

教你如何迅速秒杀99%的海量数据处理面试题
教你如何迅速秒杀99%的海量数据处理面试题
作者:July
出处:结构之法算法之道blog
前言
一般而言,标题含有“秒杀”,“99%”,“史上最全/最强”等词汇的往往都脱不了哗众取宠之嫌,但进一步来讲,如果读者读罢此文,却无任何收获,那么,我也甘愿背负这样的罪名,:-),同时,此文可以看做是对这篇文章:十道海量数据处理面试题与十个方法大总结的一般抽象性总结。
毕竟受文章和理论之限,本文摒弃绝大部分的细节,只谈方法/模式论,且注重用最通俗最直白的语言阐述相关问题。最后,有一点必须强调的是,全文行文是基于面试题的分析基础之上的,具体实践过程中,还是得具体情况具体分析,且场景也远比本文所述的任何一种场景复杂得多。
OK,若有任何问题,欢迎随时不吝赐教。谢谢。
何谓海量数据处理?
所谓海量数据处理,其实很简单,海量,海量,何谓海量,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存。
那解决办法呢?针对时间,我们可以采用巧妙的算法搭配合适的数据结构,如Bloom filter/Hash/bit-map/堆/数据库或倒排索引/trie/,针对空间,无非就一个办法:大而化小:分而治之/hash映射,你不是说规模太大嘛,那简单啊,就把规模大化为规模小的,各个击破不就完了嘛。
至于所谓的单机及集群问题,通俗点来讲,单机就是处理装载数据的机器有限(只要考虑cpu,内存,硬盘的数据交互),而集群,机器有多辆,适合分布式处理,并行计算(更多考虑节点和节点间的数据交互)。
再者,通过本blog内的有关海量数据处理的文章,我们已经大致知道,处理海量数据问题,无非就是:
- 分而治之/hash映射 + hash统计 + 堆/快速/归并排序;
- 双层桶划分
- Bloom filter/Bitmap;
- Trie树/数据库/倒排索引;
- 外排序;
- 分布式处理之Hadoop/Mapreduce。
本文接下来的部分,便针对这6种方法模式结合对应的海量数据处理面试题分别具体阐述。
处理海量数据问题之六把密匙
密匙一、分而治之/Hash映射 + Hash统计 + 堆/快速/归并排序
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
既然是海量数据处理,那么可想而知,给我们的数据那就一定是海量的。针对这个数据的海量,我们如何着手呢?对的,无非就是分而治之/hash映射 + hash统计 + 堆/快速/归并排序,说白了,就是先映射,而后统计,最后排序:
- 分而治之/hash映射:针对数据太大,内存受限,只能是:把大文件化成(取模映射)小文件,即16字方针:大而化小,各个击破,缩小规模,逐个解决
- hash统计:当大文件转化了小文件,那么我们便可以采用常规的Hashmap(ip,value)来进行频率统计。
- 堆/快速排序:统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP。
具体而论,则是: “首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用Hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。”--十道海量数据处理面试题与十个方法大总结。
2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
由上面第1题,我们知道,数据大则划为小的,但如果数据规模比较小,能一次性装入内存呢?比如这第2题,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去,而现在只是需要一个合适的数据结构,在这里,Hash Table绝对是我们优先的选择。所以我们摒弃分而治之/hash映射的方法,直接上hash统计,然后排序。So,
- hash统计:先对这批海量数据预处理(维护一个Key为Query字串,Value为该Query出现次数的HashTable,即Hashmap(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内用Hash表完成了统计;
- 堆排序:第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。
别忘了这篇文章中所述的堆排序思路:“维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。”--第三章续、Top K算法问题的实现。
当然,你也可以采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
由上面那两个例题,分而治之 + hash统计 + 堆/快速排序这个套路,我们已经开始有了屡试不爽的感觉。下面,再拿几道再多多验证下。请看此第3题:又是文件很大,又是内存受限,咋办?还能怎么办呢?无非还是:
- 分而治之/hash映射:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
- hash统计:对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率。
- 堆/归并排序:取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了。
直接上:
- hash映射:顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
- hash统计:找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。注:hash_map(query,query_count)是用来统计每个query的出现次数,不是存储他们的值,出现一次,则count+1。
- 堆/快速/归并排序:利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
5、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 分而治之/hash映射:遍历文件a,对每个url求取
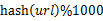 ,然后根据所取得的值将url分别存储到1000个小文件(记为
,然后根据所取得的值将url分别存储到1000个小文件(记为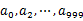 )中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为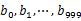 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(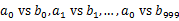 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 - hash统计:求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
OK,此第一种方法:分而治之/hash映射 + hash统计 + 堆/快速/归并排序,再看最后三道题,如下:
6、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
7、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
8、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
接下来,咱们来看第二种方法,双层捅划分。
密匙二、双层桶划分
双层桶划分----其实本质上还是分而治之的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
密匙三:Bloom filter/Bitmap
Bloom filter
关于什么是Bloom filter,请参看此文:海量数据处理之Bloom Filter详解。
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
同时,上文的第5题:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
Bitmap
至于什么是Bitmap,请看此文:http://blog.csdn.net/v_july_v/article/details/6685962。下面关于Bitmap的应用,直接上题,如下第9、10道:
9、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
10、腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
方案1:oo,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
密匙四、Trie树/数据库/倒排索引
Trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
- 有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序。
- 1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
- 寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
- 上面的第8题:一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词。其解决方法是:用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度),然后是找出出现最频繁的前10个词。
更多有关Trie树的介绍,请参见此文:从Trie树(字典树)谈到后缀树。
数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
关于数据库索引及其优化,更多可参见此文:http://www.cnblogs.com/pkuoliver/archive/2011/08/17/mass-data-topic-7-index-and-optimize.html。同时,关于MySQL索引背后的数据结构及算法原理,这里还有一篇很好的文章:http://www.codinglabs.org/html/theory-of-mysql-index.html。
倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what","is"和"it"将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
关于倒排索引的应用,更多请参见:第二十三、四章:杨氏矩阵查找,倒排索引关键词Hash不重复编码实践,及第二十六章:基于给定的文档生成倒排索引的编码与实践。
密匙五、外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
关于多路归并算法及外排序的具体应用场景,请参见此文:第十章、如何给10^7个数据量的磁盘文件排序。
密匙六、分布式处理 Mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
- The canonical example application of MapReduce is a process to count the appearances of each different word in a set of documents:
- 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
- 一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数的中数(median)?
更多具体阐述请参见:从Hadhoop框架与MapReduce模式中谈海量数据处理,及MapReduce技术的初步了解与学习。
参考文献
- 十道海量数据处理面试题与十个方法大总结;
- 海量数据处理面试题集锦与Bit-map详解;
- 十一、从头到尾彻底解析Hash表算法;
- 海量数据处理之Bloom Filter详解;
- 从Trie树(字典树)谈到后缀树;
- 第三章续、Top K算法问题的实现;
- 第十章、如何给10^7个数据量的磁盘文件排序;
- 第二十三、四章:杨氏矩阵查找,倒排索引关键词Hash不重复编码实践;
- 第二十六章:基于给定的文档生成倒排索引的编码与实践;
- 从Hadhoop框架与MapReduce模式中谈海量数据处理。

