



一: Multitenant Architecture (12.1.0.1)
多租户架构是Oracle 12c(12.1)的新增重磅特性,内建的多分租(Multi-tenancy),一个容器数据库(container database)中可以存放多个Pluggable Databases,每个Pluggable Database均独立于其他Pluggable Database。
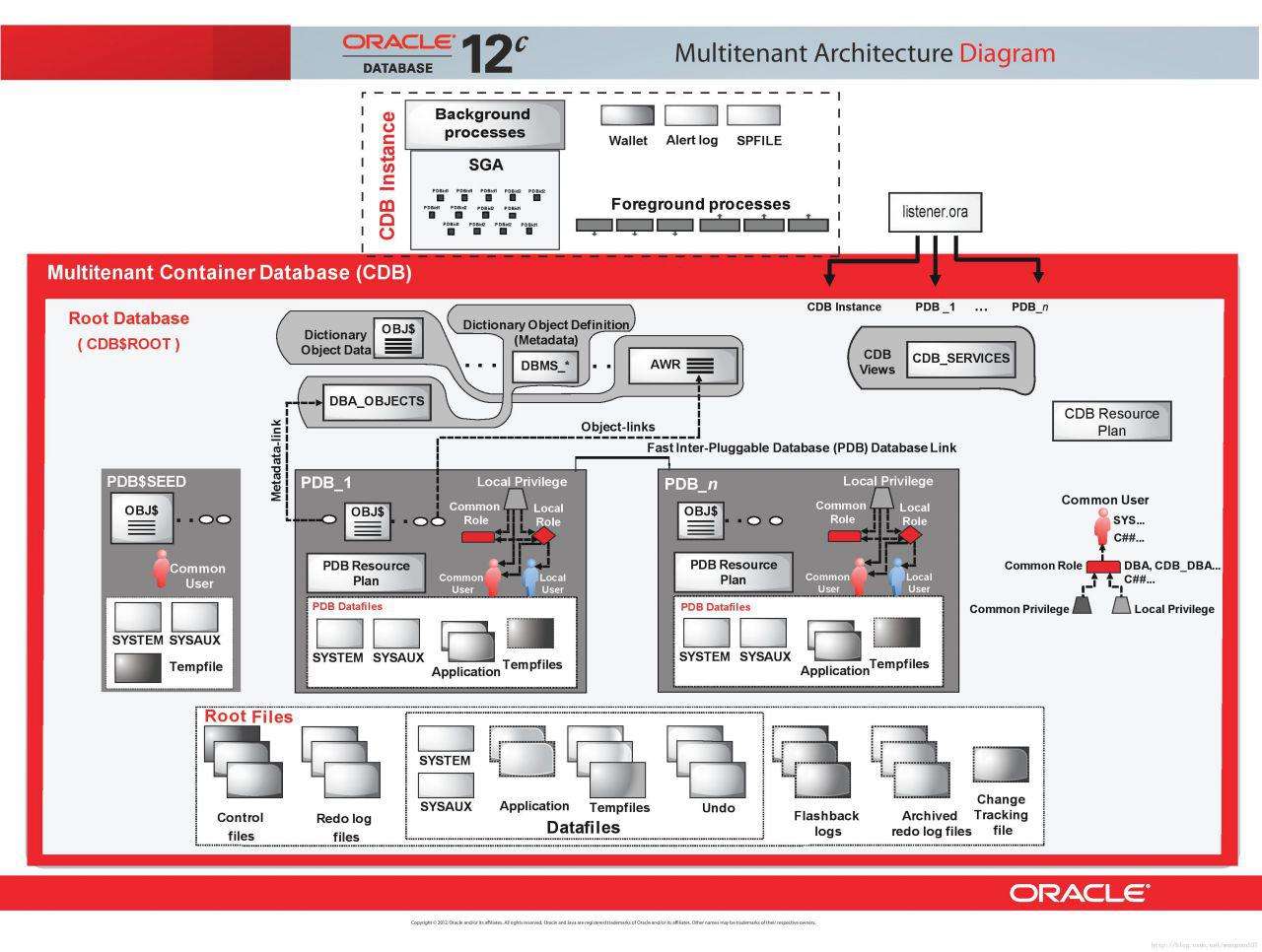
对于外部应用程序和开发者来说,Pluggable Databases看上去就是一个普通的12.1版本之前的单一数据库。DBA可以连接到Pluggable Database并仅仅管理该数据库,超级DBA可以连接到容器数据库并如同管理单系统镜像那样管理所有Pluggable Database。
Pluggable Databases特性带来的好处:
1、集中式管理多个数据库实例。
2、通过PDB$SEED模板快速配置新数据库。
3、加速现有数据库打补丁和升级的速度。
4、通过PDB拔插移植到更高版本中的其他CDB中进行修补或升级。
5、通过将现有数据库的拔插和插拔快速重新部署到新平台(迁移)。
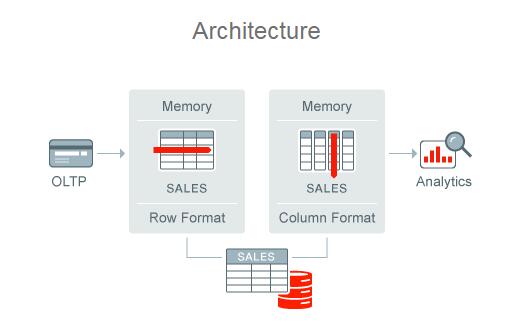
对于传统的OLTP系统,为了实现快速查询,往往采用分析型索引的方式,在这样的架构下,向表中插入一条记录需要同时更新数十个索引,OLTP系统性能被迫降低。12c In-Memory通过用内存列存储取代分析型索引,纯内存中的列式存储能够快速响应数据变化,可达到2倍至20倍的压缩比例,其粒度还支持表级与分区级,并适用于所有主流的硬件平台,使得OLTP系统中可以给予任意一列实现快速分析,OLTP和批处理的速度得到大幅提升。
在测试当中,列格式的每CPU内核可达到10亿条/秒的扫描速度,而行格式仅能达到百万条,性能的提升高达一百倍以上。不仅如此,通过将多表的连接操作转化为高效的列扫描,表连接速度也加快10倍。
Oracle Sharding是用于自定义设计的OLTP应用程序的可扩展性和可用性功能,可以在不共享硬件或软件的Oracle数据库池之间分发和复制数据。 将数据库池作为单个逻辑数据库呈现给应用程序。 应用程序可以在任何平台上将任何级别(数据,事务和用户)弹性地缩放(简单地通过在池中添加数据库(分片))。
简单来说,Oracle的Sharding技术就是通过分区(Partioning)技术的扩展来实现的。以前一个表的分区可以存在于不同的表空间,现在可以存在于不同的数据库。
