
信息安全系统设计基础第一周学习总结
1、Linux简介
学习过程:
这一节主要是文字性的描述,先介绍了Linux就是一个操作系统,包括系统调用和内核两层,再简介了Linux的发展由来, 商业化的UNIX,低廉的 MINIX( 功能有限的类似 UNIX 的操作系统),Linux 之父从 MINIX 开始入手,开发出Linux,然后逐步发展成现在的Linux。
Linux与Windows的不同:
Linux:免费,自由软件但质量欠缺,相对安全,命令行操作兼具图形界面操作,可定制性很好。
Windows:收费,收费软件但质量有保证,不太安全,纯图形界面下操作,可定制性很差。
Windows没有的:
- 稳定的系统
- 安全性和漏洞的快速修补
- 多用户
- 用户和用户组的规划
- 相对较少的系统资源占用
- 可定制裁剪,移植到嵌入式平台(如安卓设备)
- 可选择的多种图形用户界面(如 GNOME,KDE)
Linux没有的:
- 没有特定的支持厂商
- 游戏娱乐支持度不足
- 专业软件支持度不足
遇到的问题:
本节均为文字性描述,太过抽象,且多为专业性词语,并不能深刻理解,不免会让人觉得乏味,没兴趣。
希望今后会更通俗易懂,如:安全性
- Windows 平台:三天两头打补丁安装系统安全更新,还是会中病毒木马;
- Linux 平台:要说 Linux 没有安全问题,那当然是不可能的,这一点仁者见仁智者见智,相对来说肯定比 Windows 平台要更加安全,使用 Linux 你也不用装某杀毒,某毒霸。
2、基本概念及操作
Linux 的桌面环境:UNIX/Linux 本身是没有图形界面的, xorg(Linux 上的软件) 是 X(窗口系统) 架构规范的一个实现体,也就是说它是实现了 X 协议规范的一个提供图形用户界面服务的服务器,客户端,我们称为 X Client,实现了客户端功能的桌面环境KDE,GNOME,XFCE,LXDE。
终端模拟器的程序(Terminal):gnome-terminal,kconsole,xterm,rxvt,kvt,nxterm 和 eterm,目前我们的实验中的终端程序是 xfce 桌面环境自带的 xfce-terminal。
Linux 默认提供了 6 个纯命令行界面的 “terminal”来让用户登录,在物理机系统上你可以通过使用[Ctrl]+[Alt]+[F1]~[F6]进行切换,不过在我们的在线实验环境中可能无法切换,因为特殊功能按键会被你主机系统劫持。当你切换到其中一个终端后想要切换回图形界面,你可以按下[Ctrl]+[Alt]+[F7]来完成。
Shell(壳),有壳就有核,这里的核就是指的 UNIX/Linux 内核,Shell 是指“提供给使用者使用界面”的软件(命令解析器)。普通意义上的 Shell 就是可以接受用户输入命令的程序。
Unix/Linux 操作系统下的 Shell 既是用户交互的界面,也是控制系统的脚本语言。在Windows 操作系统下,可能有些用户从来都不会直接的使用 Shell,然而在 UNIX 系列操作系统下,Shell 仍然是控制系统启动、X11 启动和很多其他实用工具的脚本解释程序。
在 UNIX/Linux 中比较流行的常见的 Shell 有 bash,zsh,ksh,csh
命令行操作体验:
双击桌面上的Xface终端图标,打开终端,打开终端后会自动运行 Shell 程序,然后我们就可以输入命令让系统来执行了:
快捷键:
使用Tab键来进行命令补全,当你忘记某个命令的全称时你可以只输入它的开头的一部分然后按下Tab键就可以得到提示或者帮助完成。补全命令,补全目录,补全命令参数。
使用Ctrl+c键来强行终止当前程序(你可以放心它并不会使终端退出)。
其他一些常用快捷键
| 按键 | 作用 |
|---|---|
Ctrl+d |
键盘输入结束或退出终端 |
Ctrl+s |
暂定当前程序,暂停后按下任意键恢复运行 |
Ctrl+z |
将当前程序放到后台运行,恢复到前台为命令fg |
Ctrl+a |
将光标移至输入行头,相当于Home键 |
Ctrl+e |
将光标移至输入行末,相当于End键 |
Ctrl+k |
删除从光标所在位置到行末 |
Alt+Backspace |
向前删除一个单词 |
Shift+PgUp |
将终端显示向上滚动 |
Shift+PgDn |
将终端显示向下滚动 |
学会利用历史输入命令:很简单,你可以使用键盘上的方向上键,恢复你之前输入过的命令。
通配符是一种特殊语句,主要有星号(*)和问号(?),用来对对字符串进行模糊匹配(比如文件名,参数名)。当查找文件夹时,可以使用它来代替一个或多个真正字符。它只会出现在命令的“参数值”里(它不用在 命令名称里, 命令不记得,那就用Tab补全)。通配符 实际上就是一种 Shell 实现的路径扩展功能。在 通配符被处理后, Shell 会先完成该命令的重组,然后再继续处理重组后的命令,直至执行该命令。
示例:1、使用通配符寻找文件:先使用 touch 命令创建 2 个文件

2、一次性创建多个文件

Shell 常用通配符:
| 字符 | 含义 |
|---|---|
* |
匹配 0 或多个字符 |
? |
匹配任意一个字符 |
[list] |
匹配 list 中的任意单一字符 |
[!list] |
匹配 除list 中的任意单一字符以外的字符 |
[c1-c2] |
匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z] |
{string1,string2,...} |
匹配 sring1 或 string2 (或更多)其一字符串 |
{c2..c2} |
匹配 c1-c2 中全部字符 如{1..10} |
在 Linux 环境中,如果你遇到困难,可以使用man 命令,内容包括计算机程序(包括库和系统调用),正式的标准和惯例,甚至是抽象的概念。用户可以通过执行 man 命令调用手册页。
可以使用如下方式来获得某个命令的说明和使用方式的详细介绍:
$ man <command_name>
man 手册里面的内容都是英文的,做了分册(分区段)处理的,在Research UNIX、BSD、OS X 和 Linux 中,手册通常被分为8个区段,安排如下:
| 区段 | 说明 |
|---|---|
| 1 | 一般命令 |
| 2 | 系统调用 |
| 3 | 库函数,涵盖了C标准函数库 |
| 4 | 特殊文件(通常是/dev中的设备)和驱动程序 |
| 5 | 文件格式和约定 |
| 6 | 游戏和屏保 |
| 7 | 杂项 |
| 8 | 系统管理命令和守护进程 |
要查看相应区段的内容,就在 man 后面加上相应区段的数字即可,如:
$ man 3 printf手册页遵循一个常见的布局
一般包括以下部分内容:
NAME(名称)
SYNOPSIS(概要)
DESCRIPTION(说明)
EXAMPLES(示例)
SEE ALSO(参见)
通常 man 手册中的内容很多,可以在 man 中使用搜索,/<你要搜索的关键字>,查找到后你可以使用n键切换到下一个关键字所在处,shift+n为上一个关键字所在处。使用Space(空格键)翻页,Enter(回车键)向下滚动一行,或者使用j,k(vim编辑器的移动键)进行向前向后滚动一行。按下h键为显示使用帮助(因为man使用less作为阅读器,实为less工具的帮助),按下q退出。
想要获得更详细的帮助,你还可以使用info命令,不过通常使用man就足够了。如果你知道某个命令的作用,只是想快速查看一些它的某个具体参数的作用,那么你可以使用--help参数,大部分命令都会带有这个参数,如:
$ ls --help
作业:
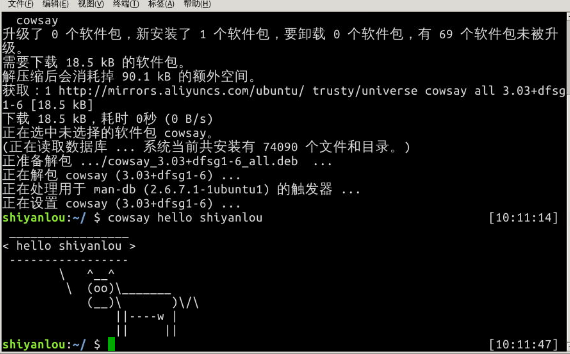
输出图形字符的命令banner
先使用如下命令安装:
$ sudo apt-get update;sudo apt-get install sysvbanner
![]()
然后:
$ banner shiyanlou
![]()
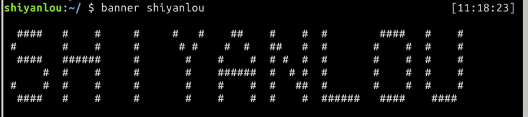
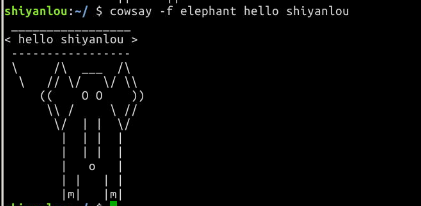
还可以使用默认已经安装的一个命令printerbanner:
$ printerbanner -w 50 A
![]()
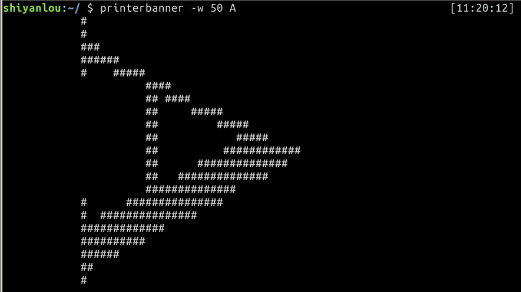
'-w'参数指定打印宽度,因为我们的环境在屏幕中显示比较小,必须要加上宽度限制。
还有两个类似的命令toilet,figlet
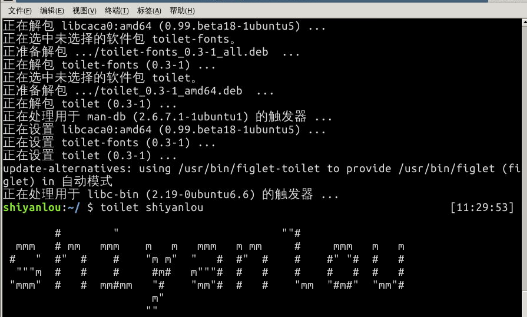

3、用户及文件权限管理
Linux 是一个可以实现多用户登陆的操作系统,由于 Linux 的 用户管理 和 权限机制 ,不同用户不可以轻易地查看、修改彼此的文件。
1、查看用户:
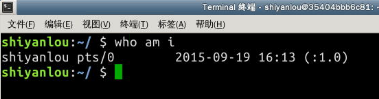
打开终端,输入命令:
$ who am i
或者
$ who mom likes
第一列表示打开当前伪终端的用户的用户名(要查看当前登录用户的用户名,去掉空格直接使用 whoami 即可)
第二列的 pts/0 中 pts 表示伪终端,0表示打开的伪终端序号,第三列则表示当前伪终端的启动时间。。
![]()
who 命令其它常用参数
| 参数 | 说明 |
|---|---|
-a |
打印能打印的全部 |
-d |
打印死掉的进程 |
-m |
同am i,mom likes |
-q |
打印当前登录用户数及用户名 |
-u |
打印当前登录用户登录信息 |
-r |
打印运行等级 |
2、创建用户
在 Linux 系统里, root 账户拥有整个系统至高无上的权利,比如 新建/添加 用户。创建用户需要 root 权限,这里就要用到 sudo 这个命令了。使用这个命令有两个大前提,一是你要知道当前登录用户的密码,二是当前用户必须在 sudo 用户组。
新建一个叫 lilei 的用户:
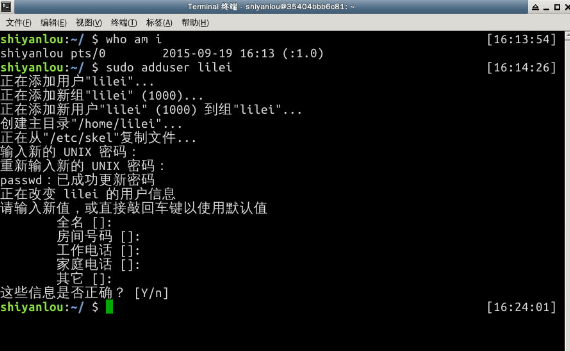
这个命令不但可以添加用户到系统,同时也会默认为新用户创建 home 目录:
$ ls /home
现在你已经创建好一个用户,并且你可以使用你创建的用户登录了,
使用如下命令切换登录用户:$ su -l lilei
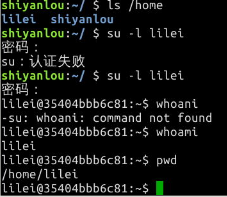
退出当前用户跟退出终端一样可以使用 exit 命令或者使用快捷键 Ctrl+d。
3、用户组
在 Linux 里面每个用户都有一个归属(用户组),用户组简单地理解就是一组用户的集合,它们共享一些资源和权限,同时拥有私有资源。
查看自己属于哪些用户组:
方法1、使用groups命令
$ groups shiyanlou

