
20135220谈愈敏--信息安全系统设计基础第八周学习总结
第十章 系统级I/O
输入/输出(I/O)是在主存和外部设备之间拷贝数据的过程。
输入操作:从I/O设备拷贝数据到主存
输出操作:从主存拷贝数据到I/O设备
所有语言运行时系统都提供执行I/O的较高级别的工具,为什么还要学习Unix I/O呢?
了解Unix I/O将帮助你理解其他的系统概念。I/O是系统操作不可或缺的一部分
有时你除了使用Unix I/O以外别无选择
10.1 Unix I/O
一个Unix文件就是一个m个字节的序列,所有的I/O设备,都被模型化为文件,而所有的输入输出都被当作对相应文件的读和写来执行,Unix内核引出一个简单、低级的应用接口:Unix I/O。
所有的输入输出都能以一种统一且一致的方式来执行:
打开文件:一个应用程序想访问I/O设备时会要求内核打开相应的文件,内核返回一个小的非负整数,叫做描述符。
它在后续对此文件的所有操作中标识这个文件。内核记录有关这个文件的所有信息,应用程序只需记住描述符。
每个进程开始时都有三个打开的文件:标准输入(描述符为0)、标准输出(描述符为1)、标准错误(描述符为2)
改变当前的文件位置:对于每个打开的文件,内核保持着一个文件位置k,初始为0,文件位置是从文件开头起始的字节偏移量。
应用程序能够通过执行seek操作,显示的设置文件的当前位置为k。
读写文件:读操作是从文件拷贝n>0个字节到存储器,从当前位置k开始,将k增加到k+n
当k>=m时执行读操作会触发一个称为end-of-file(EOF)的条件,应用程序能检测到这个条件。
写操作就是从存储器拷贝n>0个字节到一个文件,从当前位置k开始,然后更新k。
关闭文件:当应用完成对文件的访问,会通知内核关闭文件。
作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中。
无论进程因何种原因终止,内核都会关闭所有打开的文件并释放他们的存储器资源。
10.2 打开和关闭文件
通过调用open函数来打开一个已存在的文件或创建一个新文件:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename,int flags,mode_t mode);
返回:若成功则为新文件描述符,若出错为-1
open函数将filename转换为一个文件描述符并返回。
flags指明了进程打算如何访问这个文件:
O_RDONLY:只读
O_WRONLY:只写
O_RDWR:可读可写
flags参数也可以是一个或更多位掩码的或:
O_CREAT:如果文件不存在就创建一个截断的(空)文件
O_TRUNC:如果文件已经存在,就截断它。
O_APPEND:每次写操作前,设置文件位置到文件的结尾处。
mode参数指定了新文件的访问权限位,具体符号如图所示:
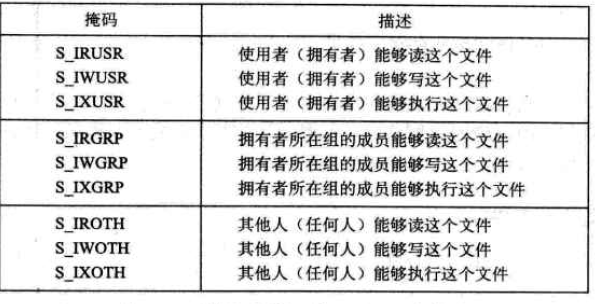
每个进程都有一个umask,是通过调用umask函数来设置的。当进程通过带某个mode参数的open函数调用来创建一个新文件时,文件的访问权限位被设置为mode & ~umask
进程通过调用close函数关闭一个打开的文件:
#include <unistd.h>
int close(int fd);
返回:若成功则为0,若出错则为-1
10.3 读和写文件
应用程序是通过分别调用read和write函数来执行输入输出的:
#include <unistd.h>
ssize_t read(int fd,void *buf,size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错为-1
ssize_t write(int fd,const void *buf,size_t n);
返回:若成功则为写的字节数,若出错则为-1
read函数从描述符为fd的当前文件位置拷贝最多n个字节到存储器位置buf。
write函数从存储器位置buf拷贝至多n个字节到描述符fd的当前文件位置。
在某些情况下,read和write传送的字节比应用程序要求的要少,这些不足值不表示有错误,原因如下:
-
读时遇到EOF
-
从终端读文本行
-
读和写网络套接字(socket)
10.4 用RIO包健壮地读写
RIO包会自动处理不足值,提供了方便、健壮和高效的I/O。RIO提供了两类不同的函数:
无缓冲的输入输出函数:直接在存储器和文件之间传送数据,没有应用级缓冲。
对二进制数据读写尤其有用。
带缓冲的输入函数:高效的从文件中读取文本行和二进制数据,这些文件的内容缓存在应用级缓冲区内。
是线程安全的,它在同一个描述符上可以被交错的调用。
10.4.1 RIO的无缓冲的输入输出函数
通过调用rio_readn和rio_writen函数,应用程序可以直接在存储器和文件之间传送数据。
#include "csapp.h"
ssize_t rio_readn(int fd,void *usrbuf,size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错为-1
ssize_t rio_writen(int fd,void *usrbuf,size_t n);
返回:若成功则为写的字节数,若出错则为-1
rio_readn函数从描述符为fd的当前文件位置传送最多n个字节到存储器位置usrbuf。
rio_writen函数从存储器位置usrbuf传送n个字节到描述符fd的当前文件位置。
对同一个描述符,可以任意交错的调用上述两函数。
如果rio_readn和rio_writen函数被一个从应用信号处理程序的返回中断,那么每个函数都会手动地重启read或write。
10.4.2 RIO的带缓冲的输入函数
文本行是由换行符结尾的ASCII码字符序列。
包装函数rio_readlineb:从一个内部读缓冲区拷贝一个文本行,当缓冲区变空时,会自动地调用read重新填满缓冲区。
rio_readn带缓冲区的版本
rio_readnb:对于既包含文本行也包含二进制数据的文件,也是从读缓冲区中传送原始字节。
#include "csapp.h"
void rio_readinitb(rio_t *rp,int fd);
ssize_t rio_readlineb(rio_t *rp,void *usrbuf,size_t maxlen);
ssize_t rio_readnb(rio_t *rp,void *usrbuf,size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错为-1
每打开一个描述符都会调用一次rio_readinitb函数
将描述符fd和地址rp处的一个类型为rio_t的读缓冲区联系起来。
rio_readlineb函数从文件rp读出一个文本行,包括结尾换行符,拷贝到存储器位置usrbuf,并用空字符来结束这个文本行。最多读maxlen-1个字节,余下的一个留给结尾的空字符。超过maxlen-1个字节的文本行被截断并用空字符结束。
rio_readnb函数从文件rp最多读n个字节到存储器位置usrbuf。
对同一描述符,可以任意交叉调用上述两函数。但带缓冲的不应和无缓冲的交叉使用。
RIO读程序的核心是rio_read函数。
rio_read函数是Unix read函数的带缓冲的版本。
当调用rio_read函数要求读n个字节时,读缓冲区内有rp->rio_cnt个未读字节。
如果缓冲区为空,会调用read填满它。
一旦缓冲区非空,rio_read就从读缓冲区拷贝n和rp->rio_cnt中较小值个字节到用户缓冲区,并返回拷贝字节数。
10.5 读取文件元数据
应用程序能够通过调用stat和fstat函数,检索到关于文件的信息,即文件的元数据。
#include <unistd.h>
#include <sys/stat.h>
int stat(const char *filename,struct stat *buf);
int fstat(int fd,struct stat *buf);
返回:若成功则为0,若出错则为-1.
stat函数以一个文件名作为输入,并填写一个stat数据结构中的各个成员。

