


课下测试补交(ch01、ch02、ch07)
课下测试补交(ch01、ch02、ch07)
课下测试ch01
1.Amdahl定律说明,我们对系统的某个部分做出重大改进,可以显著获得一个系统的加速比。(B)
A .
正确
B .
错误
解析:课本p16 Amdahl定律,该定律的主要思想是,当我们对系统的某个部分加速时,其对整个性能的影响取决于该部分的重要性和加速程度。
2.Linux中,内核虚拟内存在虚拟地址空间的低端。(B)
A .
正确
B .
错误
解析:课本p13 内核虚拟内存在虚拟地址空间的最顶端而不是最低端
3.实现进程这个抽象概念需要低级硬件和操作系统软件之间的紧密合作。(A)
A .
正确
B .
错误
解析:课本p12 进程是操作系统对正在运行的程序的一种抽象。一个系统上可以同时运行多个进程,每个进程好像独占的使用硬件。所谓并发,是说一个进程的指令和另一个进程的指令交错执行。操作系统实现这种交错执行的机制称为上下文切换。操作系统跟踪进程运行所需的所有状态信息(也就是上下文),任何一个时刻,处理器只能运行一个进程。当操作系统决定要把控制权从当前进程转移到一个新进程时,就要进行上下文切换,即保存当前进程的上下文,恢复新进程的上下文,然后将控制权转交给新进程,新进程就从上次停止的地方开始执行。实现进程这个抽象概念需要低级硬件和操作系统软件之间的紧密合作
4.操作系统有两个基本功能:防止硬件被滥用;向应用供一致的机制来控制低级硬件设备。实现这两个功能相关的抽象有(ACD)
A .
文件
B .
虚拟机
C .
虚拟内存
D .
进程
解析:课本p10 操作系统有两个基本功能:防止硬件被失控的应用程序滥用;向应用程序提供简单一致的机制来控制复杂的低级硬件设备。操作系统通过几个抽象的基本概念(进程、虚拟存储器和文件)来实现以上两个基本功能。
5.存储器层次结构的主要思想是(A)
A .
上一层的存储器作为低一层存储器的高速缓存
B .
存储设备形成存储层次结构
C .
存储器分为主存和辅存
D .
较大的存储器运行慢,快速设备造价高
解析:课本p10 在这个结构中,从上到下,设备容量越来越大,运行速度越来越慢,同时造价也越来越便宜。存储器层次结构的主要思想是上一层的存储器作为下一层存储器的高速缓存。上图中顶层的寄存器是L1的高速缓存,L1是L2的高速缓存,以此类推。从这个角度讲,程序员可以利用对整个存储器层次结构的理解来提高程序的性能。
6.处理器的()操作可以从寄存器中复制一个字节的数据到主存中。
A .
加载
B .
存储
C .
操作
D .
跳转
解析:课本p7
加载:把一个字节或者字从主存复制到寄存器,并覆盖寄存器原来的值。
存储:把一个字节或者字从寄存器复制到主存的某个位置,并覆盖掉主存该位置原来的值。
操作:把两个寄存器的内容复制到ALU,ALU对这两个内容做算术运算,将结果存放到一个寄存器中,并覆盖掉原来的值。
跳转:从指令本身中抽取一个字,复制到PC中,并覆盖掉PC中原来的值。
7.主存在逻辑上可以看作(A)
A .
字节数组
B .
字数组
C .
双字数组
D .
四字数组
解析:课本p6
主存储器:主存储器是一个易失性存储区,也就是常说的RAM,它是一个程序和数据的暂存场所。从逻辑上来说,存储器是一个线性的字节数组,每个字节都有其唯一的索引(也就是地址的概念)。一般不同的机器指令都有不同的字节长度。
8.主存在逻辑上可以看作(A)
A .
字节数组
B .
字数组
C .
双字数组
D .
四字数组
解析:课本p6 存储器:主存储器是一个易失性存储区,也就是常说的RAM,它是一个程序和数据的暂存场所。从逻辑上来说,存储器是一个线性的字节数组,每个字节都有其唯一的索引(也就是地址的概念)。一般不同的机器指令都有不同的字节长度。
9.I/O设备可以通过(AD)与I/O总线相连。
A .
控制器
B .
主存
C .
处理器
D .
