正则表达式
正则表达式是一个考验每个程序员记忆力的功能,大家都经历过忘了再记,记了再忘的痛苦,在这里试图先通过一个简单的表格方式来呈现它,然后再慢慢品味,消化它。
1.符号表
| 名称 | 符号 | 读音 | 功能 |
| 定界符 | /love/ | 右斜杠 | 位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式 |
| 普通字符 | [abc] | 匹配中括号中的所有字符 | |
| 元字符 | 所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式 | ||
| + | 加号 | “+”元字符规定其前导字符必须在目标对象中连续出现一次或多次, | |
| * | 星花 | “*”元字符规定其前导字符必须在目标对象中出现零次或连续多次 | |
| ? | 问号 | “?”元字符规定其前导对象必须在目标对象中连续出现零次或一次,或指明一个非贪婪限定符。通过在 *、+ 或?限定符之后放置?,该表达式从"贪婪"表达式转换为"非贪婪"表达式或者最小匹配 | |
| \s | 左斜杠小s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符 | |
| \S | 左斜杠大s | 匹配任何非空白字符,等价于 [^ \f\n\r\t\v] | |
| \d | 左斜杠小d | “\d”用于匹配从0到9的数字 | |
| \w | 左斜杠小w | “\w”用于匹配字母,数字或下划线字符 | |
| \W | 左斜杠大w | “\W”用于匹配所有与\w不匹配的字符 | |
| . | 点 | “.”用于匹配除换行符之外的所有字符 | |
| 定位符 | 定位符用于规定匹配模式在目标对象中的出现位置 | ||
| ^ | 尖帽 | “^”定位符规定匹配模式必须出现在目标字符串的开头 | |
| $ | 美元符 | 匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则字符本身,请使用$ | |
| \b | 左斜杠小b | “\b”定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一 | |
| \B | 左斜杠大B | “\B”定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内,即匹配对象既不能作为目标字符串的开头,也不能作为目标字符串的结尾 | |
| 频率符 | {} | 左花括号右花括号 | “{}”可以精确指定模式在匹配对象中出现的频率 |
| {n} | 等于 | n是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 | |
| {n,} | 大于等于 | n是一个非负整数。至少匹配n次。例如'o{2,}'不能匹配"Bob"中的 'o',但能匹配 "foooood" 中的所有o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 | |
| {n,m} | 大于等于小于等于 | m和n均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}"将匹配 "fooooood"中的前三个 o。'o{0,1}'等价于 'o?'。请注意在逗号和两个数之间不能有空格。 | |
| 范围符 | [A-Z] | 左中括号右中括号 | “[]”允许使用者在匹配模式中指定某一个范围而不局限于具体的字符 |
| 同时出现符 | () | 左圆括号右圆括号 | “()”符号包含的内容必须同时出现在目标对象中 |
| 运算符 | | | 竖杠 | 可以使用管道符 “|”实现类似编程逻辑中的“或”运算 |
| [^] | 左中括号尖帽右中括号 | 否定符 “[^]”规定目标对象中不能存在模式中所规定的字符串 | |
| 转义符 | \ | 左斜杠 | 当需要在正则表达式的模式中加入元字符,并查找其匹配对象时,可以使用转义符“\” |
| 非打印字符 | \cx | 控制符 | 匹配由x指定的控制字符。例如\cM匹配一个Control-M或回车字符。x的值必须为A-Z或a-z |
| \f | 换页符 | 匹配一个换页符,等价于 \x0c 和 \cL | |
| \n | 换行符 | 匹配一个换行符,等价于\x0a和\cJ | |
| \r | 回车符 | 匹配一个回车符,等价于\x0d和\cM | |
| \t | 制表符 | 匹配一个制表符,等价于\x09和\cl | |
| \v | 垂直制表符 | 匹配一个垂直制表符,等价于\x0b和\ck | |
1.1普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。包含所有大写和小写字母,所有数字,所有标点符号和一些其他字符。
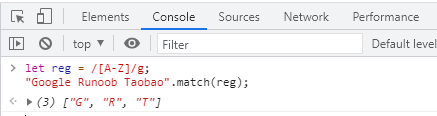
[ABC]:匹配[...]中所有的字符,例如[aeiou]匹配字符串“google runoob taobao”中所有的aeiou字符,如下:

[^ABC]:匹配除了[...]中字符以外的所有字符,例如[^aeiou]匹配字符串“google runoob taobao”中除了aeiou之外的所有字母,如下:

[A-Z]:[A-Z]表示一个区间,匹配所有大写字母,[a-z]表示所有小写字母,如下:
.:匹配除换行符(\r, \n)之外的任何单个字符,等于[^\n\r],如下:

[\s\S]:匹配所有。\s是匹配所有空白字符,包含换行,\S非空白符,不包含换行,如下:

\w:匹配字母,数字,下划线。等价于[A-Za-z0-9_],如下:

1.2非打印字符
非打印字符也可以是正则表达式的一部分,下表列举了非打印字符的转义序列。
| 字符 | 描述 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] |
| \t | 匹配一个制表符。等价于 \x09 和 \cI |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK |
1.3特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如runoo*b中的*,简单的说就是表示任何字符串的意思。如果要查找字符串中的*符号,则需要对*进行转义,即在起前面加一个\,例如runo\*ob匹配字符串runo*ob。
许多元字符要求在试图匹配他们的时候对他们特别对待,若要匹配这些特殊字符,必须首先使字符转义,即,使用反斜杠\放在他们前面。
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 字符本身,请使用 $ |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^ |
| () | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \* |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+ |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \? |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[ |
| ] | 标记一个中括号表达式的结束。要匹配 ],请使用 \] |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{ |
| } | 标记限定符表达式的结束。要匹配 },请使用 \} |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "(" |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \| |
1.4限定符
限定符用来指定正则表达式的一个给定的组件必须出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m}共6种。
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,} |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,} |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1} |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*' |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格 |