fstat函数是相似的,只不过是以文件描述符作为输入。
st_size成员包含了文件的字节数大小
st_mode成员编码了文件访问许可位和文件类型:普通文件/目录文件/套接字
Unix提供的宏指令根据st_mode成员来确定文件类型:
S_ISREG():这是一个普通文件吗?
S_ISDIR():这是一个目录文件吗?
S_ISSOCK():这是一个网络套接字吗?
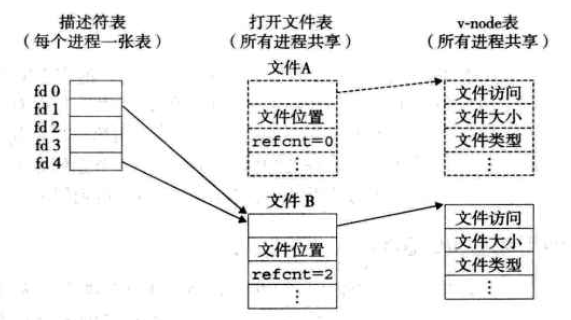
10.6 共享文件
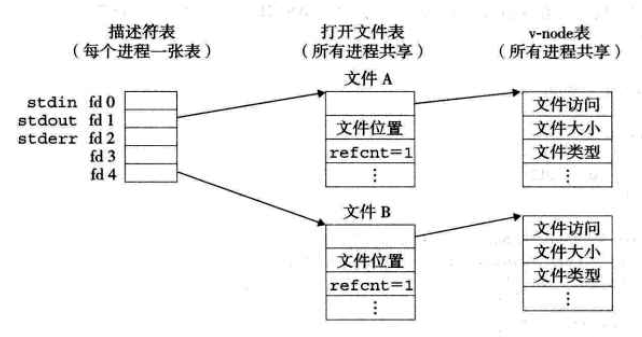
内核用三个相关的数据结构来表示打开的文件:
-
描述符表:每个进程都有独立的描述符表,由进程打开的文件描述符来索引,每个打开的描述符表项指向文件表中的一个表项。
-
文件表:所有进程共享,表项组成包括当前文件位置、引用计数、一个指向v-node表中对应表项的指针。引用计数为0时,内核会删除这个文件表表项。
-
v-node表:所有进程共享,每个表项包含stat结构中的大多数信息。
例:两个描述符通过不同的打开文件表表项来引用两个不同的文件,没有共享
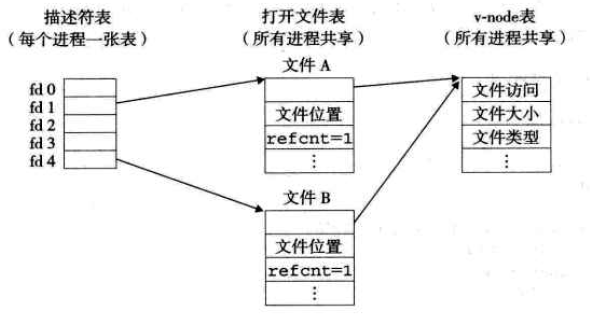
例:多个描述符通过不同的文件表表项来引用同一个文件
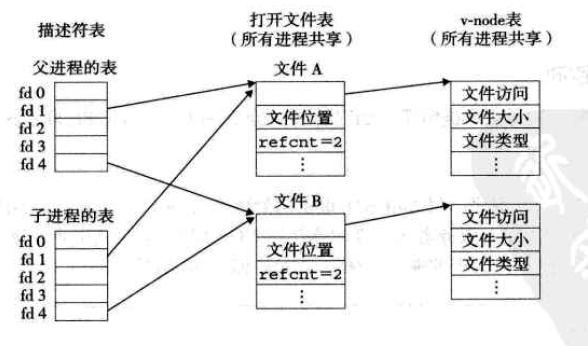
例:父子进程共享相同的打开文件表集合,共享相同的文件表位置。
10.7 I/O重定向
I/O重定向:使用dup2函数
#include <unistd.h>
int dup2(int oidfd,int newfd);
返回:若成功则为非负的描述符,若出错则为-1
dup2函数拷贝描述符表表项oldfd到newfd,覆盖newfd以前的内容,如果newfd已经打开了,dup2会在拷贝之前关闭newfd。
例:图3中调用dup2(4,1)后,两个描述符都指向文件B,文件A被关闭并且它的文件表和v-node表也被删除了,文件B的引用计数增加。
10.8 标准I/O
标准I/O库(libc):高级输入输出函数
fopen/fclose:打开和关闭文件
fread/fwrite:读和写字节
fgets/fputs:读和写字符串
scanf/printf:复杂格式化的I/O函数
标准I/O库将一个打开的文件模型化为一个流,一个流就是一个指向FILE类型的结构指针。
每个程序开始时都有三个打开的流:
stdin:标准输入
stdout:标准输出
stderr:标准错误
类型为FILE的流是对文件描述符和流缓冲区的抽象,流缓冲区的目的:使开销较高的Unix I/O系统调用的数量尽可能的小。
附录A 错误处理
错误处理包装函数:给定某个基本的系统级函数foo,定义一个有相同参数的包装函数Foo。包装函数调用基本函数并检查错误。如果发现错误就打印一条信息并终止进程,否则返回调用者。即如果没有错误,包装函数的行为与基本函数完全一样。
包装函数被封装在一个源文件(csapp.c)中,被编译和链接到每个程序中。
A.1 Unix系统中的错误处理
1、Unix风格的错误处理
if((pid = wait(NULL)) < 0) {
