Python中多使用迭代器
英文原文出处:Use More Iterators
本文介绍将代码转换为使用迭代器的原因和实用技巧。
我最喜欢的Python语言的特色之一是生成器,它们是非常有用的,然而当阅读开源代码时,我很少遇到它们。在这篇文章中,我希望概述它们最简单的实例去鼓励任何读者更多的使用它们。
阅读这篇文章的前提是你已经知道容器和迭代器是什么,我在之前的一篇博客文章中已经解释过这些概念,并详细阐述了我们通过更多的一些思考能获得什么。
Why?
为什么使用迭代器是一个好的方法?使用迭代器编程能避免使用中间变量,可以用更短的代码,运行轻松,消耗更小的内存,运行更快,组合性强,也更加漂亮。简而言之:它们更加优雅。
"The moment you've made something iterable, you've done something magic with your code. As soon as something's iterable, you can feed it to list(), set(), sorted(), min(), max(), heapify(), sum(), ‥. Many of the tools in Python consume iterators."
“当你做了一些可迭代的事情, 你已经为你的代码做了一些魔术。一旦它变得可迭代,你就能使用ist(), set(), sorted(), min(), max(), heapify(), sum()等函数,Python中的很多工具都使用迭代器。”— Raymond Hettinger ([Transfroming Code into Beautiful, Idiomatic Python](https://www.youtube.com/watch?v=OSGv2VnC0go#t=825))
最近, Clojure为编程语言加了transducer, 这是一个与Python中的生成器非常相似的概念。(我强烈建议观看Rich Hickey 2014年在介绍它时在Strange Loop 的演讲:"Transduers" by Rich Hicky。)
在视频中, 他谈到把一个集合"puring"到另一个, 我认为这是一个动词, 非常直观地描述迭代器的性质与数据结构的关系。我将在未来的博客文章中更详细地写下这个想法。
Example
下面是一个常见的示例:
def get_lines(f):
result = []
for line in f:
if not line.startswith('#'):
result.append(line)
return result
lines = get_lines(f)
现在看看用生成器写同样功能的代码:
def get_lines(f):
for line in f:
if not line.startswith('#'):
yield line
lines = list(get_lines(f))
The Benefits
咋一看似乎没有太多不同之处,但是却有很多好处:
- No bookkeeping(没有记录本). 你不需要创建一个空列表,然后一个个添加元素到里面,并返回它,这就少使用了一个变量;
- Hardly consumes memory(几乎不耗内存). 无论输入文件有多大, 含迭代器的代码都不需要在内存中缓冲整个文件;
- Works with infinite streams(可工作在无限流状态下).
- Faster results(返回值更快). 可以立即得到返回结果, 而不是在读取整个文件之后;
- Faster speed(运行速度更快). 第二段代码相比于第一段代码需要以初始方式创建列表运行的更快;
- Composability(可组合性). 调用方式可以决定它如何使用返回结果。
最后一点也是最重要的,让我们深究它。
Composability
可组合性是关键之处。迭代器有着极强的组合性,在上面的例子中,列表是显性的创建,但是如果调用者需要一个集合呢?实际上,许多人要么写一个同样功能的基于集合的代码段,或者简单的调用函数set(),当然这是可行的,但是这非常浪费内存资源。再次想象一下这个文件很大,首先从这整个文件已经生成了一个很大的列表list,然后又使用set()通过这个列表在内存中生成一个所需要的集合set,那么原先的中间变量列表就是内存中的垃圾。
而对于使用生成器,函数只是发出“对象流”,调用者再决定将这些对象使用(puring)到什么数据类型中。
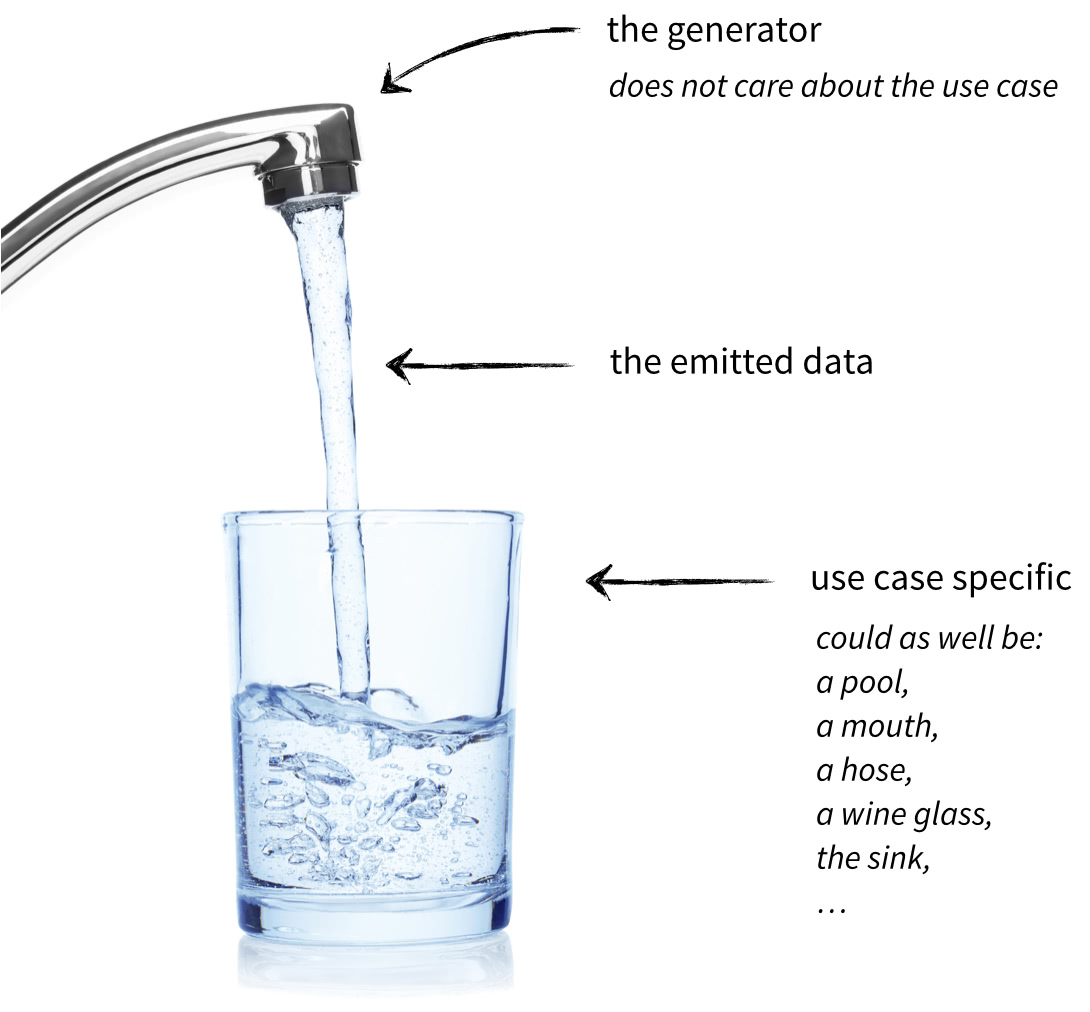
想要生成集合而不是列表?
uniq_lines = set(get_lines(f))
只想要文件中最长的一行吗?该文件将被完全读取, 但最多两行始终保存在内存中:
longest_line = max(get_lines(f), key=len)
只想要文件中的前10行吗?将从文件中读取不超过10行, 无论文件有多大:
head = list(islice(get_lines(f), 0, 10))
2013年在Pycon,Ned Batchelder 的演讲非常完美的阐述了我在这篇博文中所尝试解释的,我强烈推荐你们观看:Loop like a native: while, for, iterators, generators.
Summary
不要让中间变量在内存中存储数据,你几乎总是可以避开它们, 那么就可以获得可读性、速度、更小的内存占用空间和可组合性的回报。
< 完 >
转载请注明该译文原文链接: < https://www.cnblogs.com/tzhao/p/9874135.html >,谢谢!