其中冒号之前表示用户,后面表示该用户所属的用户组。这里可以看到 shiyanlou 用户同时属于 shiyanlou 和 sudo 用户组,每次新建用户如果不指定用户组的话,默认会自动创建一个与用户名相同的用户组。默认情况下在sudo用户组里的可以使用sudo命令获得root权限。
方法2、查看/etc/group文件
$ cat /etc/group | sort
这里 cat 命令用于读取指定文件的内容并打印到终端输出,后面会详细讲它的使用。 | sort 表示将读取的文本进行一个字典排序再输出。
可以使用命令过滤掉一些你不想看到的结果:
$ cat /etc/group | grep -E "shiyanlou|sudo"etc/group 文件格式说明
/etc/group 的内容包括用户组(Group)、用户组口令、GID 及该用户组所包含的用户(User),每个用户组一条记录。格式如下:
group_name:password:GID:user_list
将其它用户加入 sudo 用户组
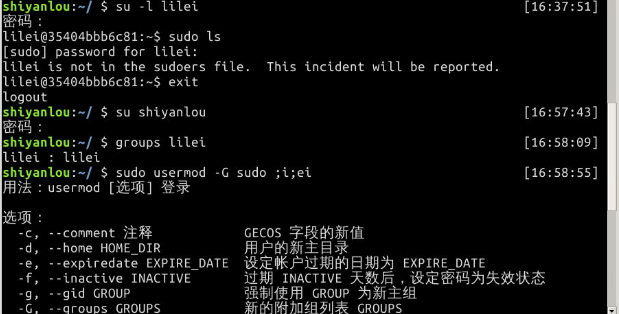
默认情况下新创建的用户是不具有 root 权限的,也不在 sudo 用户组,可以让其加入sudo用户组从而获取 root 权限。
$ su -l lilei
$ sudo ls
会提示 lilei 不在 sudoers 文件中,意思就是 lilei 不在 sudo 用户组中
使用 usermod 命令可以为用户添加用户组,同样使用该命令你必需有 root 权限,你可以直接使用 root 用户为其它用户添加用户组,或者用其它已经在 sudo 用户组的用户使用 sudo 命令获取权限来执行该命令
这里用 shiyanlou 用户执行 sudo 命令将 lilei 添加到 sudo 用户组,让它也可以使用 sudo 命令获得 root 权限
$ su shiyanlou
$ groups lilei
$ sudo usermod -G sudo lilei
$ groups lilei
然后你再切换会 lilei 用户,现在就可以使用 sudo 获取 root 权限了。
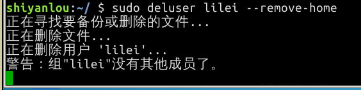
删除用户
查看文件权限
ls 命令,用它来列出并显示当前目录下的文件,当然这是在不带任何参数的情况下,它能做的当然不止这么多,现在我们就要用它来查看文件权限。
使用较长格式列出文件:
$ ls -l

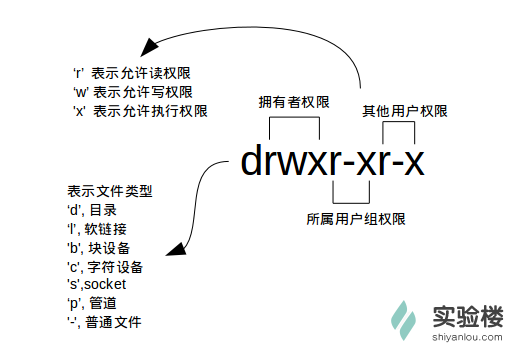
文件类型:设备文件( /dev 目录下有各种设备文件,大都跟具体的硬件设备相关)socket(网络套接字)pipe (管道)
链接文件是分为两种的,软链接文件,“硬链接”。
文件权限:
读权限,表示你可以使用 cat <file name> 之类的命令来读取某个文件的内容;写权限,表示你可以编辑和修改某个文件; 执行权限,通常指可以运行的二进制程序文件或者脚本文件。一个目录要同时具有读权限和执行权限才可以打开,而一个目录要有写权限才允许在其中创建其它文件。
至于所属用户组权限,是指你所在的用户组中的所有其它用户对于该文件的权限
链接数:
链接到该文件所在的 inode 结点的文件名数目。
文件大小:
以 inode 结点大小为单位来表示的文件大小,你可以给 ls 加上 -lh 参数来更直观的查看文件的大小。
关于 ls 命令的一些其它常用的用法:
- 显示除了 '.'(当前目录),'..' 上一级目录之外的所有包含隐藏文件(Linux 下以 '.' 开头的文件为隐藏文件)
$ ls -A
可以同时使用 '-A' 和 '-l' 参数:
$ ls -Al
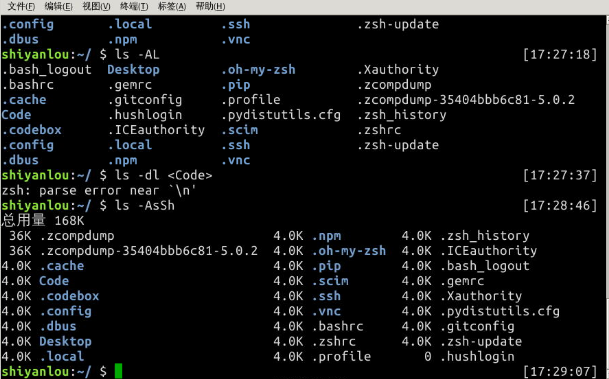
查看某一个目录的完整属性,而不是显示目录里面的文件属性:
$ ls -dl <目录名>
- 显示所有文件大小,并以普通人类能看懂的方式呈现:
$ ls -AsSh
其中小 s 为显示文件大小,大 S 为按文件大小排序,若需要知道如何按其它方式排序,请使用“man”命令查询。
变更文件所有者:
新建一个文件,命名为 “iphone6”,可见文件所有者是 lilei
使用以下命令变更文件所有者为 shiyanlou :
$ cd /home/lilei
$ ls iphone6
$ sudo chown shiyanlou iphone6
$ cp iphone6 /home/shiyanlou
现在查看,发现 文件所有者成功修改为 shiyanlou :

修改文件权限:
方式一:二进制数字表示
每个文件的三组权限(拥有者,所属用户组,其他用户,记住这个顺序是一定的)就对应这一个 "rwx",也就是一个 '7' ,所以如果我要将文件“iphone6”的权限改为只有我自己可以用那么就这样:
先在文件里加点内容:
$ echo "echo \"hello shiyanlou\"" > iphone6
然后修改权限:
$ chmod 600 iphone6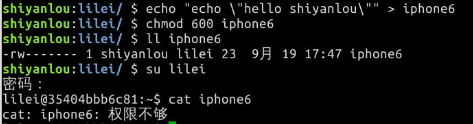
方式二:加减赋值操作
完成上述相同的效果,你可以:
$ chmod go-rw iphone6
'g''o'还有'u',分别表示group,others,user,'+','-' 就分别表示增加和去掉相应的权限。
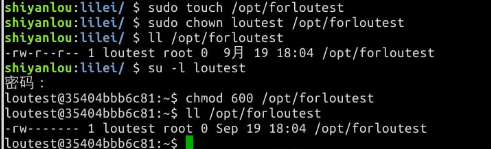
作业:添加一个用户loutest,使用sudo创建文件/opt/forloutest,设置成用户loutest可以读写。
首先,创建用户:sudo adduser loutest
然后创建文件:sudo touch /opt/forloutest
接着,将文件所有者改为用户loutest:sudo chown loutest /opt/forloutest
最后,修改文件权限,将权限修改为用户loutest可以读写:chmod 600 /opt/forloutest
4、Linux 目录结构及文件基本操作
Linux 的目录与 Windows 的目录的区别:一种不同是体现在目录与存储介质(磁盘,内存,DVD 等)的关系上,Windows 一直是以存储介质为主的,主要以盘符(C 盘,D 盘...)及分区的来实现文件管理,然后之下才是目录,目录就显得不是那么重要,使用一段时间后,磁盘上面的文件目录会显得杂乱无章。
UNIX 是以目录为主的,Linux 也继承了这一优良特性。 Linux 是以树形目录结构的形式来构建整个系统的,可以理解为一个用户可操作系统的骨架。虽然本质上无论是目录结构还是操作系统内核都是存储在磁盘上的,但从逻辑上来说 Linux 的磁盘是“挂在”(挂载在)目录上的,每一个目录不仅能使用本地磁盘分区的文件系统,也可以使用网络上的文件系统。
1、FHS 标准(英文:Filesystem Hierarchy Standard 中文:文件系统层次结构标准)
FHS 定义了系统中每个区域的用途、所需要的最小构成的文件和目录同时还给出了例外处理与矛盾处理。
FHS 定义了两层规范,第一层是, / 下面的各个目录应该要放什么文件数据,例如 /etc 应该要放置设置文件,/bin 与 /sbin 则应该要放置可执行文件等等。
第二层则是针对 /usr 及 /var 这两个目录的子目录来定义。例如 /var/log 放置系统登录文件、/usr/share 放置共享数据等等。

sudo apt-get update
sudo apt-get install tree
$ tree /
FHS 是根据以往无数 Linux 用户和开发者的经验总结出来的,并且会维持更新,FHS 依据文件系统使用的频繁与否以及是否允许用户随意改动(注意,不是不能,学习过程中,不要怕这些),将目录定义为四种交互作用的形态,如下表所示:

2.目录路径
路径
使用 cd 命令可以切换目录,在 Linux 里面使用 . 表示当前目录,.. 表示上一级目录, - 表示上一次所在目录,~ 通常表示当前用户的"home"目录。使用 pwd 命令可以获取当前所在路径(绝对路径)。
(注意,还记得我们上一节介绍过的,以 . 开头的文件都是隐藏文件,所以这两个目录必然也是隐藏的,你可以使用 ls -a 命令查看隐藏文件)
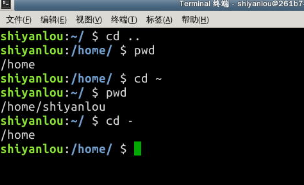
绝对路径
以根"/"目录为起点的完整路径,以你所要到的目录为终点,表现形式如: /usr/local/bin表示根目录下的 usr 目录中的 local 目录中的 bin 目录。
相对路径
相对路径,也就是相对于你当前的目录的路径,相对路径是以当前目录 . 为起点,以你所要到的目录为终点,表现形式如: usr/local/bin (这里假设你当前目录为根目录)。
下面我们以你的"home"目录为起点,分别以绝对路径和相对路径的方式进入/usr/local/bin 目录:
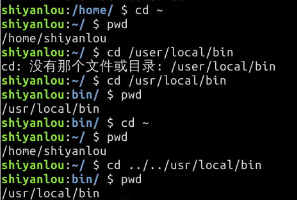
提示:在进行目录切换的过程中请多使用 Tab 键自动补全,可避免输入错误,连续按两次Tab可以显示全部候选结果
二、Linux 文件的基本操作
1.新建
新建空白文件
使用 touch 命令创建空白文件,关于 touch 命令,其主要是来更改已有文件的时间戳的,但其在不加任何参数的情况下,只指定一个文件名,则可以创建一个为指定文件名的空白文件。
创建名为 test 的空白文件,因为在其他目录没有权限,所以需要先 cd ~ 切换回用户的/home/shiyanlou 目录:
$ cd ~
$ touch test
新建目录
使用 mkdir(make directories)命令可以创建一个空目录,也可同时指定创建目录的权限属性。
创建名为"mydir"的空目录:mkdir mydir
使用 -p 参数,同时创建父目录(如果不存在该父目录),如下我们同时创建一个多级目录(这在有时候安装软件,配置安装路径时非常有用):
mkdir -p father/son/grandson
2.复制
复制文件
使用cp(copy)命令复制一个文件或目录到指定目录。将之前创建的"test"文件复制到"/home/shiyanlou/father/son/grandson"目录中:
cp test father/son/grandson
复制目录
如果直接使用cp命令,复制一个目录的话,会出现如下错误:

要成功复制目录需要加上-r或者-R参数,表示递归复制。
cp -r father family
3.删除
删除文件
使用rm(remove files or directories)命令,删除一个文件或目录;
例如:rm test
有时候你会遇到想要删除一些为只读权限的文件,直接使用rm删除会显示一个提示,