适配器
解析:课本p5 I/O设备是计算机系统与外界通信的渠道。上图所示的USB、显示器、磁盘和键盘鼠标等都是I/O设备。I/O设备通常由机械部件和电子部件两部分组成,其中,电子部件又称为设备控制器或适配器。每一个I/O设备都是通过一个控制器与I/O总线连接。I/O设备又分为块设备和字符设备两种。上述中磁盘、USB等就是常见的块设备,而键盘鼠标和网络接口为字符设备。
10.计算机中总线传送定长的数据,这个定长是(B),是一个基本的系统参数。
A .
字节
B .
字
C .
双字
D .
四字
解析:课本p5 总线实际上就是一组电子管道,它负责计算机系统各部件之间字节信息的传递。通常总线传输一些定长的字节块,这个定长的字节块也就是字(word)的概念。一个字包含的字节数即为这个系统的字长。我们说32位的计算机的字长为4个字节,64位的计算机字长为8.
11.计算机系统的硬件组成包含(ABCD)
A .
总线
B .
I/O设备
C .
主存
D .
处理器
解析:课本p5
CPU:CPU是中央处理单元的简称。它负责解释执行存储在主存储器中的指令。CPU的核心部分为算术逻辑单元ALU、程序计数器PC和一些寄存器。其中,PC本身是一个字长的存储设备,它时时刻刻的只想主存中的某条机器语言指令。从系统上电以后,处理器从程序计数器PC指向的存储器读取指令,解释指令中的位,然后更新PC,使其指向下一条指令,具体的顺序由指令集结构所决定。
总线:总线实际上就是一组电子管道,它负责计算机系统各部件之间字节信息的传递。通常总线传输一些定长的字节块,这个定长的字节块也就是字(word)的概念。一个字包含的字节数即为这个系统的字长。我们说32位的计算机的字长为4个字节,64位的计算机字长为8.
主存储器:主存储器是一个易失性存储区,也就是常说的RAM,它是一个程序和数据的暂存场所。从逻辑上来说,存储器是一个线性的字节数组,每个字节都有其唯一的索引(也就是地址的概念)。一般不同的机器指令都有不同的字节长度。
I/O设备:I/O设备是计算机系统与外界通信的渠道。上图所示的USB、显示器、磁盘和键盘鼠标等都是I/O设备。I/O设备通常由机械部件和电子部件两部分组成,其中,电子部件又称为设备控制器或适配器。每一个I/O设备都是通过一个控制器与I/O总线连接。I/O设备又分为块设备和字符设备两种。上述中磁盘、USB等就是常见的块设备,而键盘鼠标和网络接口为字符设备。`
12.熟悉编译系统的好处有:(ABD)
A .
优化程序性能
B .
理解链接时出现的错误
C .
有助于设计处理器
D .
避免安全漏洞
解析:课本p4
B:在我们的经验里,一些最令人困惑的错误都与链接器操作相关,尤其是当你尝试构建大型软件系统时。例如,当连接器报告它不能解析一个引用时意味着什么?静态变量和全局变量的的区别是什么?如果你在不同的C文件中定义两个相同名字的全局变量会发生什么?静态库和动态库的区别是什么?为什么我们在命令行列举库的顺序是重要的?最吓人的是,为什么链接器相关的错误在运行时才出现?你将在第七章得到这些问题的答案。
D:许多年来,缓存溢出缺陷已经引起了网络和互联网服务器中的大部分安全漏洞。这些缺陷之所以存在,是因为几乎没有程序员理解去仔细限制从不可信源接收到的数据的数量和形式的必要性。学习安全编程的第一步是数据和控制信息被存储在程序栈的方式所导致的结果。在第三章,我们讲解栈的问题和缓存溢出缺陷作为我们汇编语言学习的一部分。我们也会学到一些方法,这些方法能被程序员,编译器,操作系统用来减少被攻击的威胁。
13.熟悉编译系统的好处有:(ABD)
A .
优化程序性能
B .
理解链接时出现的错误
C .
有助于设计处理器
D .
避免安全漏洞
解析:课本p4
14.gcc 把源程序翻译成可执行文件的四个阶段是:预处理阶段,编译阶段,汇编阶段,链接阶段,其中汇编阶段用到的工具和相应的gcc命令是(C)
A .
cpp: gcc -E hello.c -o hello.i
B .
ccl: gcc -S hello.i -o hello.s
C .
as: gcc -c hello.s -o hello.o
D .
ld: gcc hello.o -o hello
解析:gcc命令:ESc, 生成文件后缀iso
预处理阶段:使用预处理器cpp,相应命令是: gcc -E hello.c -o hello.i
编译阶段:使用编译器ccl,相应命令是: gcc -S hello.i -o hello.s
汇编阶段:使用汇编器as,相应命令是:gcc -c hello.s -o hello.o
链接阶段:使用链接器ld,相应命令是: gcc hello.o -o hello
15.(B)就是位+上下文
A .