正则表达式/[1-9][0-9]*/g匹配一个正整数,[1-9]是指第一位数字不能是0,[0-9]*匹配任意多个数字。
注意限定符出现在范围表达式之后。因此,它应用于整个范围表达式,在本例中,只指定从0到9的数字(包括0和9)。这里不适用+限定符,因为在第二个位置或后面不一定需要有一个数字。也不适用?字符,因为使用?会将整数限制到只有两位数。
如果想想设置0~99的两位数,可以使用
/[0-9]{1,2}/
这个表达式的缺点是,只能匹配两位数字,而且可以匹配0,00,01,10,99的章节编号仍只匹配开头两位数字,改进一下,匹配1~99的正则表达式如下:
/[1-9][0-9]?/ 或 /[1-9][0-9]{0,1}/
*和+限定符都是贪婪的,因为他们会尽可能多的匹配文字,只有在他们的后面加上一个?就可以实现非贪婪或最小匹配。
例如:要搜索html文档,以查找在h1标签内容。HTML代码如下:
<h1>标题1</h1>
贪婪:下面的表达式匹配从开始小括号(<)到关闭h1标记的大括号(>)之间所有的内容,得到的结果是<h1>标题1</h1>
/<.*>/
非贪婪:如果只需要匹配开始和结束h1标签,下面的非贪婪表达式只匹配<h1>
/<.*?>/
也可以使用下面的表达式来匹配h1标签:
/<\w+?>/
通过在 *,+ 或 ? 限定符知否放置 ? ,表达式从“贪婪”表达式转换为“非贪婪”表达式或者最小匹配。
1.4定位符
定位符能将正则表达式固定到行首或行尾,还可以使用定位符匹配一个单词内部,一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指定字符串的开始与结束,\b描述单词的前后边界,\B表示费单词边界。正则表达式定位符有:
| ^ | 匹配输入字符串开始的位置。如果设置了RegExp对象的Muliline属性,^还会与\n,\r之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了RegExp对象的Multiline属性,$还会与\n,\r之前的位置匹配。 |
| \b | 匹配一个单词边界,即与空格键的位置。 |
| \B | 匹配非单词边界。 |
注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或者后面不能有一个以上的位置,因此不允许有^*这样的表达式。
若要匹配一行文本开始出的文本,需要在正则表达式的开始使用^字符。不要将^这种写法与中括号表达式内的用法混淆。
若要匹配一行文本结束出的文本,需要在正则表达式的结束处使用$字符。
若要在搜索章节标题时使用定位点,下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字,并且出现在行首:
/^Chapter [1-9][0-9]{0,1}/
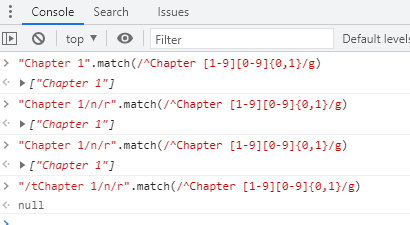
真正的章节标题不仅出现在行的开始处,而且它还是该行中仅有的文本。它既出现在行首又出现在同一行的结尾。下面的表达式能确保指定的匹配只匹配章节而不匹配交叉引用。通过创建只匹配一行文本的开始和结尾的正则表达式就可以做到这一点。
/^Chapter [1-9][0-9]{0,1}$/
匹配单词边界稍有不同,但向正则表达式添加了很重要的功能。单词边界是单词和空格之间的位置,非单词边界是任何其他位置。下面的表达式匹配单词Chapter的开头三个字符,因为这三个字符出现在单词边界后面:
/\bCha/

\b字符的位置非常重要。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项。如果它位于字符串的结尾,它在单词的结尾处查找匹配。例如下面的表达式匹单词Chapter中的字符串ter,因为它出现在单词边界的前面:
/ter\b/
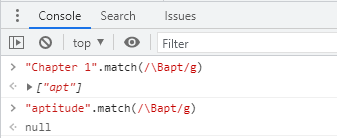
下面的表达式匹配Chapter中的字符串apt,但是不匹配aptitude中的字符串apt:
/\Bapt/
字符串apt出现在单词Chapter中的非单词边界处,但是出现在单词aptitude中的单词边界处。对于\B非单词边界运算符,位置并不重要,因为匹配不关心究竟是单词开头还是单词结尾。
1.5选择
用圆括号()将所有选择项括起来,相邻的选择项质检用 | 分割。
() 表示捕获分组,()会把每个分组里的匹配的值保存起来,多个匹配值可以通过数字 n 来看(n是一个数字,表示第n个捕获组的内容)
但使用园括号会有一个副作用,使相关的匹配被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用。
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?! ,这两个还有更多的含义,前者为正向鱼叉,在任何开始匹配圆括号内的正则表达式模式的位置来搜索字符串,后者为负向检查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
2.基本语法
正则表达式(regulare expression)描述了一种字符串匹配的模式(pattern),可以用来监测一个字符串是否包含某个子字符串,将匹配的子字符串替换,或者从某个字符串中提取出符合条件的子字符串。
例如:
- runoo+b,可以匹配出runoob,runooob,runooooooob等,runo必须出现,o+代表字符o必须至少出现1次(1次或多次)。
- runoo*b,可以匹配出runob,runoob,runooooob等,runo必须出现,o*代表字符o可以不出现,也可以出现1次或者多次(0次或1次或多次)。
- colou?r,可以匹配color或者colour,colo必须出现,u?代表字符u最多只可以出现1次(0次或1次)
2.1构造正则表达式
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多元字符串与运算符将小的表达式结合在一起来创建更大的表达式。正则表达式的组合可以是单个字符,字符集合,字符范围,字符间的选择或者这些任意组合起来。
正则表达式是由普通字符(例如字符a到z)以及特殊字符(称为“元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与搜索的字符串进行匹配。
在JavaScript中有两种方式构造正则表达式。
使用正则表达式字面量
正则表达式的形式一般如:/love/,这种叫“直接量语法”,还有一种叫RegExp构造函数,貌似这两种是差不多的。“直接量语法”的格式形如/pattern/attributes。脚本加载后,正则表达式字面量就会被编译。当正则表达式保持不变时,使用这种方式可以获得更好的性能。
使用RegExp构造函数
RegExp构造函数的个数形如new RegExp(pattern,attributes)。脚本运行过程中,使用构造函数创建的正则表达式会被编译。如果正则表达式将会改变,或者它将会从用户输入等来运中动态地生成,就需要使用构造函数来创建正则表达式。
其中位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式。用户只要把希望查找匹配对象的模式内容放入“/”定界符之间即可。为了能够使用户更加灵活的定制模式内容,正则表达式提供了专门的“元字符”。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
较为常用的元字符包括: “+”, “*”,以及 “?”。其中,“+”元字符规定其前导字符必须在目标对象中连续出现一次或多次,“*”元字符规定其前导字符必须在目标对象中出现零次或连续多次,而“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次。
下面,就让我们来看一下正则表达式元字符的具体应用。
/fo+/因为上述正则表达式中包含“+”元字符,表示可以与目标对象中的 “fool”, “fo”, 或者 “football”等在字母f后面连续出现一个或多个字母o的字符串相匹配。
/eg*/因为上述正则表达式中包含“*”元字符,表示可以与目标对象中的 “easy”, “ego”, 或者 “egg”等在字母e后面连续出现零个或多个字母g的字符串相匹配。
/Wil?/因为上述正则表达式中包含“?”元字符,表示可以与目标对象中的 “Win”, 或者 “Wilson”,等在字母i后面连续出现零个或一个字母l的字符串相匹配。