就需要用上参数 -f ,可强制删除
例如:rm -f test
删除目录
跟复制目录一样,要删除一个目录,也需要加上-r或-R参
例子:rm -r family
4.移动文件与文件重命名
使用mv(move or rename files)命令,移动文件(剪切)。
格式:mv 源目录文件 目的目录
例子:将文件"file1"移动到"Documents"目录:mv file1 Documents
重命名文件
格式:mv 旧的文件名 新的文件名
例子:mv file1 myfile
rename命令可以批量重命名
# 使用通配符批量创建 5 个文件
$ touch file{1..5}.txt
# 批量将这 5 个后缀为 .txt 的文本文件重命名为以 .c 为后缀的文件
$ rename 's/\.txt/\.c/' *.txt
# 批量将这 5 个文件,文件名改为大写
$ rename 'y/a-z/A-Z/' *.c
5.查看文件
标准输入输出:当我们执行一个 shell 命令行时通常会自动打开三个标准文件,即标准输入文件(stdin),默认对应终端的键盘; 标准输出文件(stdout)和标准错误输出文件(stderr),这两个文件都对应被重定向到终端的屏幕,以便我们能直接看到输出内容。进程将从标准输入文件中得到输入数据,将正常输出数据输出到标准输出文件,而将错误信息送到标准错误文件中。
使用cat,tac和nl命令查看文件
这两个命令都是用来打印文件内容到标准输出(终端),其中cat为正序显示,tac倒序显示。
比如我们要查看之前从"/etc"目录下拷贝来的passwd文件:
$ cat passwd
可以加上-n参数显示行号:
$ cat -n passwd
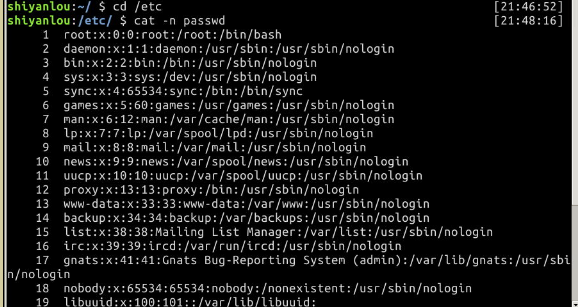
nl命令,添加行号并打印,这是个比cat -n更专业的行号打印命令。
这里简单列举它的常用的几个参数:
-b : 指定添加行号的方式,主要有两种:
-b a:表示无论是否为空行,同样列出行号("cat -n"就是这种方式)
-b t:只列出非空行的编号并列出(默认为这种方式)
-n : 设置行号的样式,主要有三种:
-n ln:在行号字段最左端显示
-n rn:在行号字段最右边显示,且不加 0
-n rz:在行号字段最右边显示,且加 0
-w : 行号字段占用的位数(默认为 6 位)
使用more和less命令分页查看文件
其中more命令比较简单,只能向一个方向滚动,而"less"为基于"more"和"vi"(一个强大的编辑器,我们有单独的课程来让你学习)开发,功能更强大。
使用more工具打开passwd文件:
$ more passwd打开后默认只显示一屏内容,终端底部显示当前阅读的进度(百分比)。可以使用Enter键向下滚动一行,使用Space键向下滚动一屏,按下h显示帮助,q退出。
使用head和tail命令查看文件
只查看的头几行(默认为10行,不足10行则显示全部)和尾几行。
甚至更直接的只看一行, 加上-n参数,后面紧跟行数:
$ tail -n 1 /etc/passwd
关于tail命令,不得不提的还有它一个很牛的参数-f,这个参数可以实现不停地读取某个文件的内容并显示。
6.查看文件类型
在 Linux 下面文件的类型不是根据文件后缀来判断的,我们通常使用file命令可以查看文件的类型:
$ file /bin/ls

这表示这是一个可执行文件,运行在 64 位平台,并使用了动态链接文件(共享库)。
7.编辑文件
在 Linux 下面编辑文件通常我们会直接使用专门的命令行编辑器比如(emacs,vim,nano)
作业:

5、环境变量与文件查找
所谓变量就是计算机中用于记录一个值(不一定是数值,也可以是字符或字符串)的符号。
变量的作用域即变量的有效范围(比如一个函数中、一个源文件中或者全局范围),在该范围内只能有一个同名变量。一旦离开则该变量无效,如同不存在这个变量一般。
1、变量
使用declare命令创建一个变量名为 tmp 的变量:
$ declare tmp使用=号赋值运算符为变量 tmp 赋值为 shiyanlou:
$ tmp=shiyanlou读取变量的值,使用echo命令和$符号($符号用于表示引用一个变量的值,初学者经常会忘记输入):
$ echo $tmp
关于变量名,并不是任何形式的变量名都是可用的,变量名只能是英文字母,数字或者下划线,且不能以数字作为开头。
2、环境变量
环境变量就是作用域比自定义变量要大,如Shell 的环境变量作用于自身和它的子进程。在所有的 UNIX 和类 UNIX 系统中,每个进程都有其各自的环境变量设置,且默认情况下,当一个进程被创建时,处理创建过程中明确指定的话,它将继承其父进程的绝大部分环境设置。Shell 程序也作为一个进程运行在操作系统之上,而我们在 Shell中运行的大部分命令都将以 Shell 的子进程的方式运行。
通常我们会涉及到的环境变量有三种:
- 当前 Shell 进程私有用户自定义变量,如上面我们创建的 temp 变量,只在当前 Shell 中有效。
- Shell 本身内建的变量。
- 从自定义变量导出的环境变量。
也有三个与上述三种环境变量相关的命令,set,env,export。这三个命令很相似,都可以用于打印相关环境变量,区别在于涉及的是不同范围的环境变量,详见下表:
|
命令 |
说明 |
|---|---|
|
|
显示当前 Shell 所有环境变量,包括其内建环境变量(与 Shell 外观等相关),用户自定义变量及导出的环境变量 |
|
|
显示与当前用户相关的环境变量,还可以让命令在指定环境中运行 |
|
|
显示从 Shell 中导出成环境变量的变量,也能通过它将自定义变量导出为环境变量 |
关于环境变量,可以简单的理解成在当前进程的子进程是否有效,有效则为环境变量,否则不是(有些人也将所有变量统称为环境变量,只是以全局环境变量和局部环境变量进行区分,我们只要理解它们的实质区别即可)。
为了与普通变量区分,通常我们习惯将环境变量名设为大写
3.命令的查找路径与顺序
我们在 Shell 中输入一个命令,Shell 是怎么知道在哪去找到这个命令然后执行的呢?这是通过环境变量PATH来进行搜索的
查看PATH环境变量的内容:
$ echo $PATH
默认情况下你会看到如下输出:
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
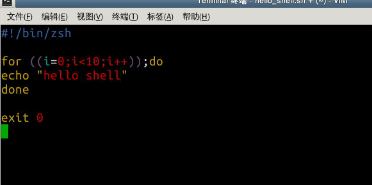
创建一个 Shell 脚本文件:
$ vim hello_shell.sh
在脚本中添加如下内容,保存并退出(注意不要省掉第一行,这不是注释,论坛有用户反应会有语法错误,就是因为没有了第一行):
#!/bin/zsh
for ((i=0; i<10; i++));do
echo "hello shell"
done
exit 0
![]()
为文件添加可执行权限:
$ chmod 755 hello_shell.sh
执行脚本
$ ./hello_shell.sh
创建一个 C 语言"hello world"程序:
$ vim hello_world.c
#include <stdio.h>
int main(void)
{
printf("hello world!\n");
return 0;
}
使用 gcc 生成可执行文件:
$ gcc -o hello_world hello_world.c
gcc 生成二进制文件默认具有可执行权限,不需要修改
在 shiyanlou 家目录创建一个mybin目录,并将上述 hello_shell.sh 和 hello_world 文件移动到其中:
$ mkdir mybin
$ mv hello_shell.sh hello_world mybin/
现在你可以在mybin目录中分别运行你刚刚创建的两个程序:
$ cd mybin
$ ./hello_shell.sh
$ ./hello_world![]()

4.添加自定义路径到“PATH”环境变量
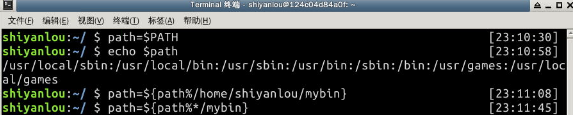
PATH里面的路径是以:作为分割符,所以我们可以这样添加自定义路径:
$ PATH=$PATH:/home/shiyanlou/mybin
注意这里一定要使用绝对路径
给 PATH 环境变量追加了一个路径,它也只是在当前 Shell 有效,我一旦退出终端,再打开就会发现又失效了。
让它自动执行:在每个用户的 home 目录中有一个 Shell 每次启动时会默认执行一个配置脚本,以初始化环境,包括添加一些用户自定义环境变量等等。zsh 的配置文件是.zshrc,相应 Bash 的配置文件为.bashrc。它们在etc下还都有一个或多个全局的配置文件,不过我们一般只修改用户目录下的配置文件。
我们可以简单的使用下面命令直接添加内容到.zshrc中:
$ echo "PATH=$PATH:/home/shiyanlou/mybin" >> .zshrc
上述命令中>>表示将标准输出以追加的方式重定向到一个文件中,注意前面用到的>是以覆盖的方式重定向到一个文件中,使用的时候一定要注意分辨。在指定文件不存在的情况下都会创建新的文件。
5.修改和删除已有变量
变量修改
变量的修改有以下几种方式:
| 变量设置方式 | 说明 |
|---|---|
${变量名#匹配字串} |
从头向后开始匹配,删除符合匹配字串的最短数据 |
${变量名##匹配字串} |
从头向后开始匹配,删除符合匹配字串的最长数据 |
${变量名%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最短数据 |
${变量名%%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最长数据 |
${变量名/旧的字串/新的字串} |
将符合旧字串的第一个字串替换为新的字串 |
${变量名//旧的字串/新的字串} |
将符合旧字串的全部字串替换为新的字串 |
变量删除
可以使用unset命令删除一个环境变量:
$ unset temp6.如何让环境变量立即生效
在上面我们在 Shell 中修改了一个配置脚本文件之后,每次都要退出终端重新打开甚至重启主机之后其才能生效,我们可以使用source命令来让其立即生效,如:
$ source .zshrc
source命令还有一个别名就是.,注意与表示当前路径的那个点区分开,虽然形式一样,但作用和使用方式一样,上面的命令如果替换成.的方式就该是
$ . ./.zshrc
注意第一个点后面有一个空格,而且后面的文件必须指定完整的绝对或相对路径名,source 则不需要。
二、搜索文件
与搜索相关的命令常用的有如下几个whereis,which,find,locate。
whereis简单快速
$whereis who

locate快而全
$ locate /etc/sh
注意,它不只是在 etc 目录下查找并会自动递归子目录进行查找
查找 /usr/share/ 下所有 jpg 文件:
$ locate /usr/share/\*.jpg
注意要添加*号前面的反斜杠转义,否则会无法找到
如果想只统计数目可以加上-c参数,-i参数可以忽略大小写进行查找,whereis 的-b,-m,-s同样可以是使用。
which小而精
which本身是 Shell 内建的一个命令,我们通常使用which来确定是否安装了某个指定的软件,因为它只从PATH环境变量指定的路径中去搜索命令:
$ which man
find精而细
find应该是这几个命令中最强大的了,它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性(如文件的时间戳,文件的权限等)进行搜索。find命令强大到,要把它将明白至少需要单独好几节课程才行,我们这里只介绍一些常用的内容。
在指定目录下搜索指定文件名的文件:
$ find /etc/ -name interfaces
注意 find 命令的路径是作为第一个参数的, 基本命令格式为 find [path] [option] [action]与时间相关的命令参数:
| 参数 | 说明 |
|---|---|
-atime |
最后访问时间 |
-ctime |
创建时间 |
-mtime |
最后修改时间 |
下面以-mtime参数举例:
-mtime n: n 为数字,表示为在n天之前的”一天之内“修改过的文件-mtime +n: 列出在n天之前(不包含n天本身)被修改过的文件-mtime -n: 列出在n天之前(包含n天本身)被修改过的文件newer file: file为一个已存在的文件,列出比file还要新的文件名