数据
B .
信息
C .
知识
D .
数据结构
解析:信息就是位+上下文:计算机系统中的所有信息都是由二进制串表示的,区分这些数据对象的唯一方法是读到这些数据的上下文。
课下测试ch02
1.假设下面位串是基于IEEE格式的5位浮点表示,一个符号位,2个阶码位,两个小数位。下面正确的是(AD)
A .
3.5的表示是[01011]
B .
-1.0的表示[01111]
C .
0.5的表示是[00011]
D .
1.5的表示是[00110]
解析:课本p78
IEEE浮点表示:
符号:s通过其值1负和0正决定V的正负,对于V=0另作解释。
尾数:M是一个二进制小数,它的范围是1 – 2-ε,或者0 – 1-ε
阶码:E的作用是对浮点数加权,权重是2的E次幂(可能是负数)
2.下面可以用二进制精确表示的数有(ACD)
A .
1/2
B .
1/3
C .
1/4
D .
3/8
E .
5/7
解析:课本pp76 假定我们仅考虑有限长度的编码,呢么十进制表示法不能准确的表达像1/3和5/7这样的数。类似,小数的二进制表示法只能表示那些能够被写成 x*2^y
3.对于int x; float f; double d;下面正确的是(ACD)
A .
x == (int)(double)x
B .
x==(int)(float)x
C .
f == -(-f)
D .
1.0/2 == 1/2.0
E .
(f+d)-f == d
解析:课本p86
从int ---> float可能会发生舍入,但是不会发生溢出
从int --> double,如果Int的值是在53位以下的(包括53位),会得到一个精确的转换。
从float --> double, 我们会得到一个精确的转换因为double的精度远远大于float的精度
从float, double -- > int,这样的转化可能会有问题,一个是从单精度浮点数到Int,由于阶码的存在,要调整尾数的尾数,所以在移位操作的时候可能会丢掉一些低有效位。并且这样的转化会按照向0舍入的操作去进行处理数据。另一个问题是浮点数可能会远远大于或者小于整型能够表示范围,因此我们把两种类型的浮点数的比整型最小值还要小的变为Tmin,并且一些在浮点数中特殊的值,我们会将它们都转化为Tmin或者Tmax。
4.有关二进制小数的表述,正确的是(AD)
A .
0.125表示为[0.001]
B .
0.125表示为[0.0001]
C .
3.1875表示为[11.00111]
D .
3.1875表示为[11.0011]
解析:课本p76
5.有关三位数x,y的乘积x*y截断为四位,下面说法正确的是(AC)
A .
无符号的[100]*[101]结果为4
B .
无符号的[100]*[101]结果为-4
C .
有符号的[100]*[101]结果为-4
D .
有符号的[100]*[101]结果为4
解析:课本p67
对于一个 w 位的无符号二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 0 <= x <= 2w-1.
如果两个无符号数相乘,那么其结果应该是 0 <= x*y <=(2w-1)2=22w-2w+1+1。很显然表示这个范围的数可能需要 2w 位来表示。也就是 2w 位的整数乘积的低 w 位表示的值。根据我们前面讲的截断原理:可以看做是计算乘积模2w
6.我们用一个十六进制的数表示长度w=4的位模式,把数字解释为补码,关于其加法逆元的论述正确的是(ABDE)
A .
0x8的加法逆元是-8
B .
0x8的加法逆元是0x8
C .
0x8的加法逆元是8
D .
0xD的加法逆元是3
E .
0xD的加法逆元是0x3
解析:p66
对于补码加法运算,因为补码编码是表示有符号的整数。
对于一个 w 位的补码二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 -2w-1 <= x <= 2w-1-1。那么 -2w <= x+y <=2w-1
想要表示上面的两个数相加和的范围,那么可能需要 w+1 来表示。这里我们也需要截取。
与无符号加法运算不同,补码加法会出现三种情况:正溢出、正常、负溢出。
7.大多数计算机使用同样的机器指令来执行无符号和有符号加法。(A)
A .
正确
B .
错误
C .
不确定
解析:p63 两个数的w位补码之和与无符号之和有完全相同的位级表示。实际上,大多数计算机使用相同的机器指令来执行无符号或有符号加法。
8.我们用一个十六进制的数表示长度w=4的位模式,对于数字的无符号加法逆元的位的表示正确的是(ACD)
A .