除了元字符之外,用户还可以精确指定模式在匹配对象中出现的频率。例如,/jim{2,6}/上述正则表达式规定字符m可以在匹配对象中连续出现2-6次,因此,上述正则表达式可以同jimmy或jimmmmmy等字符串相匹配。
在对如何使用正则表达式有了初步了解之后,我们来看一下其它几个重要的元字符的使用方式。
\s:用于匹配单个空格符,包括tab键和换行符;
\S:用于匹配除单个空格符之外的所有字符;
\d:用于匹配从0到9的数字;
\w:用于匹配字母,数字或下划线字符;
\W:用于匹配所有与\w不匹配的字符;
. :用于匹配除换行符之外的所有字符。
(说明:我们可以把\s和\S以及\w和\W看作互为逆运算)
下面,我们就通过实例看一下如何在正则表达式中使用上述元字符。
/\s+/上述正则表达式可以用于匹配目标对象中的一个或多个空格字符。
/\d000/如果我们手中有一份复杂的财务报表,那么我们可以通过上述正则表达式轻而易举的查找到所有总额达千元的款项。
除了我们以上所介绍的元字符之外,正则表达式中还具有另外一种较为独特的专用字符,即定位符。定位符用于规定匹配模式在目标对象中的出现位置。较为常用的定位符包括: “^”, “”定位符规定匹配模式必须出现在目标对象的结尾,\b定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一,而“\B”定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内,即匹配对象既不能作为目标字符串的开头,也不能作为目标字符串的结尾。同样,我们也可以把“^”和“$”以及“\b”和“\B”看作是互为逆运算的两组定位符。举例来说:
/^hell/因为上述正则表达式中包含“^”定位符,所以可以与目标对象中以 “hell”, “hello”或 “hellhound”开头的字符串相匹配。
/ar”定位符,所以可以与目标对象中以 “car”, “bar”或 “ar” 结尾的字符串相匹配。
/\bbom/因为上述正则表达式模式以“\b”定位符开头,所以可以与目标对象中以 “bomb”, 或 “bom”开头的字符串相匹配。
/man\b/因为上述正则表达式模式以“\b”定位符结尾,所以可以与目标对象中以 “human”, “woman”或 “man”结尾的字符串相匹配。
为了能够方便用户更加灵活的设定匹配模式,正则表达式允许使用者在匹配模式中指定某一个范围而不局限于具体的字符。例如:
/[A-Z]/上述正则表达式将会与从A到Z范围内任何一个大写字母相匹配。
/[a-z]/上述正则表达式将会与从a到z范围内任何一个小写字母相匹配。
/[0-9]/上述正则表达式将会与从0到9范围内任何一个数字相匹配。
/([a-z][A-Z][0-9])+/上述正则表达式将会与任何由字母和数字组成的字符串,如 “aB0” 等相匹配。这里需要提醒用户注意的一点就是可以在正则表达式中使用 “()” 把字符串组合在一起。“()”符号包含的内容必须同时出现在目标对象中。因此,上述正则表达式将无法与诸如 “abc”等的字符串匹配,因为“abc”中的最后一个字符为字母而非数字。
如果我们希望在正则表达式中实现类似编程逻辑中的“或”运算,在多个不同的模式中任选一个进行匹配的话,可以使用管道符 “|”。例如:/to|too|2/,上述正则表达式将会与目标对象中的 “to”, “too”, 或 “2” 相匹配。正则表达式中还有一个较为常用的运算符,即否定符 “[^]”。与我们前文所介绍的定位符 “^” 不同,否定符 “[^]”规定目标对象中不能存在模式中所规定的字符串。例如:/[^A-C]/,上述字符串将会与目标对象中除A,B,和C之外的任何字符相匹配。一般来说,当“^”出现在 “[]”内时就被视做否定运算符;而当“^”位于“[]”之外,或没有“[]”时,则应当被视做定位符。最后,当用户需要在正则表达式的模式中加入元字符,并查找其匹配对象时,可以使用转义符“\”。例如:/Th\*/上述正则表达式将会与目标对象中的“Th*”而非“The”等相匹配。
3.举例说明
再者只能多看写例子,消化消化了。
“^The”:开头一定要有”The”字符串;“of despair”:就是要求以abc开头和以abc结尾的字符串,实际上是只有abc匹配;“notice”:匹配包含notice的字符串;接着,说说 ‘*’ ‘+’ 和 ‘?’,他们用来表示一个字符可以出现的次数或者顺序,他们分别表示:
“zero or more”相当于{0,}
“one or more”相当于{1,}
“zero or one.”相当于{0,1}
这里是一些例子:
“ab*”:和ab{0,}同义,匹配以a开头,后面可以接0个或者N个b组成的字符串(”a”, “ab”, “abbb”, 等);
“ab+”:和ab{1,}同义,同上条一样,但最少要有一个b存在 (”ab” “abbb”等);
“ab?”:和ab{0,1}同义,可以没有或者只有一个b;
“a?b+$”:匹配以一个或者0个a再加上一个以上的b结尾的字符串。
要点:’*’ ‘+’ 和 ‘?’ 只管它前面那个字符。你也可以在大括号里面限制字符出现的个数,比如:
“ab{2}”: 要求a后面一定要跟两个b(一个也不能少)(”abb”);
“ab{2,}”: 要求a后面一定要有两个或者两个以上b(如”abb” “abbbb” 等);
“ab{3,5}”: 要求a后面可以有2-5个b(”abbb”, “abbbb”, or “abbbbb”)。
现在我们把一定几个字符放到小括号里,比如:
“a(bc)*”: 匹配 a 后面跟0个或者一个”bc”;
“a(bc){1,5}”: 一个到5个 “bc”;
还有一个字符 ‘|’,相当于OR操作:
“hi|hello”: 匹配含有”hi” 或者 “hello” 的 字符串;
“(b|cd)ef”: 匹配含有 “bef” 或者 “cdef”的字符串;
“(a|b)*c”: 匹配含有这样多个(包括0个)a或b,后面跟一个c的字符串;
一个点(’.’)可以代表所有的单一字符,不包括”\n”如果,要匹配包括”\n”在内的所有单个字符,怎么办?用’[\n.]’这种模式。
“a.[0-9]”: 一个a加一个字符再加一个0到9的数字;
“^.{3}$”: 三个任意字符结尾。
中括号括住的内容只匹配一个单一的字符
“[ab]”: 匹配单个的 a 或者 b ( 和 “a│b” 一样);
“[a-d]”: 匹配’a’ 到’d’的单个字符 (和”a│b│c│d” 还有 “[abcd]”效果一样);
一般我们都用[a-zA-Z]来指定字符为一个大小写英文:
“^[a-zA-Z]”: 匹配以大小写字母开头的字符串;
“[0-9]%”: 匹配含有 形如 x% 的字符串;
“,[a-zA-Z0-9]$”: 匹配以逗号再加一个数字或字母结尾的字符串;
也可以把你不想要得字符列在中括号里,你只需要在总括号里面使用’^’ 作为开头 “%[^a-zA-Z]%” 匹配含有两个百分号里面有一个非字母的字符串。要点:^用在中括号开头的时候,就表示排除括号里的字符。不要忘记在中括号里面的字符是这条规路的例外—在中括号里面,所有的特殊字符,包括(”),都将失去他们的特殊性质 “[*\+?{}.]”匹配含有这些字符的字符串:正如regx的手册告诉我们:”如果列表里含有’]’,最好把它作为列表里的第一个字符(可能跟在’^’后面)。如果含有’-’,最好把它放在最前面或者最后面, or 或者一个范围的第二个结束点[a-d-0-9]中间的‘-’将有效。花括号中的要注意的是,n和m都不能为负整数,而且n总是小于m。这样,才能 最少匹配n次且最多匹配m次。如”p{1,5}”将匹配 “pvpppppp”中的前五个p。
构建一个匹配模式去检查输入的信息是否为一个表示money的数字。我们认为一个表示money的数量有四种方式:”10000.00″ 和 “10,000.00″,或者没有小数部分,”10000″ and “10,000″。现在让我们开始构建这个匹配模式:
^[1-9][0-9]*$
这是所变量必须以非0的数字开头。但这也意味着单一的”0″也不能通过测试。以下是解决的方法:
^(0|[1-9][0-9]*)$
“只有0和不以0开头的数字与之匹配”,我们也可以允许一个负号在数字之前:
^(0|-?[1-9][0-9]*)$
这就是:0或者一个以0开头且可能有一个负号在前面的数字。好了,现在让我们别那么严谨,允许以0开头。现在让我们放弃负号,因为我们在表示钱币的时候并不需要用到。我们现在指定模式用来匹配小数部分:
^[0-9]+(\.[0-9]+)?$
这暗示匹配的字符串必须最少以一个阿拉伯数字开头。但是注意,在上面模式中 “10.” 是不匹配的, 只有 “10″ 和 “10.2″ 才可以,为什么?