列出 home 目录中,当天(24 小时之内)有改动的文件:
$ find ~ -mtime 0
![]()
列出用户家目录下比Code文件夹新的文件:
$ find ~ -newer /home/shiyanlou/Code
作业:
数字雨
![]()
![]()
6、文件打包与解压缩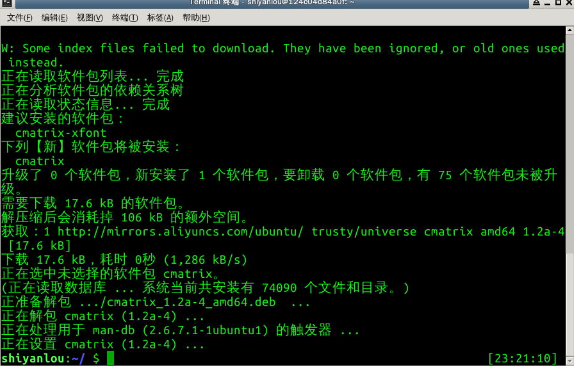
常见常用的压缩包文件格式。在 Windows 上我们最常见的不外乎这三种*.zip,*.rar,*.7z后缀的压缩文件,而在 Linux 上面常见常用的除了以上这三种外,还有*.gz,*.xz,*.bz2,*.tar,*.tar.gz,*.tar.xz,*tar.bz2,简单介绍如下:
| 文件后缀名 | 说明 |
|---|---|
*.zip |
zip程序打包压缩的文件 |
*.rar |
rar程序压缩的文件 |
*.7z |
7zip程序压缩的文件 |
*.tar |
tar程序打包,未压缩的文件 |
*.gz |
gzip程序(GNU zip)压缩的文件 |
*.xz |
xz程序压缩的文件 |
*.bz2 |
bzip2程序压缩的文件 |
*.tar.gz |
tar打包,gzip程序压缩的文件 |
*.tar.xz |
tar打包,xz程序压缩的文件 |
*tar.bz2 |
tar打包,bzip2程序压缩的文件 |
*.tar.7z |
tar打包,7z程序压缩的文件 |
zip压缩打包程序
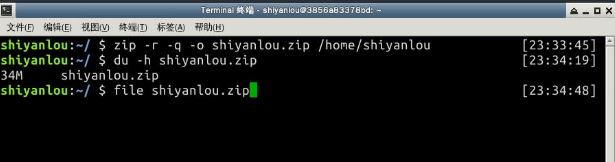
使用zip打包文件夹:
$ zip -r -q -o shiyanlou.zip /home/shiyanlou
$ du -h shiyanlou.zip
$ file shiyanlou.zip
-
上面命令将 shiyanlou 的 home 目录打包成一个文件,并查看了打包后文件的大小和类型。第一行命令中,
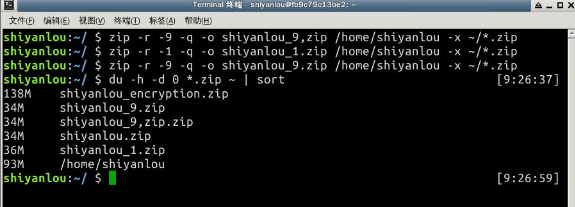
-r参数表示递归打包包含子目录的全部内容,-q参数表示为安静模式,即不向屏幕输出信息,-o,表示输出文件,需在其后紧跟打包输出文件名。后面使用du命令查看打包后文件的大小(后面会具体说明该命令)。- 设置压缩级别为9和1(9最大,1最小),重新打包:
$ zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou -x ~/*.zip $ zip -r -1 -q -o shiyanlou_1.zip /home/shiyanlou -x ~/*.zip这里添加了一个参数用于设置压缩级别
-[1-9],1表示最快压缩但体积大,9表示体积最小但耗时最久。最后那个-x是为了排除我们上一次创建的 zip 文件,否则又会被打包进这一次的压缩文件中,注意:这里只能使用绝对路径,否则不起作用。我们再用
du命令分别查看默认压缩级别、最低、最高压缩级别及未压缩的文件的大小:$ du -h -d 0 *.zip ~ | sort -
![]()
通过man 手册可知:
-
h, --human-readable(顾名思义,你可以试试不加的情况)
-
d, --max-depth(所查看文件的深度)
默认压缩级别应该是最高的,效果很明显,不过你在环境中操作之后看到的大小可能跟图上的有些不同,因为在你使用过程中,会随时还生成一些缓存文件在当前用户的家目录中。
- 创建加密zip包
使用
-e参数可以创建加密压缩包:$ zip -r -e -o shiyanlou_encryption.zip /home/shiyanlou -
-
![]()
注意: 关于
zip命令,因为 Windows 系统与 Linux/Unix 在文本文件格式上的一些兼容问题,比如换行符(为不可见字符),在 Windows 为 CR+LF(Carriage-Return+Line-Feed:回车加换行),而在 Linux/Unix 上为 LF(换行),所以如果在不加处理的情况下,在 Linux 上编辑的文本,在 Windows 系统上打开可能看起来是没有换行的。如果你想让你在 Linux 创建的 zip 压缩文件在 Windows 上解压后没有任何问题,那么你还需要对命令做一些修改:$ zip -r -l -o shiyanlou.zip /home/shiyanlou需要加上
-l参数将LF转换为CR+LF来达到以上目的。 -
解压zip包
- 使用unzip命令:unzip XX.zip
- 将文件解压到指定目录: unzip -q xx.zip
-d 目录名 - 不解压仅仅查看: unzip -l xx.zip
- windows中文采用GBK编码,LINUX相爱用UTF-8,解决解压的兼容问题,解压是指定采用编码类型:
unzip -O GBK 中文压缩文件.zip ![]()
-
rar打包压缩命令
- rar压缩命令: rar命令没有参数-
参数a:rar a xx.rar 添加一个目录~到xx.rar
参数d:rar d xx.rar 文件名 从xx.rar删除文件
l:rar l xx.rar 查看不解压 - unrar解压命令 x:unrar x xx.rar 全路径解压
e:unrar e xx.rar 目录 解压到指定目录tar打包工具
-c:创建一个tar包文件
-f:指定创建的文件名
-v:非安静模式
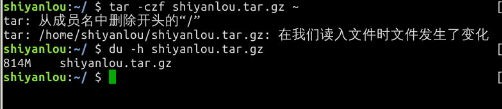
tar -cf shiyanlou.tar ~
-x:解压一个tar
-C:解压到指定路径的已存在目录
tar -xf xx.tar -C 目录
-t:只查看不解包
tar -tf xx.rar
-p:保存文件属性
-h保存设备连接指向的源文件
tar -cphf xx.tar 要压缩目录
-z:.tar.gz
-J:tar.xz
-j:tar.bz2
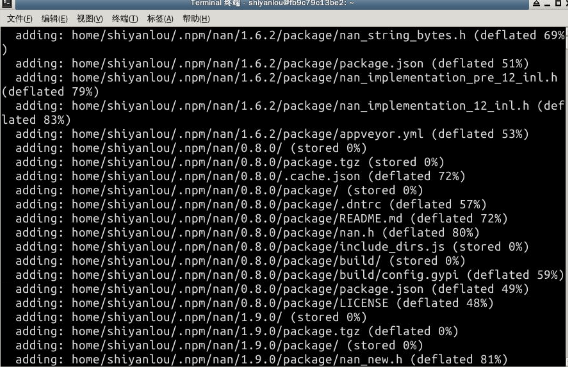
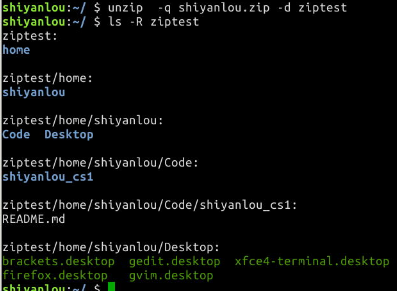

- 作业:
7、文件系统操作与磁盘管理
一、简单文件系统操作
1.查看磁盘和目录的容量
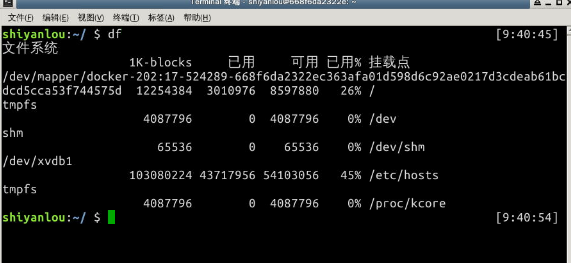
使用 df 命令查看磁盘的容量
$ df
在实验楼的环境中你将看到如下的输出内容:
但在实际的物理主机上会更像这样:
![]()
一般使用情况下,我们更多只是关心第一行的内容也就是环境中的rootfs或者物理主机上的/dev/sda2
物理主机上的 /dev/sda2 是对应着主机硬盘的分区,后面的数字表示分区号,数字前面的字母 a 表示第几块硬盘(也可能是可移动磁盘),你如果主机上有多块硬盘则可能还会出现 /dev/sdb,/dev/sdc 这些磁盘设备都会在 /dev 目录下以文件的存在形式。
接着你还会看到"1k-blocks"这个陌生的东西,它表示以磁盘块大小的方式显示容量,后面为相应的以块大小表示的已用和可用容量,在你了解 Linux 的文件系统之前这个就先不管吧,我们以一种你应该看得懂的方式展示:
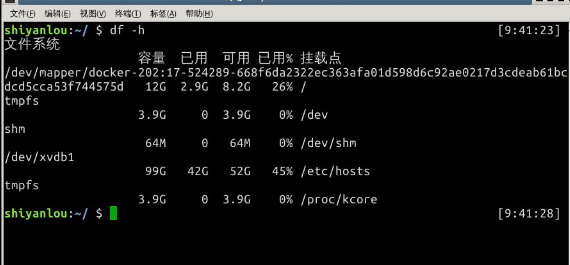
$ df -h
使用 du 命令查看目录的容量
# 默认同样以 blocks 的大小展示
$ du
# 加上`-h`参数,以更易读的方式展示
$ du -h
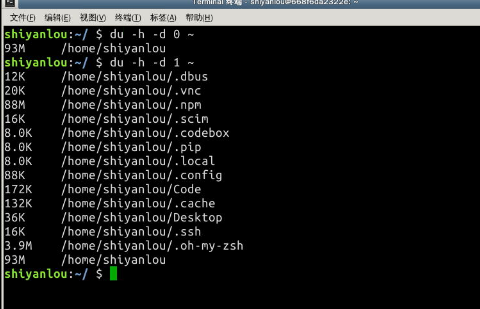
-d参数指定查看目录的深度
# 只查看1级目录的信息
$ du -h -d 0 ~
# 查看2级
$ du -h -d 1 ~
du(estimate file space usage)命令与df(report file system disk space usage)只用一字只差,首先就希望注意不要弄混淆了,以可以像我这样从man手册中获取命令的完整描述,记全称就不会搞混了。
二、简单的磁盘管理
1.创建虚拟磁盘
dd 命令简介
dd命令用于转换和复制文件,不过它的复制不同于cp。之前提到过关于 Linux 的很重要的一点,一切即文件,在 Linux 上,硬件的设备驱动(如硬盘)和特殊设备文件(如/dev/zero和/dev/random)都像普通文件一样,只要在各自的驱动程序中实现了对应的功能,dd 也可以读取自和/或写入到这些文件。这样,dd也可以用在备份硬件的引导扇区、获取一定数量的随机数据或者空数据等任务中。dd程序也可以在复制时处理数据,例如转换字节序、或在 ASCII 与 EBCDIC 编码间互换。
dd的命令行语句与其他的 Linux 程序不同,因为它的命令行选项格式为选项=值,而不是更标准的--选项 值或-选项=值。dd默认从标准输入中读取,并写入到标准输出中,但可以用选项if(input file,输入文件)和of(output file,输出文件)改变。
用dd命令从标准输入读入用户输入到标准输出或者一个文件:
# 输出到文件
$ dd of=test bs=10 count=1 # 或者 dd if=/dev/stdin of=test bs=10 count=1
# 输出到标准输出
$ dd if=/dev/stdin of=/dev/stdout bs=10 count=1
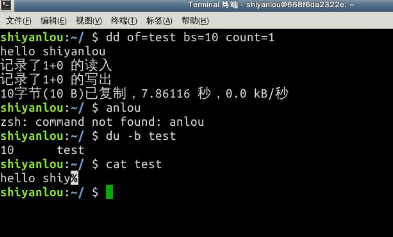
上述命令从标准输入设备读入用户输入(缺省值,所以可省略)然后输出到 test 文件,bs(block size)用于指定块大小(缺省单位为 Byte,也可为其指定如'K','M','G'等单位),count用于指定块数量。如上图所示,我指定只读取总共 10 个字节的数据,当我输入了“hello shiyanlou”之后加上空格回车总共 16 个字节(一个英文字符占一个字节)内容,显然超过了设定大小。使用和du和cat命令看到的写入完成文件实际内容确实只有 10 个字节(那个黑底百分号表示这里没有换行符),而其他的多余输入将被截取并保留在标准输入。
前面说到dd在拷贝的同时还可以实现数据转换,那下面就举一个简单的例子:将输出的英文字符转换为大写再写入文件:
$ dd if=/dev/stdin of=test bs=10 count=1 conv=ucase
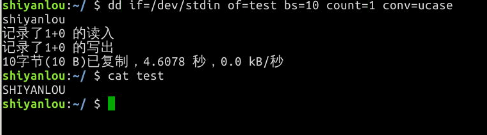
使用 dd 命令创建虚拟镜像文件
从/dev/zero设备创建一个容量为 256M 的空文件:
$ dd if=/dev/zero of=virtual.img bs=1M count=256
$ du -h virtual.img
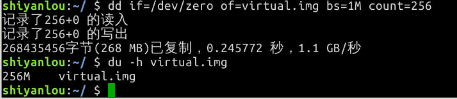
将这个文件格式化(写入文件系统):
使用 mkfs 命令格式化磁盘(我们这里是自己创建的虚拟磁盘镜像)
你可以在命令行输入 mkfs 然后按下Tab键,你可以看到很多个以 mkfs 为前缀的命令,这些不同的后缀其实就是表示着不同的文件系统,可以用 mkfs 格式化成的文件系统:
可以简单的使用下面的命令来将我们的虚拟磁盘镜像格式化为ext4文件系统:
$ mkfs.ext4 virtual.img
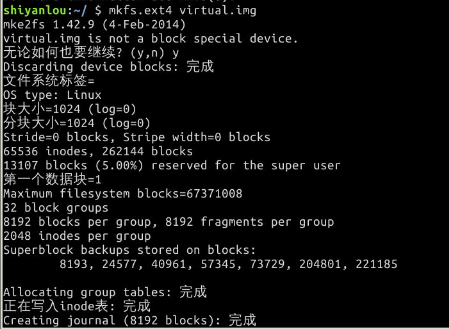
可以看到实际 mkfs.ext4 是使用 mke2fs 来完成格式化工作的。mke2fs 的参数很多,不过我们也不会经常格式化磁盘来玩,所以就掌握这基本用法
使用 mount 命令挂载磁盘到目录树
用户在 Linux/UNIX 的机器上打开一个文件以前,包含该文件的文件系统必须先进行挂载的动作,此时用户要对该文件系统执行 mount 的指令以进行挂载。
Linux/UNIX 命令行的 mount 指令是告诉操作系统,对应的文件系统已经准备好,可以使用了,而该文件系统会对应到一个特定的点(称为挂载点)。
使用mount来查看下主机已经挂载的文件系统:
$ sudo mount
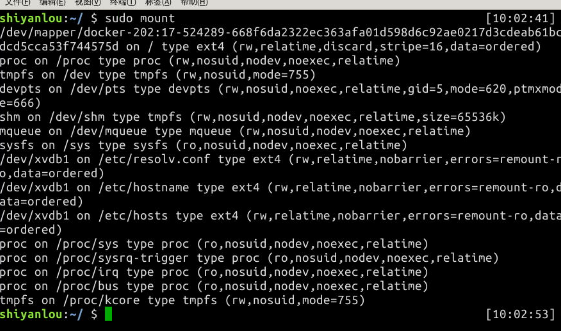
输出的结果中每一行表示一个设备或虚拟设备,每一行最前面是设备名,然后是 on 后面是挂载点,type 后面表示文件系统类型,再后面是挂载选项
mount命令的一般格式如下:mount [options] [source] [directory]
一些常用操作:
mount [-o [操作选项]] [-t 文件系统类型] [-w|--rw|--ro] [文件系统源] [挂载点]
直接来挂载我们创建的虚拟磁盘镜像到/mnt目录:
$ mount -o loop -t ext4 virtual.img /mnt
# 也可以省略挂载类型,很多时候 mount 会自动识别
# 以只读方式挂载
$ mount -o loop --ro virtual.img /mnt
# 或者mount -o loop,ro virtual.img /mnt
使用 umount 命令卸载已挂载磁盘
# 命令格式 sudo umount 已挂载设备名或者挂载点,如:
$ sudo umount /mnt
由于我们环境的问题(环境中使用的 Linux 内核在编译时没有添加对 Loop device的支持),所以你将无法挂载成功:

在类 UNIX 系统中,/dev/loop(或称vnd (vnode disk)、lofi(循环文件接口))是一种伪设备,这种设备使得文件可以如同块设备一般被访问。
在使用之前,循环设备必须与现存文件系统上的文件相关联。这种关联将提供给用户一个应用程序接口,接口将允许文件视为块特殊文件(参见设备文件系统)使用。因此,如果文件中包含一个完整的文件系统,那么这个文件就能如同磁盘设备一般被挂载。
这种设备文件经常被用于光盘或是磁盘镜像。通过循环挂载来挂载包含文件系统的文件,便使处在这个文件系统中的文件得以被访问。这些文件将出现在挂载点目录。如果挂载目录中本身有文件,这些文件在挂载后将被禁止使用。
使用 fdisk 为磁盘分区
同样因为环境原因中没有物理磁盘,也无法创建虚拟磁盘的原因我们就无法实验练习使用该命令了,下面将以物理主机为例讲解如何为磁盘分区。
# 查看硬盘分区表信息
$ sudo fdisk -l
![]()
输出结果中开头显示了我主机上的磁盘的一些信息,包括容量扇区数,扇区大小,I/O 大小等信息。
我们重点开一下中间的分区信息,/dev/sda1,/dev/sda2 为主分区分别安装了 Windows 和 Linux 操作系统,/dev/sda3 为交换分区(可以理解为虚拟内存),/dev/sda4 为扩展分区其中包含 /dev/sda5,/dev/sda6,/dev/sda7,/dev/sda8 四个逻辑分区,因为主机上有几个分区之间有空隙,没有对齐边界扇区,所以分区之间的不是完全连续的。
# 进入磁盘分区模式
$ sudo fdisk virtual.img
![]()
在进行操作前我们首先应先规划好我们的分区方案,这里我将在使用 128M(可用 127M 左右)的虚拟磁盘镜像创建一个 30M 的主分区剩余部分为扩展分区包含 2 个大约 45M 的逻辑分区。
操作完成后输入p查看结果如下:

最后不要忘记输入w写入分区表。
使用 losetup 命令建立镜像与回环设备的关联
$ sudo losetup /dev/loop0 virtual.img
# 如果提示设备忙你也可以使用其它的回环设备,"ls /dev/loop*"参看所有回环设备
# 解除设备关联
$ sudo losetup -d /dev/loop0
然后再使用mkfs格式化各分区(前面我们是格式化整个虚拟磁盘镜像文件或磁盘),不过格式化之前,我们还要为各分区建立虚拟设备的映射,用到kpartx工具,需要先安装:
$ sudo apt-get install kpartx
$ sudo kpart kpartx -av /dev/loop0
# 取消映射
$ sudo kpart kpartx -dv /dev/loop0
接着再是格式化,我们将其全部格式化为 ext4:
$ sudo mkfs.ext4 -q /dev/mapper/loop0p1
$ sudo mkfs.ext4 -q /dev/mapper/loop0p5
$ sudo mkfs.ext4 -q /dev/mapper/loop0p6
格式化完成后在/media目录下新建四个空目录用于挂载虚拟磁盘:
$ mkdir -p /media/virtualdisk_{1..3}
# 挂载磁盘分区
$ sudo mount /dev/mapper/loop0p1 /media/virtualdisk_1
$ sudo mount /dev/mapper/loop0p5 /media/virtualdisk_2
$ sudo mount /dev/mapper/loop0p6 /media/virtualdisk_3
# 卸载磁盘分区
$ sudo umount /dev/mapper/loop0p1
$ sudo umount /dev/mapper/loop0p5
$ sudo umount /dev/mapper/loop0p6
然后:$ df -h
作业:
8、命令执行顺序控制与管道
一、命令执行顺序的控制
1.顺序执行多条命令
通常情况下,每次只能在终端输入一条命令,按下回车执行,执行完成后,再输入第二条命令,然后再按回车执行……
想要一次性输入完,让它自己去一次执行各命令
简单的顺序执行你可以使用;来完成,比如上述操作你可以:
$ sudo apt-get update;sudo apt-get install some-tool;some-tool
# 让它自己运行2.有选择的执行命令
关于上面的操作,前面的命令执行不成功,而后面的命令又依赖与上一条命令的结果,那么就会造成花了时间,最终却得到一个错误的结果,而且有时候直观的看你还无法判断结果是否正确。那么我们需要能够有选择性的来执行命令,比如上一条命令执行成功才继续下一条,或者不成功又该做出其它什么处理,比如我们使用which来查找是否安装某个命令,如果找到就执行该命令,否则什么也不做
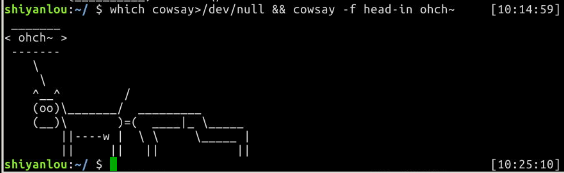
$ which cowsay>/dev/null && cowsay -f head-in ohch~
你如果没有安装cowsay,你可以先执行一次上述命令,你会发现什么也没发生,你再安装好之后你再执行一次上述命令,你也会发现一些惊喜。
上面的&&就是用来实现选择性执行的,它表示如果前面的命令执行结果(不是表示终端输出的内容,而是表示命令执行状态的结果)返回0则执行后面的,否则不执行
同样 Shell 也有一个||,它们的区别就在于,shell中的这两个符号除了也可用于表示逻辑与和或之外,就是可以实现这里的命令执行顺序的简单控制。||在这里就是与&&相反的控制效果,当上一条命令执行结果为≠0($?≠0)时则执行它后面的命令:
$ which cowsay>/dev/null || echo "cowsay has not been install, please run 'sudo apt-get install cowsay' to install"
除了上述基本的使用之外,我们还可以结合这&&和||来实现一些操作,比如:
$ which cowsay>/dev/null && echo "exist" || echo "not exist"我画个流程图来解释一下上面的流程:

二、管道
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
管道又分为匿名管道和具名管道。我们在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由|分隔符表示,具名管道简单的说就是有名字的管道,通常只会在源程序中用到具名管道。
1.试用
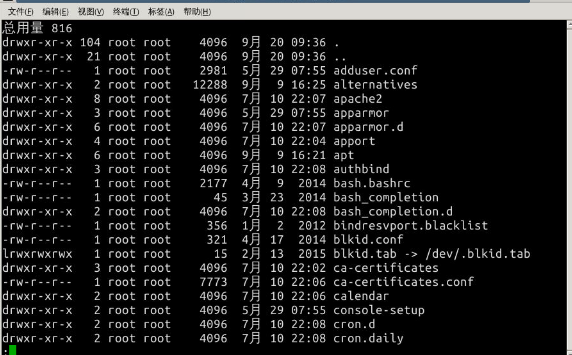
查看/etc目录下有哪些文件和目录,使用ls命令来查看:$ ls -al /etc
有太多内容,屏幕不能完全显示,这时候可以使用滚动条或快捷键滚动窗口来查看。不过这时候可以使用管道:$ ls -al /etc | less
通过管道将前一个命令(ls)的输出作为下一个命令(less)的输入,然后就可以一行一行地看。
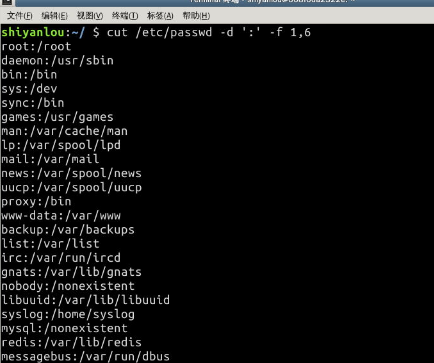
2.cut 命令,打印每一行的某一字段
打印/etc/passwd文件中以:为分隔符的第1个字段和第6个字段分别表示用户名和其家目录:
$ cut /etc/passwd -d ':' -f 1,6
打印/etc/passwd文件中每一行的前N个字符:
# 前五个(包含第五个)
$ cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
$ cut /etc/passwd -c 5-
# 第五个
$ cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
$ cut /etc/passwd -c 2-5
3.grep 命令,在文本中或 stdin 中查找匹配字符串
grep命令是很强大的,也是相当常用的一个命令,它结合正则表达式可以实现很复杂却很高效的匹配和查找,不过在学习正则表达式之前,这里介绍它简单的使用
grep命令的一般形式为:grep [命令选项]... 用于匹配的表达式 [文件]...
我们搜索/home/shiyanlou目录下所有包含"shiyanlou"的所有文本文件,并显示出现在文本中的行号:
$ grep -rnI "shiyanlou" ~
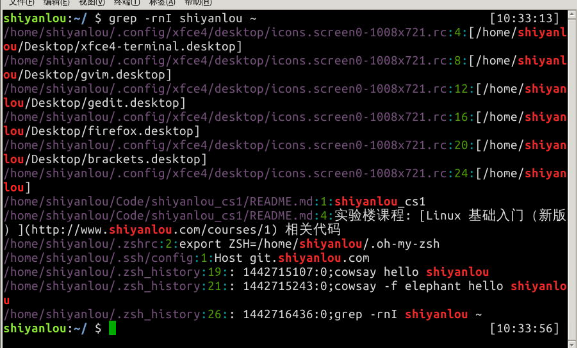
-r 参数表示递归搜索子目录中的文件,-n表示打印匹配项行号,-I表示忽略二进制文件。这个操作实际没有多大意义,但可以感受到grep命令的强大与实用。
当然也可以在匹配字段中使用正则表达式,下面简单的演示:
# 查看环境变量中以"yanlou"结尾的字符串
$ export | grep ".*yanlou$"
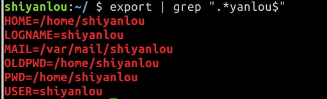
其中$就表示一行的末尾。
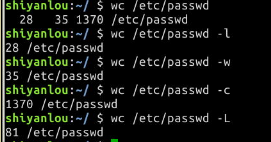
4. wc 命令,简单小巧的计数工具
wc 命令用于统计并输出一个文件中行、单词和字节的数目,比如输出/etc/passwd文件的统计信息:
$ wc /etc/passwd
分别只输出行数、单词数、字节数、字符数和输入文本中最长一行的字节数:
# 行数
$ wc -l /etc/passwd
# 单词数
$ wc -w /etc/passwd
# 字节数
$ wc -c /etc/passwd
# 字符数
$ wc -m /etc/passwd
# 最长行字节数
$ wc -L /etc/passwd
注意:对于西文字符来说,一个字符就是一个字节,但对于中文字符一个汉字是大于2个字节的,具体数目是由字符编码决定的
再来结合管道来操作一下,下面统计 /etc 下面所有目录数:$ ls -dl /etc/*/ | wc -l
5.sort 排序命令
功能很简单就是将输入按照一定方式排序,然后再输出,它支持的排序有按字典排序,数字排序,按月份排序,随机排序,反转排序,指定特定字段进行排序等等。
默认为字典排序:
$ cat /etc/passswd | sort
反转排序:
$ cat /etc/passwd | sort -r
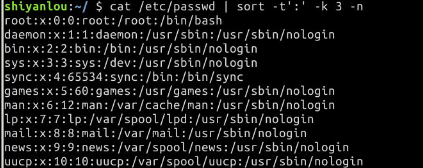
按特定字段排序:
$ cat /etc/passwd | sort -t':' -k 3
上面的-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。这里/etc/passwd文件的第三个字段为数字,默认情况下是一字典序排序的,如果要按照数字排序就要加上-n参数:
$ cat /etc/passwd | sort -t':' -k 3 -n
6. uniq 去重命令
uniq命令可以用于过滤或者输出重复行。
- 过滤重复行
我们可以使用history命令查看最近执行过的命令,不过你可能只想查看使用了那个命令而不需要知道具体干了什么,那么你可能就会要想去掉命令后面的参数然后去掉重复的命令:
$ history | cut -c 8- | cut -d ' ' -f 1 | uniq
然后经过层层过滤,你会发现确是只输出了执行的命令那一列,不过去重效果好像不明显,仔细看你会发现它趋势去重了,只是不那么明显,之所以不明显是因为uniq命令只能去连续重复的行,不是全文去重,所以要达到预期效果,我们先排序:
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq
# 或者$ history | cut -c 8- | cut -d ' ' -f 1 | sort -u- 输出重复行
# 输出重复过的行(重复的只输出一个)及重复次数
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -dc
# 输出所有重复的行
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -D
作业:
9、简单的文本处理
文本处理命令
1.tr 命令
tr 命令可以用来删除一段文本信息中的某些文字。或者将其进行转换。
使用方式:tr [option]...SET1 [SET2]
常用的选项有:
| 选项 | 说明 |
|---|---|
-d |
删除和set1匹配的字符,注意不是全词匹配也不是按字符顺序匹配 |
-s |
去除set1指定的在输入文本中连续并重复的字符 |
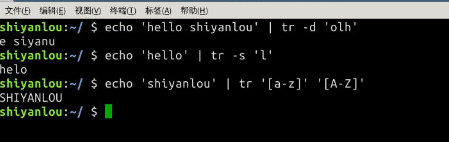
操作举例:
# 删除 "hello shiyanlou" 中所有的'o','l','h'
$ echo 'hello shiyanlou' | tr -d 'olh'
# 将"hello" 中的ll,去重为一个l
$ echo 'hello' | tr -s 'l'
# 将输入文本,全部转换为大写或小写输出
$ cat /etc/passwd | tr '[:lower:]' '[:upper:]'
# 上面的'[:lower:]' '[:upper:]'你也可以简单的写作'[a-z]' '[A-Z]',当然反过来将大写变小写也是可以的
2.col 命令
col 命令可以将Tab换成对等数量的空格建,或反转这个操作。
使用方式:
col [option]
常用的选项有:
| 选项 | 说明 |
|---|---|
-x |
将Tab转换为空格 |
-h |
将空格转换为Tab(默认选项) |
操作举例:
# 查看 /etc/protocols 中的不可见字符,可以看到很多 ^I ,这其实就是 Tab 转义成可见字符的符号
$ cat -A /etc/protocols
# 使用 col -x 将 /etc/protocols 中的 Tab 转换为空格,然后再使用 cat 查看,你发现 ^I 不见了
$ cat /etc/protocols | col -x | cat -A

3.join命令
用于将两个文件中包含相同内容的那一行合并在一起。
使用方式:
join [option]... file1 file2
常用的选项有:
| 选项 | 说明 |
|---|---|
-t |
指定分隔符,默认为空格 |
-i |
忽略大小写的差异 |
-1 |
指明第一个文件要用哪个字段来对比,,默认对比第一个字段 |
-2 |
指明第二个文件要用哪个字段来对比,,默认对比第一个字段 |
操作举例:
# 创建两个文件
$ echo '1 hello' > file1
$ echo '1 shiyanlou' > file2
$ join file1 file2
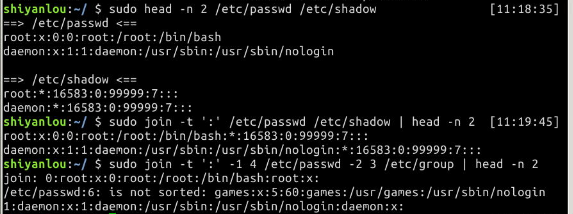
# 将/etc/passwd与/etc/shadow两个文件合并,指定以':'作为分隔符
$ sudo join -t':' /etc/passwd /etc/shadow
# 将/etc/passwd与/etc/group两个文件合并,指定以':'作为分隔符, 分别比对第4和第3个字段
$ sudo join -t':' -1 4 /etc/passwd -2 3 /etc/group
4.paste命令
paste这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开。
使用方式:
paste [option] file...
常用的选项有:
| 选项 | 说明 |
|---|---|
-d |
指定合并的分隔符,默认为Tab |
-s |
不合并到一行,每个文件为一行 |
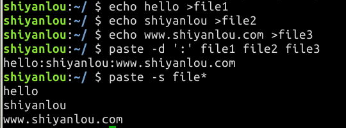
操作举例:
$ echo hello > file1
$ echo shiyanlou > file2
$ echo www.shiyanlou.com > file3
$ paste -d ':' file1 file2 file3
$ paste -s file1 file2 file3
作业:
1.
#从dos 到unix文本格式转换
$ cat -A [dos] | tr -d '^M' | cat -A [dos]
2.
10、数据流重定向
一、数据流重定向
下面我们简单的回顾一下我们前面经常用到的两个重定向操作:
$ echo 'hello shiyanlou' > redirect
$ echo 'www.shiyanlou.com' >> redirect
$ cat redirect
当然前面没有用到的<和<<操作也是没有问题的,如你理解的一样,它们的区别在于重定向的方向不一致而已,>表示是从左到右,<右到左。1.简单的重定向
Linux 默认提供了三个特殊设备,用于终端的显示和输出,分别为stdin(标准输入,对应于你在终端的输入),stdout(标准输出,对应于终端的输出),stderr(标准错误输出,对应于终端的输出)。
| 文件描述符 | 设备文件 | 说明 |
|---|---|---|
0 |
/dev/stdin |
标准输入 |
1 |
/dev/stdout |
标准输出 |
2 |
/dev/stderr |
标准错误 |
文件描述符:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于 UNIX、Linux 这样的操作系统。
默认使用终端的标准输入作为命令的输入和标准输出作为命令的输出
$ cat
(按Ctrl+C退出)
将cat的连续输出(heredoc方式)重定向到一个文件
$ mkdir Documents
$ cat > Documents/test.c\~ <<EOF
#include <stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
EOF
将一个文件作为命令的输入,标准输出作为命令的输出
$ cat Documents/test.c\~
将echo命令通过管道传过来的数据作为cat命令的输入,将标准输出作为命令的输出
$ echo 'hi' | cat
将echo命令的输出从默认的标准输出重定向到一个普通文件
$ echo 'hello shiyanlou' > redirect
$ cat redirect
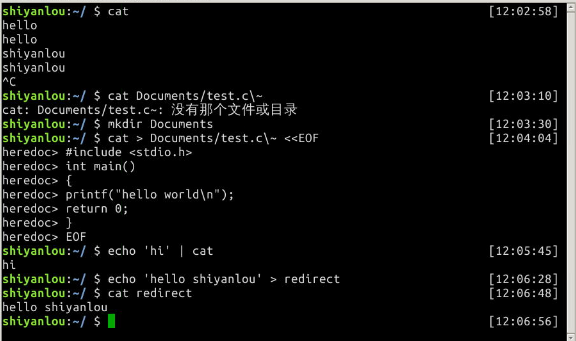
注意不要将管道和重定向混淆,管道默认是连接前一个命令的输出到下一个命令的输入,而重定向通常是需要一个文件来建立两个命令的连接
2.标准错误重定向
标准输出和标准错误都被指向伪终端的屏幕显示
# 使用cat 命令同时读取两个文件,其中一个存在,另一个不存在
$ cat Documents/test.c\~ hello.c
# 你可以看到除了正确输出了前一个文件的内容,还在末尾出现了一条错误信息
# 下面我们将输出重定向到一个文件,根据我们前面的经验,这里将在看不到任何输出了
$ cat Documents/test.c\~ hello.c > somefile
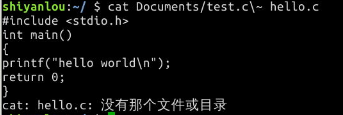
标准输出和标准错误虽然都指向终端屏幕,实际它们并不一样。
那有的时候我们就是要可以隐藏某些错误或者警告:
# 将标准错误重定向到标准输出,再将标准输出重定向到文件,注意要将重定向到文件写到前面
$ cat Documents/test.c\~ hello.c >somefile 2>&1
# 或者只用bash提供的特殊的重定向符号"&"将标准错误和标准输出同时重定向到文件
$ cat Documents/test.c\~ hello.c &>somefilehell
注意你应该在输出重定向文件描述符前加上&,否则shell会当做重定向到一个文件名为1的文件中
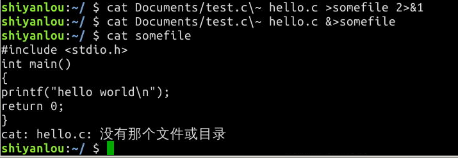
3.使用tee命令同时重定向到多个文件
经常你可能还有这样的需求,除了将需要将输出重定向到文件之外也需要将信息打印在终端,那么你可以使用tee命令来实现:
$ echo 'hello shiyanlou' | tee hello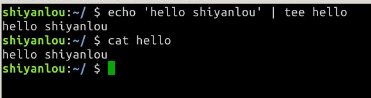
4.永久重定向
使用exec命令实现“永久”重定向。exec命令的作用是使用指定的命令替换当前的 Shell,及使用一个进程替换当前进程,或者指定新的重定向:
# 先开启一个子 Shell
$ zsh
# 使用exec替换当前进程的重定向,将标准输出重定向到一个文件
$ exec 1>somefile
# 后面你执行的命令的输出都将被重定向到文件中,直到你退出当前子shell,或取消exec的重定向(后面将告诉你怎么做)
$ ls
$ exit
$ cat somefile

5.创建输出文件描述符
默认在 Shell 中可以有9个打开的文件描述符,上面我们使用了也是它默认提供的0,1,2号文件描述符,另外我们还可以使用3-8的文件描述符,只是它们默认没有打开而已,你可以使用下面命令查看当前 Shell 进程中打开的文件描述符:
$ cd /dev/fd/;ls -Al
同样使用exec命令可以创建新的文件描述符:
$ zsh
$ exec 3>somefile
# 先进入目录,再查看,否则你可能不能得到正确的结果,然后再回到上一次的目录
$ cd /dev/fd/;ls -Al;cd -
# 注意下面的命令>与&之间不应该有空格,如果有空格则会出错
$ echo "this is test" >&3
$ cat somefile
$ exit