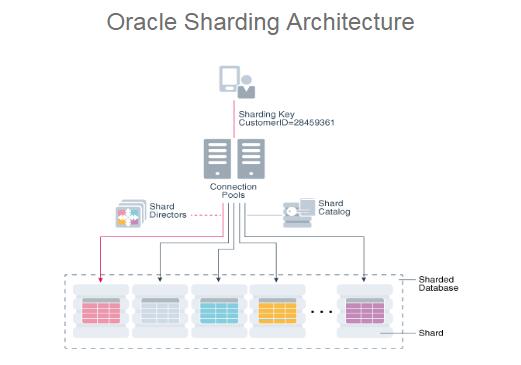
与其他NOSQL型的sharding结构相比,Oracle Sharding提供了卓越的运行时性能和更简单的生命周期管理。 它还提供企业RDBMS的优势,包括:关系模式,SQL和其他编程接口,支持复杂数据类型,在线模式更改,多核可扩展性,高级安全性,压缩,高可用性,ACID属性,一致性等等。
Oracle Sharding使用GDS(Global Data Services)架构来自动部署和管理sharding和复制技术。GDS(GDS是Oracle RDBMS 12.1的新特性)也提供负载均衡和SDB(sharded database)中的基于位置的路由功能。
Shard目录(Shard directors)使用GDS framework的全局服务管理组件(global service manager component)来提供应用层请求到shard的直接路由。shard目录(Shard directors)是一个单独的数据库,它用来保存SDB(Sharding database)配置数据和提供其他相关功能,比如shard的交叉查询和集中管理。可以使用GDS是GDSCTL工具可以用来配置SDB。
Oracle Sharding的分区架构(Partitioning Infrastructure)分区在表空间级别跨Shards分布,每个表空间关联一个特定的shard。一个shard表的每一个分区放单独的表空间,并且每个表空间关联到一个特定的shard。根据不同的sharding方法,这个关联可以自动建立或者根据定义创建。尽管一个shard表的多个分区放在多个单独主机的数据库上(这些数据库完全独立,不共享CPU、内存等软件和硬件),但是应用访问表时就如同访问一个单独数据库中的分区表一样。应用发出的SQL语句不需要依赖shard号和shard的物理配置。
Sharding如何实现数据路由?
既然数据被拆分,那么在访问时如何实现数据路由呢?在Sharding的架构里,存在一个“Shard Directories”目录库来管理Sharding的分布,当应用通过Sharding Key来访问数据时,连接池(GDS - Global Data Services)就会给出访问路径,快速指向需要访问的Shard。如果应用不指定分区键访问,则需要通过协调库-Coordinator DB来协助判定。