^[0-9]+(\.[0-9]{2})?。这将允许小数点后面有一到两个字符。现在我们加上用来增加可读性的逗号(每隔三位),我们可以这样表示:
^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?money)然后在把类型看成double然后我们就可以通过他做数学计算了。
再来构建一个完整的email,在一个完整的email地址中有三个部分:
1. 用户名 (在 ‘@’ 左边的一切)
2.’@’
3. 服务器名(就是剩下那部分)
用户名可以含有大小写字母阿拉伯数字,句号(’.’)减号(’-’)and下划线’_’)。服务器名字也是符合这个规则,当然下划线除外。现在,用户名的开始和结束都不能是句点,服务器也是这样。还有你不能有两个连续的句点他们之间至少存在一个字符,好现在我们来看一下怎么为用户名写一个匹配模式:
^[_a-zA-Z0-9-]+$
现在还不能允许句号的存在。我们把它加上:
^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*$
上面的意思就是说:以至少一个规范字符(除了.)开头,后面跟着0个或者多个以点开始的字符串。
简单化一点, 我们可以用eregi()取代ereg()、eregi()对大小写不敏感, 我们就不需要指定两个范围 “a-z” 和 “A-Z”只需要指定一个就可以了:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*$
后面的服务器名字也是一样,但要去掉下划线:
^[a-z0-9-]+(\.[a-z0-9-]+)*$
现在只需要用”@”把两部分连接:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$
这就是完整的email认证匹配模式了,只需要调用:
eregi(”^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*eamil)
就可以得到是否为email了
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号) ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))" //非负整数(正整数 + 0)
"^[0-9]*[1-9][0-9]*" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*" //整数
"^\d+(\.\d+)?" //正浮点数
"^((-\d+(\.\d+)?)|(0+(\.0+)?))" //负浮点数
"^(-?\d+)(\.\d+)?" //由26个英文字母组成的字符串
"^[A-Z]+" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+" //由数字、26个英文字母或者下划线组成的字符串
"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+" //url
/^13\d{9}$/gi手机号正则表达式
public static bool IsValidMobileNo(string MobileNo)
{
const string regPattern = @"^(130|131|132|133|134|135|136|137|138|139)\d{8}$";
return Regex.IsMatch(MobileNo, regPattern);
}
正则表达式--验证手机号码:13[0-9]{9}
实现手机号前带86或是+86的情况:^((\+86)|(86))?(13)\d{9}|(13[0-9]{9})
提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
提取信息中的中国手机号码:(86)*0*13\d{9}
提取信息中的中国固定电话号码:(|\d{3,4}-|\s)?\d{8}
提取信息中的中国电话号码(包括移动和固定电话):(|\d{3,4}-|\s)?\d{7,14}
提取信息中的中国邮政编码:[1-9]{1}(\d+){5}
提取信息中的中国身份证号码:\d{18}|\d{15}
提取信息中的整数:\d+
提取信息中的浮点数(即小数):(-?\d*)\.?\d+
提取信息中的任何数字 :(-?\d*)(\.\d+)?