0x8的无符号加法逆元是0x8
B .
0xD的无符号加法逆元是0xD
C .
0xF的无符号加法逆元是0x1
D .
0xF的无符号加法逆元是1
解析:p62
9.0<=x,y<2^w, 则(F)
A .
x+y的最大值是2^w
B .
x+y的最大值是2^w-1
C .
x+y的最大值是2^w-2
D .
x+y的最大值是2^(w+1)
E .
x+y的最大值是2^(w+1)-1
F .
x+y的最大值是2^(w+1)-2
解析:课本p60
对于一个 w 位的无符号二进制整数[xw-1 , xw-2 , … , x2 , x1 , x0],其值大小满足 0 <= x <= 2w-1.
如果两个无符号数相加,那么其结果应该是 0 <= x+y <=2w+1-2。很显然表示这个范围的数必须要 w+1 位二进制。
当我们对无符号数做加法运算的时候,如果结果超过了 2w-1,那么这个结果就会失真。
10.计算机中x<y 和x-y<0总是等价的。(A)
A .
错误
B .
正确
C .
不确定
解析:课本p60 比较表达式x<y和x-y<0时会产生不同的结果,比如,数的类型决定了数的大小范围,当X很大,y为一个很小的负数。。溢出
11.C语言数据类型转化时,先改变大小,还是先改变无符号和有符号对程序的结构没有影响。(A)
A .
错误
B .
正确
C .
不确定
解析:C语言中提供了很多整数类型(整型),主要区别在于它们取值范围的大小。int代表有符号的整数,也就是说,用int声明的变量可以是正数也可以是负数,也可以是零,但是只能是整数。
比如:int a = 3; int b = 0; int c = -5;
以上这些都是合法的。
12.short sx=-12345;
int x = sx;
unsigned ux = sx;
(ACD)
A .
sx,x,ux的十六进制表示中的最后两个字节是0xcfc7
B .
ux == 0xffffcfc7
C .
ux == 0x0000cfc7
D .
x == 0xffffcfc7
E .
x == 0x0000cfc7
解析:课本p54 扩展一个数字的位,简单来说就是在不同字长的整数之间转换,而这种转换我们可以需要保持前后数值不变。当然将一个数据转换为字长更小的数据类型的时候,它的值肯定会发生变化。那么我们只能将较小的数据类型转换为较大的数据类型。比如将短整型short int 转换为整型 int。
13.在采用补码运算的32位机器上,下列表达式的结果为0的是(C)
A .
-2147483647-1 == 2147483647U
B .
-2147483647-1 < 2147483647
C .
-2147483647-1U < 2147483647
D .
-2147483647-1 < -2147483647
解析:课本p53 尽管 C 语言标准没有指定有符号数要采用某种编码表示,但是几乎所有的机器都使用补码。通常大多数数字是默认有符号的,比如当声明一个像12345或者0xABC这样的常量的时候,这个值就被认为是有符号的。
14.short int v=-12345;
unsigned short uv=(unsigned short) v;
那么(AB))
A .
v=-12345, uv=53191
B .
v=uv=0xcfc7
C .
v,uv的底层的位模式不一样
D .
v,uv的值在内存中是不一样的
解析:课本p49, 有符合数和无符号数的转换,值不同,位模式不变,要深入理解”信息=位+上下文“
15.B2T([1100])= (B)
A .
12
B .
-4
C .
3
D .
以上都不对
解析:课本p45 ,补码,取反加一
16.B2U([1100])=( A )
A .
12
B .
3
C .
-4
D .
以上都不对
解析:p44 无符号编码
17.int x; x的二进制为[10010101], x>>4的值为(C)
A .
[10010101]
B .
[00001001]
C .
[11111001]
D .
[01010000]
解析:课本p40 有符号数进行算术右移
18.a=[0010], b=[1100], a||b的值是(A)
A .
非零(TRUE)
B .
[1110]
C .
[0000]
D .
零(FALSE)
解析:课本p39 注意区分逻辑运算和位运算
19.a=[0010], b=[1100], a|b的值是(B)
A .
非零(逻辑真)
B .
[1110]
C .
[0000]
D .
零(逻辑假)
解析:课本p36,区分逻辑运算和位运算
20.计算机系统的一个基本概念是,从机器角度看,程序仅仅是(B)
A .
字符序列
B .
字节序列
C .