6.关闭文件描述符
如上面我们打开的3号文件描述符,可以使用如下操作将它关闭:
$ exec 3>&-
$ cd /dev/fd;ls -Al;cd -
7.完全屏蔽命令的输出
在 Linux 中有一个被成为“黑洞”的设备文件,所以导入它的数据都将被“吞噬”。
在类 UNIX 系统中,/dev/null,或称空设备,是一个特殊的设备文件,它通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,这些操作通常由重定向完成。读取它则会立即得到一个EOF。
我们可以利用设个/dev/null屏蔽命令的输出:
$ cat Documents/test.c\~ nefile 1>/dev/null 2>&1
向上面这样的操作将使你得不到任何输出结果。
8.使用 xargs 分割参数列表
xargs 是一条 UNIX 和类 UNIX 操作系统的常用命令。它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
这个命令在有些时候十分有用,特别是当用来处理产生大量输出结果的命令如 find,locate 和 grep 的结果。
$ cut -d: -f1 < /etc/passwd | sort | xargs echo
上面这个命令用于将/etc/passwd文件按:分割取第一个字段排序后,使用echo命令生成一个列表。
作业:

11、正则表达式基础
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在 Perl 中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由 UNIX 中的工具软件(例如
sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有 regexp、regex,复数有 regexps、regexes、regexen。
简单的说形式和功能上正则表达式和我们前面讲的通配符很像,不过它们之间又有很大差别,特别在于一些特殊的匹配字符的含义上,希望注意不要将两者弄混淆。
2.基本语法:
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。
选择
|竖直分隔符表示选择,例如"boy|girl"可以匹配"boy"或者"girl"
数量限定
数量限定除了我们举例用的*,还有+加号,?问号,.点号,如果在一个模式中不加数量限定符则表示出现一次且仅出现一次:
+表示前面的字符必须出现至少一次(1次或多次),例如,"goo+gle",可以匹配"gooogle","goooogle"等;?表示前面的字符最多出现一次(0次或1次),例如,"colou?r",可以匹配"color"或者"colour";*星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,“0*42”可以匹配42、042、0042、00042等。
范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体。例如,"gr(a|e)y"等价于"gray|grey",(这里体现了优先级,竖直分隔符用于选择a或者e而不是gra和ey),"(grand)?father"匹配father和grandfather(这里体验了范围,?将圆括号内容作为一个整体匹配)。
语法(部分)
正则表达式有多种不同的风格,下面列举一些常用的作为 PCRE 子集的适用于perl和python编程语言及grep或egrep的正则表达式匹配规则:(由于markdown表格解析的问题,下面的竖直分隔符用全角字符代替,实际使用时请换回半角字符)
PCRE(Perl Compatible Regular Expressions中文含义:perl语言兼容正则表达式)是一个用 C 语言编写的正则表达式函数库,由菲利普.海泽(Philip Hazel)编写。PCRE是一个轻量级的函数库,比Boost 之类的正则表达式库小得多。PCRE 十分易用,同时功能也很强大,性能超过了 POSIX 正则表达式库和一些经典的正则表达式库。
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”、“zo”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“(.|\n)”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。要匹配圆括号字符,请使用“\(”或“\)”。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合(character class)。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。其中特殊字符仅有反斜线\保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果如果出现在首位则仅作为普通字符。 |
| [^xyz] | 排除型(negate)字符集合。匹配未列出的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
优先级
优先级为从上到下从左到右,依次降低:
| 运算符 | 说明 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 括号和中括号 |
| *、+、?、{n}、{n,}、{n,m} | 限定符 |
| ^、$、\任何元字符 | 定位点和序列 |
| | | 选择 |
regex的思导图:

1.基本操作
grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:
| 参数 | 说明 |
|---|---|
-E |
POSIX扩展正则表达式,ERE |
-G |
POSIX基本正则表达式,BRE |
-P |
Perl正则表达式,PCRE |
在通过grep命令使用正则表达式之前,先介绍一下它的常用参数:
| 参数 | 说明 |
|---|---|
-b |
将二进制文件作为文本来进行匹配 |
-c |
统计以模式匹配的数目 |
-i |
忽略大小写 |
-n |
显示匹配文本所在行的行号 |
-v |
反选,输出不匹配行的内容 |
-r |
递归匹配查找 |
-A n |
n为正整数,表示after的意思,除了列出匹配行之外,还列出后面的n行 |
-B n |
n为正整数,表示before的意思,除了列出匹配行之外,还列出前面的n行 |
--color=auto |
将输出中的匹配项设置为自动颜色显示 注:在大多数发行版中是默认设置了grep的颜色的,你可以通过参数指定或修改 |
2.使用正则表达式
使用基本正则表达式,BRE
位置
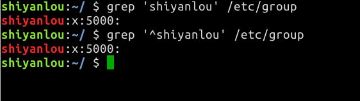
查找/etc/group文件中以"shiyanlou"为开头的行
$ grep 'shiyanlou' /etc/group
$ grep '^shiyanlou' /etc/group
![]()
数量
# 将匹配以'z'开头以'o'结尾的所有字符串
$ echo 'zero\nzo\nzoo' | grep 'z.*o'
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
$ echo 'zero\nzo\nzoo' | grep 'z.o'
# 将匹配以'z'开头,以任意多个'o'结尾的字符串
$ echo 'zero\nzo\nzoo' | grep 'zo*'
注意:其中\n为换行符
![]()

- 选择
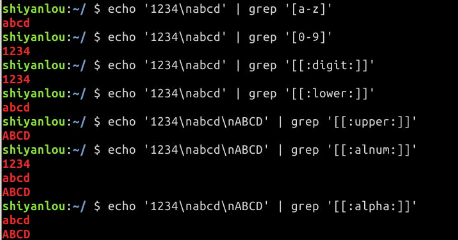
# grep默认是区分大小写的,这里将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[a-z]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[0-9]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[[:digit:]]'
# 将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[[:lower:]]'
# 将匹配所有的大写字母
$ echo '1234\nabcd' | grep '[[:upper:]]'
# 将匹配所有的字母和数字,包括0-9,a-z,A-Z
$ echo '1234\nabcd' | grep '[[:alnum:]]'
# 将匹配所有的字母
$ echo '1234\nabcd' | grep '[[:alpha:]]'
下面包含完整的特殊符号及说明:
| 特殊符号 | 说明 |
|---|---|
[:alnum:] |
代表英文大小写字节及数字,亦即 0-9, A-Z, a-z |
[:alpha:] |
代表任何英文大小写字节,亦即 A-Z, a-z |
[:blank:] |
代表空白键与 [Tab] 按键两者 |
[:cntrl:] |
代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
[:digit:] |
代表数字而已,亦即 0-9 |
[:graph:] |
除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
[:lower:] |
代表小写字节,亦即 a-z |
[:print:] |
代表任何可以被列印出来的字节 |
[:punct:] |
代表标点符号 (punctuation symbol),亦即:" ' ? ! ; : # $... |
[:upper:] |
代表大写字节,亦即 A-Z |
[:space:] |
任何会产生空白的字节,包括空白键, [Tab], CR 等等 |
[:xdigit:] |
代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
注意:之所以要使用特殊符号,是因为上面的[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在
LANG环境变量的值,zh_CN.UTF-8的话[a-z],即为所有小写字母,其它语系可能是大小写交替的如,"a A b B...z Z",[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
# 排除字符
$ echo 'geek|good' | grep '[^o]'
注意:当
^放到中括号内为排除字符,否则表示行首。