提取信息中的中文字符串:[\u4e00-\u9fa5]* 或者 /^[\u4E00-\u9FA5]+$/
提取信息中的双字节字符串 (汉字):[^\x00-\xff]*
3.举例说明
今天遇到一个问题,这个分页做的很简单,就两个按钮, 一个“上一页”,一个“下一页”,前面一个label显示“第2页 共5页”,现在想在显示“第1页 共5页”的时候点击“上一页”提示“已经第一页了啊”,当显示“第1页 共5页”,点击下一页的时候提示“已经最后一页了啊”,如何把字符串"第2页 共5页"中的数字2和5提取出来,先看代码,

$("#ctl00_MainContent_butPre,#ctl00_MainContent_butNex").on("click", function () {
var pageString = $("#ctl00_MainContent_labCurPag").html(),
id = $(this).attr("id"),
reg = /([1-9][0-9]*)/g,
pageNumbers = pageString.match(reg),
tips = "";
if (/Pre/.test(id) && "1" == pageNumbers[0]) {
tips = "已经第一页了啊";
}
else if (/Nex/.test(id) && pageNumbers[0] == pageNumbers[1]) {
tips = "已经最后一页了啊";
}
if (tips) {
var d = dialog({
title: '提示',
content: tips,
});
d.show();
return false;
}
});
从w3c上看到exec是正则表达式的方法,它以字符串为参数,如下所示:返回结果是
var reg = new RegExp("abc") ;
var str = "3abc4,5abc6";
reg.exec(str );
看到这个例子的时候我觉得有戏,照葫芦画瓢这样写
var reg = new RegExp("[1-9][0-9]*", "g") ;
var str = "第2页 共5页";
var result = reg.exec(str );
console.log(result);
返回结果如下:

很明显不是我想要的答案,除了当前页我还想知道总共多少页,就是那个5。
match是字符串执行匹配正则表达式规则的方法,它的参数是正则表达
var reg = new RegExp("abc") ;
var str = "3abc4,5abc6";
str.match(reg);
3、exec和match返回的都是数组;
如果exec执行的正则表达式没有子表达式(小括号内的内容,如/abc(\s*)/中的(\s*) ),如果有匹配,就返回第一个匹配的字符串内容,此时的数组仅有一个元素,如果没有匹配返回null;
var reg = new RegExp("abc") ;
var str = "3abc4,5abc6";
alert(reg.exec(str));
alert(str.match(reg));
执行如上代码,你会发现两者内容均为一样:abc,
4、如果定义正则表达对象为全局匹配如:
var reg = new RegExp("abc","g") ;
var str = "3abc4,5abc6";
alert(reg.exec(str));
alert(str.match(reg));
则 为abc和abc,abc;因为match执行了全局匹配查询;而exec如果没有子表达式只会找到一个匹配的即返回。
5、当表示中含有子表达式的情况:
var reg = new RegExp("a(bc)") ;
var str = "3abc4,5abc6";
alert(reg.exec(str));
alert(str.match(reg));
你会发现两者执行的结果都是:abc,bc;
6、当如果正则表达式对象定义为为全局匹配
var reg = new RegExp("a(bc)","g") ;
var str = "3abc4,5abc6";
alert(reg.exec(str));
alert(str.match(reg));
则两者返回的结果是abc,bc和abc,abc,
总结为:
1、当正则表达式无子表达式,并且定义为非全局匹配时,exec和match执行的结果是一样,均返回第一个匹配的字符串内容;
2、当正则表达式无子表达式,并且定义为全局匹配时,exec和match执行,做存在多处匹配内容,则match返回的是多个元素数组;
3、当正则表达式有子表示时,并且定义为非全局匹配,exec和match执行的结果是一样如上边的第5种情况;
4、当正则表达式有子表示时,并且定义为全局匹配,exec和match执行的结果不一样,此时match将忽略子表达式,只查找全匹配正则表达式并返回所有内容,如上第6种情况;
也就说,exec与全局是否定义无关系,而match则于全局相关联,当定义为非全局,两者执行结果相同。
好细微的差别啊,w3c上是不会有这么细致的介绍的,于是有了正确答案,如下:
var reg = new RegExp("[1-9][0-9]*","g") ;
var str = "第2页 共5页";
var result = str.match(reg);
console.log(result);
现在已经没有研究正则表达式原理,现在只想在网上找过来看看了,下面的都是来自别人的博客。
1.正则表达式 整数
^[1-9]\d* //匹配负整数
^-?[1-9]\d* //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0 //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*) //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0 //匹配非正浮点数(负浮点数 + 0)
2.另外一个版本
"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))" //浮点数
"^[A-Za-z]+" //由26个英文字母的大写组成的字符串
"^[a-z]+" //由数字和26个英文字母组成的字符串
"^\w+" //email地址
"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?/ // 年-月-日
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})" //Emil
"(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?" //电话号码
"^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])
C#正则表达式
图片 src[^>]*[^/].(?:jpg|bmp|gif)(?:\"|\')
中文 ^([\u4e00-\u9fa5]+|[a-zA-Z0-9]+))(像vbscript那样的trim函数)
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
---------------------------------------------------------------------------
以下是例子:
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4E00-\u9FA5]/g,''))"
1.用正则表达式限制只能输入全角字符: onkeyup="value=value.replace(/[^\uFF00-\uFFFF]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF00-\uFFFF]/g,''))"
2.用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^\d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
3.用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))"
4.计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^\x00-\xff]/g,"aa").length;}
5.javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
String.prototype.trim = function()
{
return this.replace(/(^\s*)|(\s*$)/g, "");
}
利用正则表达式分解和转换IP地址:
6.下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function IP2V(ip)
{
re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.2*Math.pow(255,2))+RegExp.4*1
}
else
{
throw new Error("不是一个正确的IP地址!")
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
3.这位博友很细心把html代码也贴出来了
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Test</title>
<script type="text/javascript" language="javascript" src="jquery.js"></script>
<script type="text/javascript" language="javascript" >
function validata(){
if(("#password").val()==""){
document.write("请输入密码");
return false;
}
if(("#email").val()==""){
(document).ready(function() {
// do something here
//隔行换色功能
("p")集合的第3个元素
("#test>p").addClass("over");
//test中的最后一个p附加了样式"out"。
('#faq').find('dd').hide().end().find('dt').click(function()
//选择父级元素
("#display").hover(function(){
.browser.msie){//判断浏览器,若是ie则执行下面的功能
//聚焦
("input[@type=text],textarea,input[@type=password]")
.blur(function(){$(this).css({background:"white",border:"1px solid black"});});
}
});
</script>
<style type="text/css">
.over{
font-size:large;
font-style:italic;
}
.out{
font-size:small;
}
</style>
</head>
<body >
<div id="display">demo</div>
<div id="test">
<p>adfa<a>dfasfa</a>sdfasdf</p>
<p>adfadfasfasdfasdf</p>
<p>adfadfasfasdfasdf</p>
<p>adfadfasfasdfasdf</p>
</div>
<form id="theForm">
isString<div><input type="text" id="username" onblur="isString(this.value)"/></div>
isInteger<div><input type="text" id="password" onblur="isInteger(this.value)"/></div>
isTelephone<div><input type="text" id="telephone" onblur="isTelephone(this.value)"/></div>
isMobile<div><input type="text" id="mobile" onblur="isMobile(this.value)"/></div>
isEmail<div><input type="text" id="email" onblur="isEmail(this.value)"/></div>
isUri<div><input type="text" id="uri" onblur="isUri(this.value)"/></div>
<div><input type="button" value="Validata" onclick="return validata();" /></div>
</form>
</body>
</html>
4. 用JS jquery取float型小数点后两位
1. 最笨的办法
function get()
{
var s = 22.127456 + “”;
var str = s.substring(0,s.indexOf(“.”) + 3);
alert(str);
}
2. 正则表达式效果不错
<scrīpt type=”text/javascrīpt”>
onload = function(){
var a = “23.456322″;
var aNew;
var re = /([0-9]+\.[0-9]{2})[0-9]*/;
aNew = a.replace(re,”$1″);
alert(aNew);
}
</scrīpt>
3. 他就比较聪明了…..