汇编代码序列
D .
ascii码序列
解析:课本p35
从机器角度看,程序仅仅是字节序列
21.C语言中"0",'0',"\0",0是等价的。(B)
A .
正确
B .
错误
解析:字符串与字符,ascii码与字符要区分清楚
22.C语言中,字符串被编码为一个以0结尾的字符数组。(A)
A .
正确
B .
错误
解析:课本p34, null的值是0
23.下面和代码可移植性相关的C语言属性有(ABC)
A .
define
B .
typedef
C .
sizeof()
D .
union
解析:#define可以定义宏使得变量可移植,typedef可以使得类型可移植,sizeof()使得不同类型长度可移植。
24.x=0x12345678,存放在0x200-0x203地址中,小端机器中0x201中的内容是(C)
A .
0x12
B .
0x34
C .
0x56
D .
0x78
解析:p29 小端机器“高对高,低对低”,大端相反
25.整数int x在内存中的地址是0x200,0x201,0x202,0x203,那么&x的值是(B)
A .
不同机器上(大端,小端)不一样
B .
0x200
C .
0x203
D .
0x200-0x203
解析:课本p29 对象地址为所用字节中的最小地址
26.与unsigned long等价的声明是(BCD)
A .
unsigned
B .
long unsigned
C .
long unsigned int
D .
unsigned long int
解析:课本p28 对关键字的顺序以及包括还是省略可选关键字来说,C语言允许存在多种形式,比如:下面声明都是一个意思
27.long类型的长度(A)
A .
不同机器上(32位机,64位机)不一样
B .
固定2字节
C .
固定4字节
D .
固定8字节
解析:课本p27 计算机和编译器支持多种不同方式编码的数字格式,比如整数和浮点数,以及其它长度的数字。而且由于计算机位数的不同,会造成计算机在各种数据类型分配的字节数不一样。
28.uint_32的长度是(C)
A .
不同机器上不一样
B .
固定2字节
C .
固定4字节
D .
固定8字节
解析:课本p27
29.要在64位机器上把prog.c编译出可以在32机器上运行的程序,下面正确的是(C)
A .
64位机上不能编译出32位机的程序
B .
gcc prog.c
C .
gcc -m32 prog.c
D .
gcc -m64 prog.c
解析:课本p27 大多数64位机器也可以运行32位机器编译的程序,
其命令是
linux>gcc -m32 prog.c
30.字长32位的机器,虚拟地址空间范围是(C)
A .
1-32
B .
0-31
C .
0-2^32-1
D .
1-2^32
解析:课本p27 字长32位的机器虚拟空间范围
31.0x503c + 64 = (B)
A .
0x50A0
B .
0x507c
C .
0x506C
D .
0x50B0
解析:64是十进制,要化成16进制0x40进行计算。
32.一个数x是2的n次方,n=i+4*j,i=2,j=8时,用16进制表示x,最高位是(B)
A .
2
B .
4
C .
8
D .
0
解析:p26
一个字节由 8 位组成。在二进制表示法中,它的值域为 00000000——11111111;如果用十进制表示就是0——255。这两种表示法用来描述计算机中的位模式(计算机中所有二进制的0、1代码所组成的数字串)来说都不是很方便。二进制表示法太冗长,而十进制表示法与位模式的互相转化又比较麻烦。这时候 十六进制数产生了,十六进制使用数字‘0’~‘9’,以及字符 ‘A’~'F’来表示16个可能的值。一般是 0x 或者 0X 开头。规则是:借一当十六,逢十六进一。
比如十进制数 175,我们用十六进制表示为 0xAF。
33.实现十进制数向各种进制(2,8,16)的转换,可以使用数据结构中的(B)来实现。
A .
堆
B .
栈
C .
队列
D .
树
解析:课本p26 进位计数制的要素:
①、数码:用来表示进制数的元素。比如二进制数的数码为:0,1。十进制数的数码为:0,1,2,3,4,5,6,7,8,9。十六进制数的数码为:0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F
②、基数:数码的个数。比如二进制数的基数为2。十进制数的基数为10。十六进制数的基数为 16.
③、位权:数制中每一固定位置对应的单位值称为位权。例如十进制第2位的位权为10,第3位的位权为100;而二进制第2位的位权为2,第3位的位权为4,对于 N进制数,整数部分第 i位的位权为N(i-1),而小数部分第j位的位权为N-j。
34.64位机器上,机器级程序将内存视为(A)数组,称为虚拟内存
A .
字节
B .
字(16位)
C .
双字(32位)
D .