使用扩展正则表达式,ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
- 数量
# 只匹配"zo"
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1}'
# 匹配以"zo"开头的所有单词
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1,}'
注意:推荐掌握
{n,m}即可,+,?,*,这几个不太直观,且容易弄混淆。
- 选择
# 匹配"www.shiyanlou.com"和"www.google.com"
$ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -E 'www\.(shiyanlou|google)\.com'
# 或者匹配不包含"baidu"的内容
$ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -Ev 'www\.baidu\.com'
注意:因为.号有特殊含义,所以需要转义。三、sed 流编辑器
sed工具用于过滤和转换文本的流编辑器。它是一个非交互式的编辑器,下面我们就开始介绍sed这个编辑器。
sed常用参数介绍
sed 命令基本格式:
sed [参数]... [执行命令] [输入文件]...
# 形如:
$ sed -i '1s/sad/happy/' test # 表示将test文件中第一行的"sad"替换为"happy"
| 参数 | 说明 |
|---|---|
-n |
安静模式,只打印受影响的行,默认打印输入数据的全部内容 |
-e |
用于在脚本中添加多个执行命令一次执行,在命令行中执行多个命令通常不需要加该参数 |
-f filename |
指定执行filename文件中的命令 |
-r |
使用扩展正则表达式,默认为标准正则表达式 |
-i |
将直接修改输入文件内容,而不是打印到标准输出设备 |
sed编辑器的执行命令(这里”执行“解释为名词)
sed执行命令格式:
[n1][,n2]command
[n1][~step]command
# 其中一些命令可以在后面加上作用范围,形如:
$ sed -i 's/sad/happy/g' test # g表示全局范围
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四个匹配字符串
其中n1,n2表示输入内容的行号,它们之间为,逗号则表示从n1到n2行,如果为~波浪号则表示从n1开始以step为步进的所有行;command为执行动作,下面为一些常用动作指令:
| 命令 | 说明 |
|---|---|
s |
行内替换 |
c |
整行替换 |
a |
插入到指定行的后面 |
i |
插入到指定行的前面 |
p |
打印指定行,通常与-n参数配合使用 |
d |
删除指定行 |
sed操作举例
我们先找一个用于练习的文本文件:
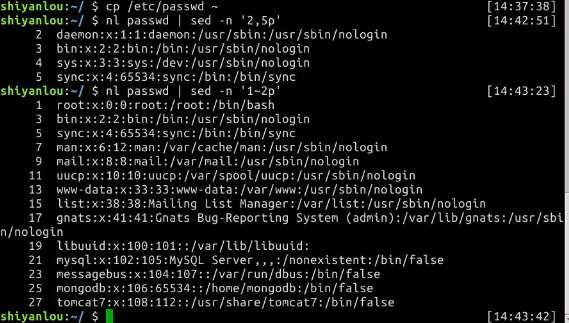
$ cp /etc/passwd ~
打印指定行
# 打印2-5行
$ nl passwd | sed -n '2,5p'
# 打印奇数行
$ nl passwd | sed -n '1~2p'
行内替换
# 将输入文本中"shiyanlou" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n 's/shiyanlou/hehe/gp' passwd
注意: 行内替换可以结合正则表达式使用。行间替换
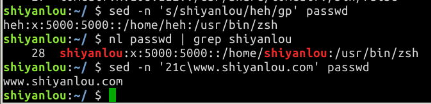
$ nl passwd | grep "shiyanlou"
# 删除第21行
$ sed -n '21c\www.shiyanlou.com' passwd
四、awk文本处理语言
1.awk介绍
AWK是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一.其名称得自于它的创始人Alfred Aho(阿尔佛雷德·艾侯)、Peter Jay Weinberger(彼得·温伯格)和Brian Wilson Kernighan(布莱恩·柯林汉)姓氏的首个字母.AWK程序设计语言,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。最简单地说,AWK是一种用于处理文本的编程语言工具。
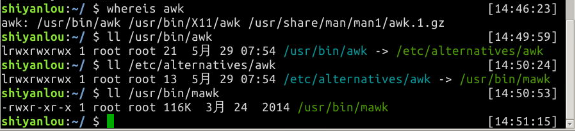
在大多数linux发行版上面,实际我们使用的是gawk(GNU awk,awk的GNU版本),在我们的环境中ubuntu上,默认提供的是mawk,不过我们通常可以直接使用awk命令(awk语言的解释器),因为系统已经为我们创建好了awk指向mawk的符号链接。
$ ll /usr/bin/awk
2.awk的一些基础概念
awk所有的操作都是基于pattern(模式)—action(动作)对来完成的,如下面的形式:
$ pattern {action}
它将所有的动作操作用一对{}花括号包围起来。其中pattern通常是是表示用于匹配输入的文本的“关系式”或“正则表达式”,action则是表示匹配后将执行的动作。在一个完整awk操作中,这两者可以只有其中一个,如果没有pattern则默认匹配输入的全部文本,如果没有action则默认为打印匹配内容到屏幕。
awk处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk以空格作为一个字段的分割符,不过这不是固定了,你可以任意指定分隔符,下面将告诉你如何做到这一点。
3.awk命令基本格式
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中-F参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式) ,-v用于预先为awk程序指定变量,-f参数用于指定awk命令要执行的程序文件,或者在不加-f参数的情况下直接将程序语句放在这里,最后为awk需要处理的文本输入,且可以同时输入多个文本文件。现在我们还是直接来具体体验一下吧。
4.awk操作体验
先用vim新建一个文本文档
$ vim test
包含如下内容:
I like linux
www.shiyanlou.com
- 使用awk将文本内容打印到终端
# "quote>" 不用输入
$ awk '{
> print
> }' test
# 或者写到一行
$ awk '{print}' test- 将test的第一行的每个字段单独显示为一行
$ awk '{
> if(NR==1){
> print $1 "\n" $2 "\n" $3
> } else {
> print}
> }' test
# 或者
$ awk '{
> if(NR==1){
> OFS="\n"
> print $1, $2, $3
> } else {
> print}
> }' test- 将test的第二行的以点为分段的字段换成以空格为分隔
$ awk -F'.' '{
> if(NR==2){
> print $1 "\t" $2 "\t" $3
> }}' test
# 或者
$ awk '
> BEGIN{
> FS="."
> OFS="\t" # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test说明:这里的-F参数,前面已经介绍过,它是用来预先指定待处理记录的字段分隔符。我们需要注意的是除了指定OFS我们还可以在print 语句中直接打印特殊符号如这里的\t,print打印的非变量内容都需要用""一对引号包围起来。上面另一个版本,展示了实现预先指定变量分隔符的另一种方式,即使用BEGIN,就这个表达式指示了,其后的动作将在所有动作之前执行,这里是FS赋值了新的"."点号代替默认的" "空格
6.awk常用的内置变量
| 变量名 | 说明 |
|---|---|
FILENAME |
当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
$0 |
当前记录的内容 |
$N |
N表示字段号,最大值为NF变量的值 |
FS |
字段分隔符,由正则表达式表示,默认为" "空格 |
RS |
输入记录分隔符,默认为"\n",即一行为一个记录 |
NF |
当前记录字段数 |
NR |
已经读入的记录数 |
FNR |
当前输入文件的记录数,请注意它与NR的区别 |
OFS |
输出字段分隔符,默认为" "空格 |
ORS |
输出记录分隔符,默认为"\n" |
作业:
1、练习其他几个命令动作的使用。
2、
12、Linux 下软件安装
一、Linux 上的软件安装
通常 Linux 上的软件安装主要有三种方式:
- 在线安装
- 从磁盘安装deb软件包
- 从二进制软件包安装
- 从源代码编译安装
二、在线安装
在不同的linux发行版上面在线安装方式会有一些差异包括使用的命令及它们的包管理工具,因为我们的开发环境是基于ubuntu的,所以这里我们涉及的在线安装方式将只适用于ubuntu发行版,或其它基于ubuntu的发行版如国内的ubuntukylin(优麒麟),ubuntu又是基于debian的发行版,它使用的是debian的包管理工具dpkg,所以一些操作也适用与debian。而在其它一些采用其它包管理工具的发行版如redhat,centos,fedora等将不适用(redhat和centos使用rpm)。
1. 先体验一下
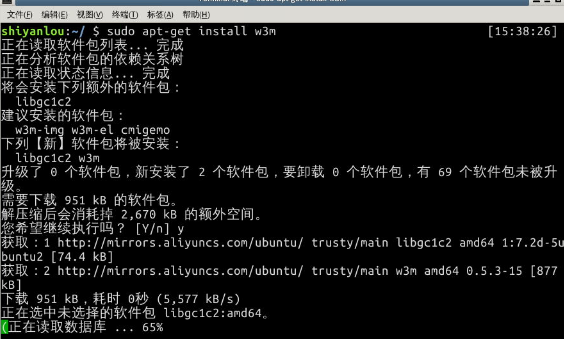
安装一个软件,名字叫做 w3m(w3m是一个命令行的简易网页浏览器),那么输入如下命令:
$ sudo apt-get install w3m我们来看看命令执行后的效果:
$ w3m www.shiyanlou.com/faq
![]()
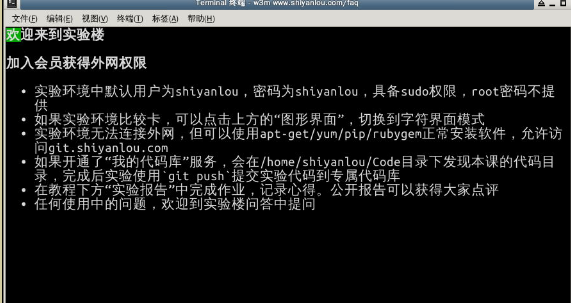
注意:如果你在安装一个软件之后,无法立即使用Tab键补全这可命令,你可以尝试先执行source ~/.zshrc,然后你就可以使用补全操作。
2. apt 包管理工具介绍
APT是Advance Packaging Tool(高级包装工具)的缩写,是Debian及其派生发行版的软件包管理器,APT可以自动下载,配置,安装二进制或者源代码格式的软件包,因此简化了Unix系统上管理软件的过程。APT最早被设计成dpkg的前端,用来处理deb格式的软件包。现在经过APT-RPM组织修改,APT已经可以安装在支持RPM的系统管理RPM包。这个包管理器包含以 apt- 开头的的多个工具,如 apt-get apt-cache apt-cdrom 等,在Debian系列的发行版中使用。
当你在执行安装操作时,首先apt-get 工具会在本地的一个数据库中搜索关于 w3m 软件的相关信息,并根据这些信息在相关的服务器上下载软件安装
- 软件源镜像服务器
- 软件源
我们需要定期从服务器上下载一个软件包列表,使用 sudo apt-get update 命令来保持本地的软件包列表是最新的(有时你也需要手动执行这个操作,比如更换了软件源),而这个表里会有软件依赖信息的记录,对于软件依赖,我举个例子:我们安装 w3m 软件的时候,而这个软件需要 libgc1c2 这个软件包才能正常工作,这个时候 apt-get 在安装软件的时候会一并替我们安装了,以保证 w3m 能正常的工作。
3.apt-get
apt-get使用各用于处理apt包的公用程序集,我们可以用它来在线安装、卸载和升级软件包等,下面列出一些apt-get包含的常用的一些工具:
| 工具 | 说明 |
|---|---|
install |
其后加上软件包名,用于安装一个软件包 |
update |
从软件源镜像服务器上下载/更新用于更新本地软件源的软件包列表 |
upgrade |
升级本地可更新的全部软件包,但存在依赖问题时将不会升级,通常会在更新之前执行一次update |
dist-upgrade |
解决依赖关系并升级(存在一定危险性) |
remove |
移除已安装的软件包,包括与被移除软件包有依赖关系的软件包,但不包含软件包的配置文件 |
autoremove |
移除之前被其他软件包依赖,但现在不再被使用的软件包 |
purge |
与remove相同,但会完全移除软件包,包含其配置文件 |
clean |
移除下载到本地的已经安装的软件包,默认保存在/var/cache/apt/archives/ |
autoclean |
移除已安装的软件的旧版本软件包 |
下面是一些apt-get常用的参数:
| 参数 | 说明 |
|---|---|
-y |
自动回应是否安装软件包的选项,在一些自动化安装脚本中使用这个参数将十分有用 |
-s |
模拟安装 |
-q |
静默安装方式,指定多个q或者-q=#,#表示数字,用于设定静默级别,这在你不想要在安装软件包时屏幕输出过多时很有用 |
-f |
修复损坏的依赖关系 |
-d |
只下载不安装 |
--reinstall |
重新安装已经安装但可能存在问题的软件包 |
--install-suggests |
同时安装APT给出的建议安装的软件包 |
4.安装软件包
关于安装,如前面演示的一样你只需要执行apt-get install <软件包名>即可
可以使用如下方式重新安装:
$ sudo apt-get --reinstall install w3m
在不知道软件包完整名的时候进行安装。通常是使用Tab键补全软件包名,有时候需要同时安装多个软件包,还可以使用正则表达式匹配软件包名进行批量安装。
5.软件升级
# 更新软件源
$ sudo apt-get update
# 升级没有依赖问题的软件包
$ sudo apt-get upgrade
# 升级并解决依赖关系
$ sudo apt-get dist-upgrade
6.卸载软件
卸载是一个命令加回车 sudo apt-get remove w3m

或者,你可以执行
# 不保留配置文件的移除
$ sudo apt-get purge w3m
# 或者 sudo apt-get --purge remove
# 移除不再需要的被依赖的软件包
$ sudo apt-get autoremove7.软件搜索
sudo apt-cache search softname1 softname2 softname3……
apt-cache 命令则是针对本地数据进行相关操作的工具,search 顾名思义在本地的数据库中寻找有关 softname1 softname2 …… 相关软件的信息。
现在我们试试搜索一下之前我们安装的软件 w3m ,如图:
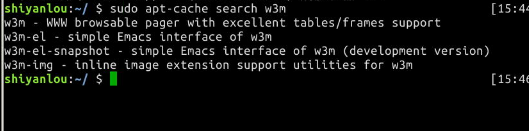
结果显示了4个 w3m 相关的软件,并且有相关软件的简介。
三、使用 dpkg 从本地磁盘安装 deb 软件包
1.dpkg 介绍
dpkg 是 Debian 软件包管理器的基础,它被伊恩·默多克创建于 1993 年。dpkg 与 RPM 十分相似,同样被用于安装、卸载和供给和 .deb 软件包相关的信息。
dpkg 本身是一个底层的工具。上层的工具,像是 APT,被用于从远程获取软件包以及处理复杂的软件包关系。"dpkg"是"Debian Package"的简写。
我们经常可以在网络上简单以deb形式打包的软件包,就需要使用dpkg命令来安装。
dpkg常用参数介绍:
| 参数 | 说明 |
|---|---|
-i |
安装指定deb包 |
-R |
后面加上目录名,用于安装该目录下的所有deb安装包 |
-r |
remove,移除某个已安装的软件包 |
-I |
显示deb包文件的信息 |
-s |
显示已安装软件的信息 |
-S |
搜索已安装的软件包 |
-L |
显示已安装软件包的目录信息 |
2.使用dpkg安装deb软件包
我们先使用apt-get加上-d参数只下载不安装,下载emacs编辑器的deb包,下载完成后,我们可以查看/var/cache/apt/archives/目录下的内容,如下图:
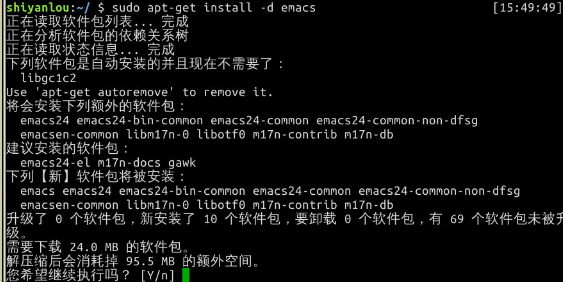
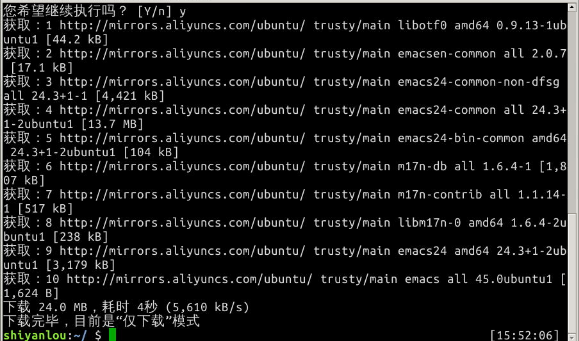
然后我们将第一个deb拷贝到home目录下,并使用dpkg安装
$ cp /var/cache/apt/archives/emacs24_24.3+1-4ubuntu1_amd64.deb ~
# 安装之前参看deb包的信息
$ sudo dpkg -I emacs24_24.3+1-4ubuntu1_amd64.deb
如你所见,这个包还额外依赖了一些软件包,这意味着,如果主机目前没有这些被依赖的软件包,直接使用dpkg安装可能会存在一些问题,因为dpkg并不能为你解决依赖关系。
# 使用dpkg安装
$ sudo dpkg -i emacs24_24.3+1-4ubuntu1_amd64.deb我们将如何解决这个错误了,这就要用到apt-get了,使用它的-f参数了,修复依赖关系的安装
$ sudo apt-get -f install
3.查看已安装软件包的安装目录
使用dpkg -L查看deb包目录信息
$ sudo dpkg -L emacs
四、从二进制包安装
二进制包的安装比较简单,我们需要做的只是将从网络上下载的二进制包解压后放到合适的目录,然后将包含可执行的主程序文件的目录添加进PATH环境变量即可。
作业:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号