<scrīpt>
var num=22.127456; alert( Math.round(num*100)/100);
</scrīpt>
4.会用新鲜东西的朋友……. 但是需要 IE5.5+才支持。
<scrīpt>
var num=22.127456; alert( num.toFixed(2));
</scrīpt>
参考链接:
http://www.cnblogs.com/freexiaoyu/archive/2008/12/17/1356690.html
http://www.cnblogs.com/qyz123/archive/2007/05/12/743537.html
http://www.cnblogs.com/luluping/archive/2008/05/04/1181434.html
关键字:js验证表单大全,用JS控制表单提交 ,javascript提交表单:
目录:
1:js 字符串长度限制、判断字符长度 、js限制输入、限制不能输入、textarea 长度限制
2.:js判断汉字、判断是否汉字 、只能输入汉字
3:js判断是否输入英文、只能输入英文
4:js只能输入数字,判断数字、验证数字、检测数字、判断是否为数字、只能输入数字
5:只能输入英文字符和数字
6: js email验证 、js 判断email 、信箱/邮箱格式验证
7:js字符过滤,屏蔽关键字
8:js密码验证、判断密码
2.1: js 不为空、为空或不是对象 、判断为空 、判断不为空
2.2:比较两个表单项的值是否相同
2.3:表单只能为数字和"_",
2.4:表单项输入数值/长度限定
2.5:中文/英文/数字/邮件地址合法性判断
2.6:限定表单项不能输入的字符
2.7表单的自符控制
2.8:form文本域的通用校验函数
1. 长度限制
<script>
function test()
{
if(document.a.b.value.length>50)
{
alert("不能超过50个字符!");
document.a.b.focus();
return false;
}
}
</script>
<form name=a onsubmit="return test()">
<textarea name="b" cols="40" wrap="VIRTUAL" rows="6"></textarea>
<input type="submit" name="Submit" value="check">
</form>
2. 只能是汉字
<input onkeyup="value="/oblog/value.replace(/[^\u4E00-\u9FA5]/g,'')">
3." 只能是英文
<script language=javascript>
function onlyEng()
{
if(!(event.keyCode>=65&&event.keyCode<=90))
event.returnvalue=false;
}
</script>
<input onkeydown="onlyEng();">
4. 只能是数字
<script language=javascript>
function onlyNum()
{
if(!((event.keyCode>=48&&event.keyCode<=57)||(event.keyCode>=96&&event.keyCode<=105)))
//考虑小键盘上的数字键
event.returnvalue=false;
}
</script>
<input onkeydown="onlyNum();">
5. 只能是英文字符和数字
<input onkeyup="value="/oblog/value.replace(/[\W]/g,"'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d]/g,''))">
6. 验证油箱格式
<SCRIPT LANGUAGE=javascript RUNAT=Server>
function isEmail(strEmail) {
if (strEmail.search(/^\w+((-\w+)|(\.\w+))*\@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/) != -1)
return true;
else
alert("oh");
}
</SCRIPT>
<input type=text onblur=isEmail(this.value)>
7. 屏蔽关键字(这里屏蔽***和****)
<script language="javascript1.2">
function test() {
if((a.b.value.indexOf ("***") == 0)||(a.b.value.indexOf ("****") == 0)){
alert(":)");
a.b.focus();
return false;}
}
</script>
<form name=a onsubmit="return test()">
<input type=text name=b>
<input type="submit" name="Submit" value="check">
</form>
8. 两次输入密码是否相同
<FORM METHOD=POST ACTION="">
<input type="password" id="input1">
<input type="password" id="input2">
<input type="button" value="test" onclick="check()">
</FORM>
<script>
function check()
{
with(document.all){
if(input1.value!=input2.value)
{
alert("false")
input1.value = "";
input2.value = "";
}
else document.forms[0].submit();
}
}
</script>
够了吧 :)
屏蔽右键 很酷
oncontextmenu="return false" ondragstart="return false" onselectstart="return false"
加在body中
二
2.1 表单项不能为空
<script language="javascript">
<!--
function CheckForm()
{
if (document.form.name.value.length == 0) {
alert("请输入您姓名!");
document.form.name.focus();
return false;
}
return true;
}
-->
</script>
2.2 比较两个表单项的值是否相同
<script language="javascript">
<!--
function CheckForm()
if (document.form.PWD.value != document.form.PWD_Again.value) {
alert("您两次输入的密码不一样!请重新输入.");
document.ADDUser.PWD.focus();
return false;
}
return true;
}
-->
</script>
2.3 表单项只能为数字和"_",用于电话/银行帐号验证上,可扩展到域名注册等
<script language="javascript">
<!--
function isNumber(String)
{
var Letters = "1234567890-"; //可以自己增加可输入值
var i;
var c;
if(String.charAt( 0 )=='-')
return false;
if( String.charAt( String.length - 1 ) == '-' )
return false;
for( i = 0; i < String.length; i ++ )
{
c = String.charAt( i );
if (Letters.indexOf( c ) < 0)
return false;
}
return true;
}
function CheckForm()
{
if(! isNumber(document.form.TEL.value)) {
alert("您的电话号码不合法!");
document.form.TEL.focus();
return false;
}
return true;
}
-->
</script>
2.4 表单项输入数值/长度限定
<script language="javascript">
<!--
function CheckForm()
{
if (document.form.count.value > 100 || document.form.count.value < 1)
{
alert("输入数值不能小于零大于100!");
document.form.count.focus();
return false;
}
if (document.form.MESSAGE.value.length<10)
{
alert("输入文字小于10!");
document.form.MESSAGE.focus();
return false;
}
return true;
}
//-->
</script>
2.5 中文/英文/数字/邮件地址合法性判断
<SCRIPT LANGUAGE="javascript">
<!--
function isEnglish(name) //英文值检测
{
if(name.length == 0)
return false;
for(i = 0; i < name.length; i++) {
if(name.charCodeAt(i) > 128)
return false;
}
return true;
}
function isChinese(name) //中文值检测
{
if(name.length == 0)
return false;
for(i = 0; i < name.length; i++) {
if(name.charCodeAt(i) > 128)
return true;
}
return false;
}
function isMail(name) // E-mail值检测
{
if(! isEnglish(name))
return false;
i = name.indexOf(" at ");
j = name dot lastIndexOf(" at ");
if(i == -1)
return false;
if(i != j)
return false;
if(i == name dot length)
return false;
return true;
}
function isNumber(name) //数值检测
{
if(name.length == 0)
return false;
for(i = 0; i < name.length; i++) {
if(name.charAt(i) < "0" || name.charAt(i) > "9")
return false;
}
return true;
}
function CheckForm()
{
if(! isMail(form.Email.value)) {
alert("您的电子邮件不合法!");
form.Email.focus();
return false;
}
if(! isEnglish(form.name.value)) {
alert("英文名不合法!");
form.name.focus();
return false;
}
if(! isChinese(form.cnname.value)) {
alert("中文名不合法!");
form.cnname.focus();
return false;
}
if(! isNumber(form.PublicZipCode.value)) {
alert("邮政编码不合法!");
form.PublicZipCode.focus();
return false;
}
return true;
}
//-->
</SCRIPT>
2.6 限定表单项不能输入的字符
