪水等级的分布就类似于这样一个分布。小等级的洪水常发生,而大洪水发生的概率则很小。再比如,金矿的分布:大部分矿石的含金量少,而少部分矿石的含金量高。这提醒我们,一些特殊的条件导致了指数分布。感兴趣的话可以学习“随机过程”这一数学分支。
代码如下:
from scipy.stats import expon
import numpy as np
import matplotlib.pyplot as plt
rv = expon(scale = 5)
x = np.linspace(0, 20, 100)
plt.plot(x, rv.pdf(x))
plt.xlim([0, 15])
plt.title("exponential distribution")
plt.xlabel("RV")
plt.ylabel("f(x)")
plt.show()
上面的expon函数接收一个参数scale。参数scale等于[$1/\lambda$]
指数分布是无记忆(memoryless)的。我们以原子衰变为例。任意时刻往后,都需要10年的时间,会有一半的原子衰变。已经发生的衰变对后面原子衰变的概率分布无影响。用数学的语言来说,就是
$$P(X > s) = P(X > s+t | X>t), for\, s,t \ge 0$$
等式的左边是原子存活了s的概率。而等式的右边是某一时刻t之后,原子再存活s时间的概率。可以利用指数分布的累积分布函数,很容易的证明上面的等式。指数分布经常用于模拟人的寿命或者电子产品的寿命,这意味着我们同样假设这些分布是无记忆的。一个人活10年的概率和一个人到50岁后,再活10年的概率相等。这样的假设有可能与现实情况有所出入,需要注意。
正态分布
正态分布(normal distribution)是最常用到的概率分布。正态分布又被称为高斯分布(Gauss distribution),因为高斯在1809年使用该分布来预测星体位置。吐槽一句,第一个提出该分布的并不是数学王子高斯,而是法国人De Moivre。作为统计先驱,这位数学家需要在咖啡馆“坐台”,为赌徒计算概率为生。(看来法国咖啡馆不止有文艺青年,也有技术屌丝啊。)

Abraham De Moivre
Gauss
正态分布的发现来自于对误差的估计。早期的物理学家发现,在测量中,测量值的分布很有特点:靠近平均值时,概率大;远离平均值时,概率小。比如我们使用尺子去测量同一个物体的长度,重复许多次。如果没有系统误差,那么测量到的长度值是一个符合正态分布的随机变量。再比如,在电子信号中白噪音,也很有可能符合正态分布。De Moivre最早用离散的二项分布来趋近这一分布,而高斯给出了这一分布的具体数学形式。
正态分布自从一出生就带着无比强大的“主角光环”,它的特殊地位在后面文章中的中心极限定理中凸显出来。
正态分布的密度函数如下:
$$f(x) = \frac{1}{\sqrt{2\pi}\sigma}e^{-(x-\mu)^2/2\sigma^2}, -\infty < x < \infty$$
正态分布有两个参数,[$\mu$]和[$\sigma$]。我们可以将正态分布表示成[$N(\mu, \sigma)$]。当[$\mu = 0$],[$\sigma = 1$],这样的正态分布被称作标准正态分布(standard normal distribution)。
我们绘制三个正态分布的密度函数:

可以看到,正态分布关于[$x = \mu$]对称,密度函数在此处取得最大值,并随着偏离中心而递减。如果以测量长度为例,这说明的读取值靠近[$\mu$]的可能性较大,而偏离[$\mu$]的可能性变小。
[$\sigma$]代表了概率分布的离散程度。[$\sigma$]越小,概率越趋近对称中心[$x = \mu$]。
代码如下:
# By Vamei
from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt
rv1 = norm(loc=0, scale = 1)
rv2 = norm(loc=2, scale = 1)
rv3 = norm(loc=0, scale = 2)
x = np.linspace(-5, 5, 200)
plt.plot(x, rv1.pdf(x), label="N(0,1)")
plt.plot(x, rv2.pdf(x), label="N(2,1)")
plt.plot(x, rv3.pdf(x), label="N(0,2)")
plt.legend()
plt.xlim([-5, 5])
plt.title("normal distribution")
plt.xlabel("RV")
plt.ylabel("f(x)")
plt.show()
正态分布在统计中有非常重要的地位。我们将在后面的中心极限理论的讲解中,看到这一点。
Gamma分布
Gamma分布在统计推断中具有重要地位。它的密度函数如下:
$$g(t) = \frac{\lambda^\alpha}{\Gamma(\alpha)}t^{\alpha-1}e^{-\lambda t}, t \ge 0$$
其中的Gamma函数可以表示为:
$$\Gamma(x) = \int \limits_{0}^{\infty} u^{x-1}e^{-u}du, x>0$$
注意到,Gamma分布有两个控制参数[$\alpha$]和[$\lambda$]。
练习,利用scipy.stats.gamma绘制[$\alpha = 1, \lambda = 1$]和[$\alpha = 5, \lambda = 1$]的Gamma分布密度函数。
总结
我们研究了三种连续随机变量的分布,并使用概率密度函数的方法来表示它们。密度函数在数学上比较容易处理,所以有很重要的理论意义。
密度函数在某个区间的积分,是随机变量在该区间取值的概率。这意味着,在密度函数的绘图中,概率是曲线下的面积。
欢迎继续阅读“数据科学”系列文章
如果你喜欢这篇文章,欢迎推荐。