四字(64位)
解析:课本p24 计算机内所有的信息均以二进制的形式表示,也就是由值0和值1组成的序列。大多数计算机使用8位的块,或者说字节("位(bit)"是电子计算机中最小的数据单位,每一位的状态只能是0或1。8个二进制位构成1个"字节(Byte)"),来作为最小的可寻址的存储器单位,而不是在存储器中访问单独的位。
35.根据c89国际标准编译程序prog.c,下面正确的是(BC)
A .
gcc prog.c
B .
gcc -ansi prog.c
C .
gcc -std=c89 prog.c
D .
gcc -std=gnull prog.c
解析:课本p24 在国际c89标准编译程序中有gcc -ansi prog.c,gcc -std=c89 prog.c两条指令完成
36.根据结合律,在大多数计算机上,(3.1415926+1e22)-1e22与3.1415926+(1e22-1e22)的值相等,都是3.1415926.(B)
A .
正确
B .
错误
解析:课本p22
37.计算机中用来表有符号整数的编码方式是(B)
A .
无符号编码
B .
补码编码
C .
有符号编码
D .
浮点数编码
解析:课本p22 补码编码是表示有符号整数的最常见方式。
课下测试ch07
1.Linux中()可以列出一个可执行文件在运行时所需的共享库(D)
A .
nm
B .
objdump
C .
strip
D .
ldd
2.把add.c sub.c mul.c div.c编译成一个共享库libmath.so的命令是(A)
A .
gcc -shared -fpic -o libmath.so add.c sub.c mul.c div.c
B .
gcc -o libmath.so add.c sub.c mul.c div.c
C .
ar -o libmath.so add.c sub.c mul.c div.c
D .
ar -shared -fpic -o libmath.so add.c sub.c mul.c div.c