<script language="javascript">
<!--
function contain(str,charset)// 字符串包含测试函数
{
var i;
for(i=0;i<charset.length;i++)
if(str.indexOf(charset.charAt(i))>=0)
return true;
return false;
}
function CheckForm()
{
if ((contain(document.form.NAME.value, "%><")) || (contain(document.form.MESSAGE.value, "%><")))
{
alert("输入了非法字符");
document.form.NAME.focus();
return false;
}
return true;
}
//-->
</script>
1. 检查一段字符串是否全由数字组成
---------------------------------------
<script language="Javascript"><!--
function checkNum(str){return str.match(/\D/)==null}
alert(checkNum("1232142141"))
alert(checkNum("123214214a1"))
// --></script>
2. 怎么判断是否是字符
---------------------------------------
if (/[^\x00-\xff]/g.test(s)) alert("含有汉字");
else alert("全是字符");
4. 邮箱格式验证
---------------------------------------
//函数名:chkemail
//功能介绍:检查是否为Email Address
//参数说明:要检查的字符串
//返回值:0:不是 1:是
function chkemail(a)
{ var i=a.length;
var temp = a.indexOf('@');
var tempd = a.indexOf('.');
if (temp > 1) {
if ((i-temp) > 3){
if ((i-tempd)>0){
return 1;
}
}
}
return 0;
}
5. 数字格式验证
---------------------------------------
//函数名:fucCheckNUM
//功能介绍:检查是否为数字
//参数说明:要检查的数字
//返回值:1为是数字,0为不是数字
function fucCheckNUM(NUM)
{
var i,j,strTemp;
strTemp="0123456789";
if ( NUM.length== 0)
return 0
for (i=0;i<NUM.length;i++)
{
j=strTemp.indexOf(NUM.charAt(i));
if (j==-1)
{
//说明有字符不是数字
return 0;
}
}
//说明是数字
return 1;
}
6. 电话号码格式验证
---------------------------------------
//函数名:fucCheckTEL
//功能介绍:检查是否为电话号码
//参数说明:要检查的字符串
//返回值:1为是合法,0为不合法
function fucCheckTEL(TEL)
{
var i,j,strTemp;
strTemp="0123456789-()# ";
for (i=0;i<TEL.length;i++)
{
j=strTemp.indexOf(TEL.charAt(i));
if (j==-1)
{
//说明有字符不合法
return 0;
}
}
//说明合法
return 1;
}
7. 判断输入是否为中文的函数
---------------------------------------
function ischinese(s){
var ret=true;
for(var i=0;i<s.length;i++)
ret=ret && (s.charCodeAt(i)>=10000);
return ret;
}
8. 综合的判断用户输入的合法性的函数
---------------------------------------
<script language="javascript">
//限制输入字符的位数开始
//m是用户输入,n是要限制的位数
function issmall(m,n)
{
if ((m<n) && (m>0))
{
return(false);
}
else
{return(true);}
}
9. 判断密码是否输入一致
---------------------------------------
function issame(str1,str2)
{
if (str1==str2)
{return(true);}
else
{return(false);}
}
10. 判断用户名是否为数字字母下滑线
---------------------------------------
function notchinese(str){
var reg=/[^A-Za-z0-9_]/g
if (reg.test(str)){
return (false);
}else{
return(true); }
}
11.验证手机号
function validatemobile(mobile)
{
if(mobile.length==0)
{
alert('请输入手机号码!');
document.form1.mobile.focus();
return false;
}
if(mobile.length!=11)
{
alert('请输入有效的手机号码!');
document.form1.mobile.focus();
return false;
}
var myreg = /^(((13[0-9]{1})|159|153)+\d{8})$/;
if(!myreg.test(mobile))
{
alert('请输入有效的手机号码!');
document.form1.mobile.focus();
return false;
}
}
或者
if(!/^(13[0-9]|14[0-9]|15[0-9]|18[0-9])\d{8}$/i.test(mobile))
或者
代码如下:
function Checkreg()
{
//验证电话号码手机号码,包含153,159号段
if (document.form.phone.value=="" && document.form.UserMobile.value==""){
alert("电话号码和手机号码至少选填一个阿!");
document.form.phone.focus();
return false;
}
if (document.form.phone.value != ""){
var phone=document.form.phone.value;
var p1 = /^(([0\+]\d{2,3}-)?(0\d{2,3})-)?(\d{7,8})(-(\d{3,}))?/ //130?139。至少5位,最多9位
/^153\d{4,8}/ //移动159。至少4位,最多8位
第二个:
复制代码 代码如下:
var Mobile = ("#varPhoneNo").val();
if (Mobile == ""&&Phone == "")
{
alert("手机和固话,请至少填写一项联系方式!");
$("#varMobilePhone").focus();
return;
}
if(Mobile!="")
{
if(!isMobil(Mobile))
{
alert("请输入正确的手机号码!");
$("#varMobilePhone").focus();
return; }
}
//手机号码验证信息
function isMobil(s)
{
var patrn = /(^0{0,1}1[3|4|5|6|7|8|9][0-9]{9}$)/;
if (!patrn.exec(s))
{
return false;
} return true; }
后台验证如下:
if (model.Zip != null)
{
if (!Common.PageValidate.IsValidate(model.Zip,"^\\d{6}$"))
{ Common.WebMessage.showMsg(HttpContext.Current, "请输入正确邮编");
return;
}
}
if (model.PhoneNo != null)
{
if (!Common.PageValidate.IsValidate(model.PhoneNo, "\\d{3}-\\d{8}|\\d{4}-\\d{7}"))
{
Common.WebMessage.showMsg(HttpContext.Current, "请输入正确的电话号码!");
return;
}
}
if (model.MobilePhone != null)
{
if (!Common.PageValidate.IsValidate(model.MobilePhone, "^0{0,1}(13[0-9]|15[3-9]|15[0-2]|18[0-9])[0-9]{8}$"))
{
Common.WebMessage.showMsg(HttpContext.Current, "请输入正确11位有效的手机号码!");
return;
}
}
match 方法
使用正则表达式模式对字符串执行查找,并将包含查找的结果作为数组返回。
stringObj.match(rgExp)
参数
stringObj
必选项。对其进行查找的 String 对象或字符串文字。
rgExp
必选项。为包含正则表达式模式和可用标志的正则表达式对象。也可以是包含正则表达式模式和可用标志的变量名或字符串文字。
其余说明与exec一样,不同的是如果match的表达式匹配了全局标记g将出现所有匹配项,而不用循环,但所有匹配中不会包含子匹配项。
例子1:
function MatchDemo(){ var r, re; // 声明变量。 var s = "The rain in Spain falls mainly in the plain"; re = /(a)in/ig; // 创建正则表达式模式。 r = s.match(re); // 尝试去匹配搜索字符串。 document.write(r); // 返回的数组包含了所有 "ain" 出现的四个匹配,r[0]、r[1]、r[2]、r[3]。 // 但没有子匹配项a。}输出结果:ain,ain,ain,ain
exec 方法
用正则表达式模式在字符串中查找,并返回该查找结果的第一个值(数组),如果匹配失败,返回null。
rgExp.exec(str)
参数
rgExp
必选项。包含正则表达式模式和可用标志的正则表达式对象。
str
必选项。要在其中执行查找的 String 对象或字符串文字。
返回数组包含:
input:整个被查找的字符串的值;
index:匹配结果所在的位置(位);
lastInput:下一次匹配结果的位置;
arr:结果值,arr[0]全匹配结果,arr[1,2...]为表达式内()的子匹配,由左至右为1,2...。
例子2:
代码如下:
function RegExpTest(){
var re = /\w+/g; // 注意g将全文匹配,不加将永远只返回第一个匹配。
var arr;
while((arr = re.exec(src)) !=null){ //exec使arr返回匹配的第一个,while循环一次将使re在g作用寻找下一个匹配。
document.write(arr.index + "-" + arr.lastIndex + ":" + arr + "<br/>");
for(key in arr){
document.write(key + "=>" + arr[key] + "<br/>");
}
document.write("<br/>");
}
}
window.onload = RegExpTest();
输出结果:
0-1:I //0为index,i所在位置,1为下一个匹配所在位置
input=>I love you!