fprintf(stderr,"wait error:%s\n",strerror(errno));
exit(0);
}
函数返回值既包括错误代码又包括有用的结果。如果遇到错误就返回-1,并将全局变量errno设置为指明错误原因的错误代码。如果成功就返回有用的结果。
2、Posix风格的错误处理
if((retcode = pthread_create(&tid,NULL,thread,NULL)) != 0) {
fprintf(stderr,"pthread_create error:%s\n",strerror(retcode));
exit(0);
}
只用返回值来表明成功(0)或者失败(非0)。任何有用的结果都返回在通过引用传递进来的函数参数中。
3、DNS风格的错误处理
if((p = gethostbyname(name)) == NULL) {
fprintf(stderr,"gethostbyname error:%s\n:",hstrerror(h_errno));
exit(0);
}
在失败时返回NULL指针,并设置全局变量h_errno。
4、错误报告函数小结
#include "csapp.h"
void unix_error(char *msg);
void posix_error(int code,char *msg);
void dns_error(char *msg);
void app_error(char *msg);
app_error函数是为了方便报告应用错误,它只是简单地打印它的输入,然后终止。
A.2 错误处理包装函数
-
Unix风格的错误处理包装函数
-
Posix风格的错误处理包装函数
-
DNS风格的错误处理包装函数
学习总结
这章的内容相对比较简单,也比较简短,前面总的介绍了输入输出函数的统一方式,就是我认为的一般步骤:打开文件,改变当前的文件位置,读写文件,关闭文件,而后的各节分别就每个步骤进行了更详细一些的说明与介绍,以大概的函数格式描述了各个步骤,让我们先学概念,再进行实用,整章下来,思绪联系很紧密,从总到分,让人接受起来也更容易,而附录A介绍了各种风格的错误处理与对应的错误处理包装函数,扩充我们的认知,了解到更多。
参考资料
课本第十章,附录A,其中截图均来自《深入理解计算机系统》pdf版。
实践内容
根据老师所给的实践代码,在虚拟机中运行了各个代码,理解代码功能及内容。首先是要把代码拷贝到共享文件夹,经过编译之后再运行测试。
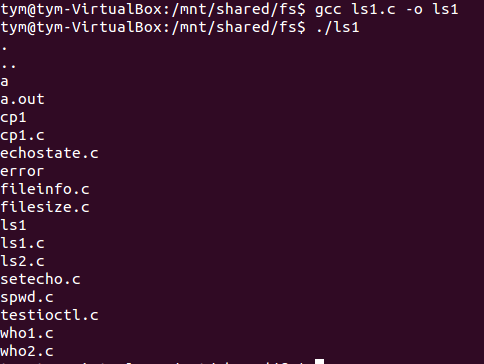
ls
ls老师给了两个代码,第一个实现功能显示当前文件家内容,第二个在第一个的基础上更加完善,还可显示出文件的详细信息,如读写权限,大小和创建时间等。
ls实现的功能:
ls -l
ls -a
ls -lu:最后访问时间
ls -s:以块为单位的文件大小
ls -t:按时间排序
ls -F:显示文件类型
列出文件目录
显示文件信息
文件树
文件和目录被组织成目录树(tree),节点是目录或者文件
目录是一种特殊文件,文件内容就是目录和文件的名字,与utmp类似
与文件不同,目录不会为空
伪代码:
打开目录文件
针对目录文件
读取目录条目
显示文件名
关闭文件目录文件
如下是运行过程:

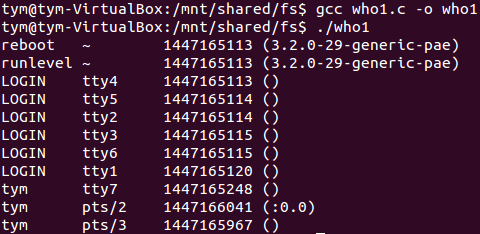
who
who也有两个代码,运行的结果是一样的,代码实现的功能是一样的,主要是从UTMP_FILE文件中读取信息到存储器中,然后再用标准输出函数打印到屏幕上,最后关闭文件。
打开utmp文件
针对文件
读取一条记录
显示记录
关闭文件
如下是运行过程:

cp
用来复制文件,函数大致步骤:
打开源文件
创建目标文件
针对源文件
把源文件读入缓冲区
把缓冲区内容写入目标文件
关闭源文件和目标文件
cp命令使用格式:cp src dst
运行以下命令:实现复制操作

操作之后cp1.c里面的内容被更改:

setecho & echostate
setecho:是设置echo值的一个函数,输入yes后,键盘键入命令是可见的,而输入no后,键盘键入命令是不可见的,但是依然是可执行的。
echostate:这个函数是用来检查键盘键入命令是否可见,是与以上的setecho代码结合起来的。
注意这个过程中会有命令不可见的情形,所以很容易运行出错,必须仔细。

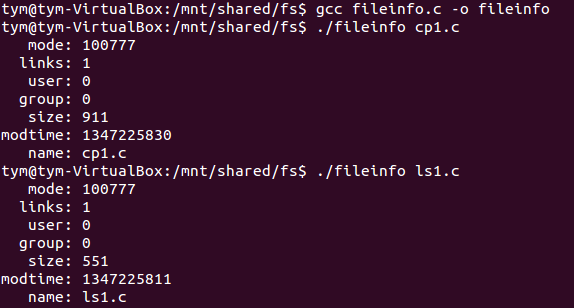
fileinfo & filesize
fileinfo:可显示文件信息。
filesize:可计算文件的字节数。
以上两个代码都是先判断是否有错误,有错就打印报错信息,没有就执行功能代码。

testioctl


 浙公网安备 33010602011771号
浙公网安备 33010602011771号