3.main.c 调用了静态库libmath.a中的函数,编译main.c的命令是(AB)
A .
gcc -static main.c ./libmath.a -o main
B .
gcc -static main.c -L. -lmath -o main
C .
gcc -static main.c -L. -llibmath.a -o main
D .
gcc -static main.o ./libmath.a -o main
4.把sub.o,add.o,mul.o,div.o制作成一个静态库libmath.a的命令是(A)
A .
ar rcs libmath.a sub.o add.o mul.o div.o
B .
rar rcs libmath.a sub.o add.o mul.o div.o
C .
ar rcs sub.o add.o mul.o div.o libmath.a
D .
rar rcs sub.o add.o mul.o div.o libmath.a
5.

针对以上代码:gcc -c *.c 可以得到m.o,swap.o两个模块,相对于m.o, buf是(B)
A .
外部符号
B .
全局符号
C .
局部符号
D .
以上都不对
解析:课本p468
6.
针对以上代码:gcc -c *.c 可以得到m.o,swap.o两个模块,哪些符号会出现在swap.o模块的.symtab条目中(ACD)
A .
buf
B .
temp
C .
swap
D .
buffp0
解析:temp是局部变量,不出现在符号表中。
7.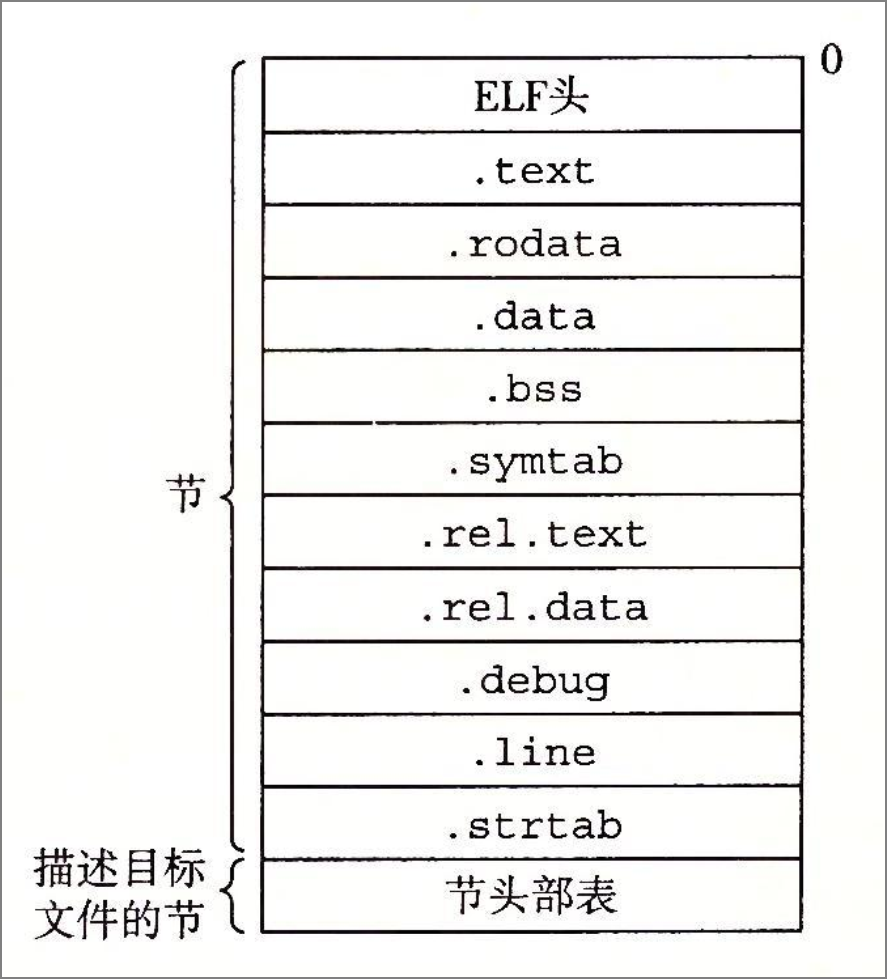
用gcc hello.c -o hello 编译hello.c,hello中不存在(AC)节
A .
.debug
B .
.text
C .
.line
D .
.rodata
8.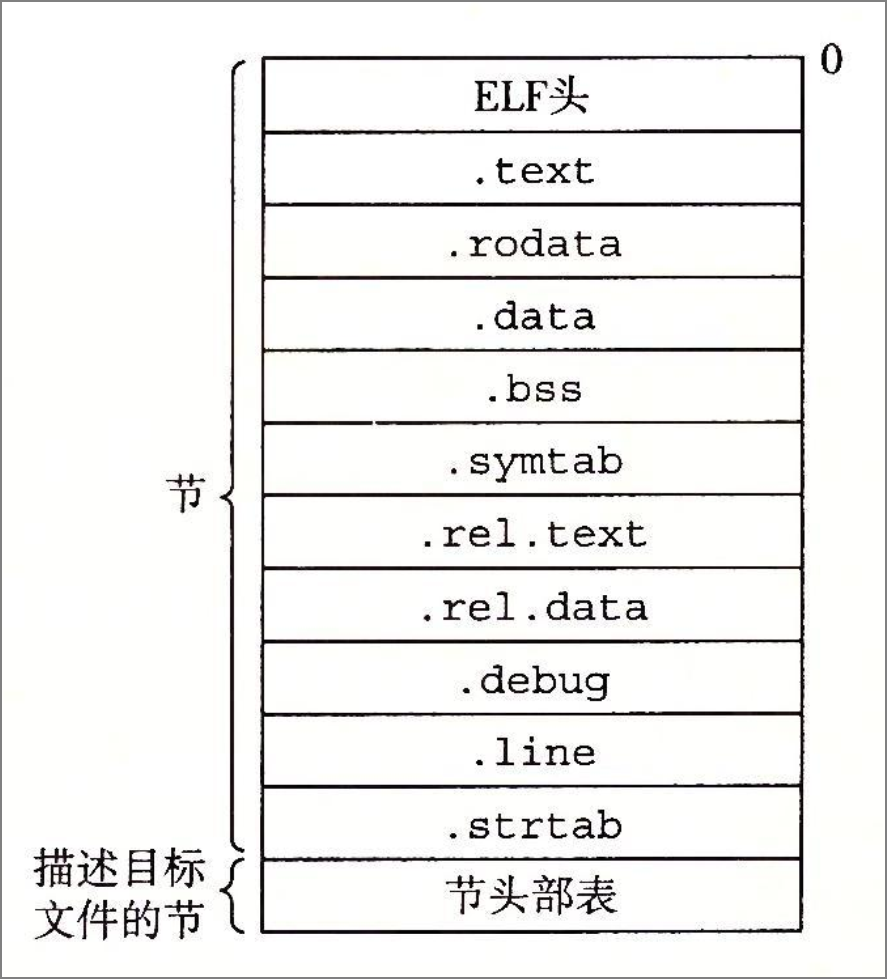
上图中(B)节包含符号表。
A .
.text
B .
.symtab
C .
.data
D .
.debug
9.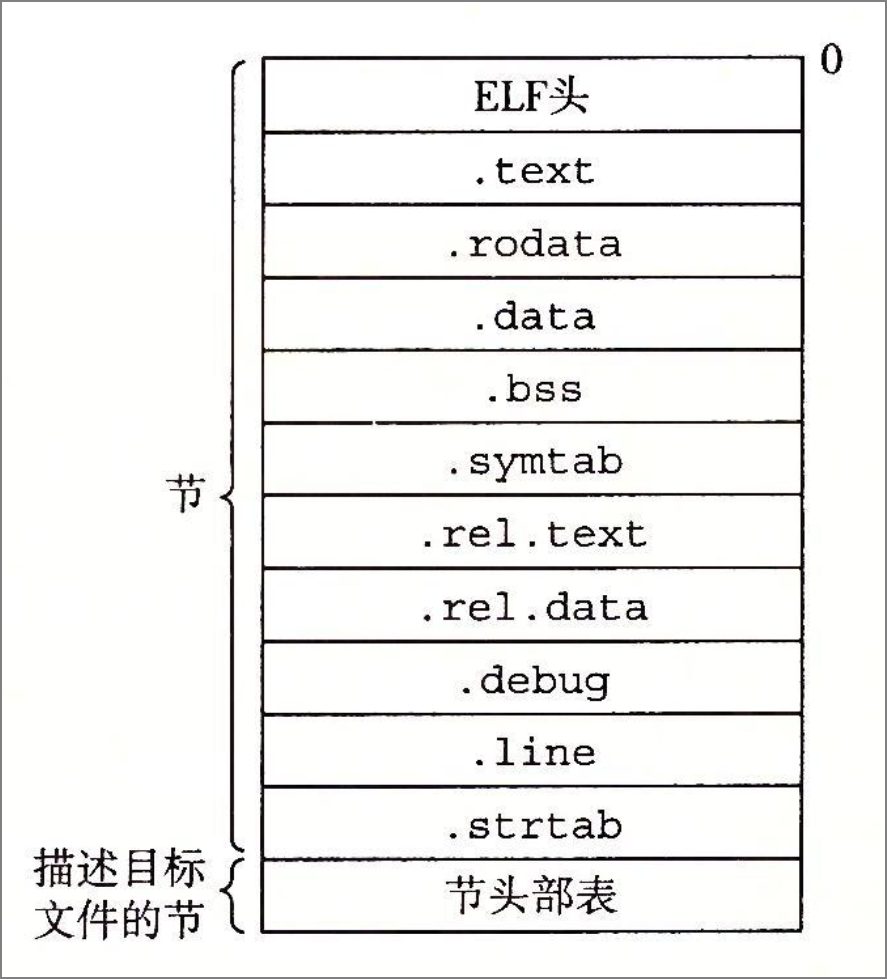
上图是典型的ELF的可重定位目标文件的格式,对于代码:
int a[100] ={0};
int b[100];
int main()
{
int i=0;
for(i=0; i<100; i++)
b[i] = i;
printf("the b[3]= %d\n", b[3]);
return 1;
}
其中b[100]存放在(C)节
A .
.text
B .
.data
C .
.bss
D .
.rodata
解析:全局未初始化的数据放在bss节
10.Windows 下的目标文件格式是(C)
A .
ELF
B .
COFF
C .
PE
D .
a.out
解析:课本p467
11.gcc hello.c产生的a.out属于(B)
A .
可重定位目标文件
B .
可执行目标文件
C .
共享目标文件
D .
目标模块或目标文件
解析:课本p466
12.Linux中,目标文件XXX.o中的代码和数据节是从地址0开始的。(A)
A .
正确
B .
错误
解析:课本p466
13.为了构造可执行文件,连接器的主要任务有(BD)
A .
生成静态库
B .
符号解析
C .
生成共库
D .
重定位
解析:课本p466
14.Linux中创建可执行目标文件需要调用(D)
A .
cpp
B .
ccl
C .
as
D .
ld
解析:课本p466
15.编译驱动程序gcc -c 会调用(C)
A .
预处理器
B .
编译器
C .
汇编器
D .
链接器
16.无论什么样的操作系统,ISA或者目标文件格式,基本的链接概念是通用的。(A)
A .
正确
B .
错误
解析:课本p465
17.链接器的重要性在于可以支持(C)
A .
静态库
B .
动态库
C .
分离编译
D .
调试
解析:课本p464
18.dll,so文件的链接是运行在(C)
A .
编译时
B .
加载时
C .
运行时
D .
链接时