index=>0
lastIndex=>1
0=>I
2-6:love
input=>I love you!
index=>2
lastIndex=>6
0=>love
7-10:you
input=>I love you!
index=>7
lastIndex=>10
0=>you
说 明:根据手册,exec只返回匹配结果的第一个值,比如上例如果不用while循环,将只返回'I'(尽管i空格后的love和you都符合表达式),无 论re表达式用不用全局标记g。但是如果为正则表达式设置了全局标记g,exec 从以 lastIndex 的值指示的位置开始查找。如果没有设置全局标志,exec 忽略 lastIndex 的值,从字符串的起始位置开始搜索。利用这个特点可以反复调用exec遍历所有匹配,等价于match具有g标志。
当然,如果正则表达式忘记用g,而又用循环(比如:while、for等),exec将每次都循环第一个,造成死循环。
exec的输出将包含子匹配项。
例子3:
function execDemo(){
var r, re; // 声明变量。
var s = "The rain in Spain falls mainly in the plain";
re = /[\w]*(ai)n/ig;
r = re.exec(s);
document.write(r + "<br/>");
for(key in r){
document.write(key + "-" + r[key] + "<br/>");
}
}
window.onload = execDemo();
输出:
rain,ai
input-The rain in Spain falls mainly in the plain
index-4
lastIndex-8
0-rain
1-ai
test 方法
返回一个 Boolean 值,它指出在被查找的字符串中是否匹配给出的正则表达式。
rgexp.test(str)
参数
rgexp
必选项。包含正则表达式模式或可用标志的正则表达式对象。
str
必选项。要在其上测试查找的字符串。
说明
test 方法检查字符串是否与给出的正则表达式模式相匹配,如果是则返回 true,否则就返回 false。
例子4:
function TestDemo(re, s){
var s1;
if (re.test(s))
s1 = " 匹配正则式 ";
else
s1 = " 不匹配正则式 ";
return("'" + s + "'" + s1 + "'"+ re.source + "'");
}
window.onload = document.write(TestDemo(/ab/,'cdef'));
输出结果:'cdef' 不匹配正则式 'ab'
注意:test()继承正则表达式的lastIndex属性,表达式在匹配全局标志g的时候须注意。
例子5:
function testDemo(){
var r, re; // 声明变量。
var s = "I";
re = /I/ig; // 创建正则表达式模式。
document.write(re.test(s) + "<br/>"); // 返回 Boolean 结果。
document.write(re.test(s) + "<br/>");
document.write(re.test(s));
}
testDemo();
输出结果:
true
false
true
当第二次调用test()的时候,lastIndex指向下一次匹配所在位置1,所以第二次匹配不成功,lastIndex重新指向0,等于第三次又重新匹配。下例显示test的lastIndex属性:
例子6:
function testDemo(){
var r, re; // 声明变量。
var s = "I";
re = /I/ig; // 创建正则表达式模式。
document.write(re.test(s) + "<br/>"); // 返回 Boolean 结果。
document.write(re.lastIndex); // 返回 Boolean 结果。
}
testDemo();
输出:
true
1
解决方法:将test()的lastIndex属性每次重新指向0,re.lastIndex = 0;
search 方法
返回与正则表达式查找内容匹配的第一个子字符串的位置(偏移位)。
stringObj.search(rgExp)
参数
stringObj
必选项。要在其上进行查找的 String 对象或字符串文字。
rgExp
必选项。包含正则表达式模式和可用标志的正则表达式对象。
说明:如果找到则返回子字符至开始处的偏移位,否则返回-1。
例子6:
function SearchDemo(){
var r, re; // 声明变量。
var s = "The rain in Spain falls mainly in the plain.";
re = /falls/i; // 创建正则表达式模式。
re2 = /tom/i;
r = s.search(re); // 查找字符串。
r2 = s.search(re2);
return("r:" + r + ";r2:" + r2); // 返回 Boolean 结果。
}
document.write(SearchDemo());
输出:r:18;r2:-1
replace 方法
返回根据正则表达式进行文字替换后的字符串的复制。
stringObj.replace(rgExp, replaceText)
参数
stringObj
必选项。要执行该替换的 String 对象或字符串文字。该字符串不会被 replace 方法修改。
rgExp
必选项。为包含正则表达式模式或可用标志的正则表达式对象。也可以是 String 对象或文字。如果 rgExp 不是正则表达式对象,它将被转换为字符串,并进行精确的查找;不要尝试将字符串转化为正则表达式。
replaceText
必选项。是一个String 对象或字符串文字,对于stringObj 中每个匹配 rgExp 中的位置都用该对象所包含的文字加以替换。在 Jscript 5.5 或更新版本中,replaceText 参数也可以是返回替换文本的函数。
说明
replace 方法的结果是一个完成了指定替换的 stringObj 对象的复制。意思为匹配的项进行指定替换,其它不变作为StringObj的原样返回。
ECMAScript v3 规定,replace() 方法的参数 replacement 可以是函数而不是字符串。在这种情况下,每个匹配都调用该函数,它返回的字符串将作为替换文本使用。该函数的第一个参数是匹配模式的字符串。接下来的参数 是与模式中的子表达式匹配的字符串,可以有 0 个或多个这样的参数。接下来的参数是一个整数,声明了匹配在 stringObject 中出现的位置。最后一个参数是 stringObject 本身。结果为将每一匹配的子字符串替换为函数调用的相应返回值的字符串值。函数作参可以进行更为复杂的操作。
例子7:
function f2c(s) {
var test = /(\d+(\.\d*)?)F\b/g; // 说明华氏温度可能模式有:123F或123.4F。注意,这里用了g模式
return(s.replace
(test,
function(Regstr,2,$3,newstrObj) {
return(("<br/>" + Regstr +"<br/>" + (2 +"<br/>" + $3 +"<br/>" + newstrObj +"<br/>" );
}
)
);
}
document.write(f2c("Water: 32.2F and Oil: 20.30F."));
输出结果:
Water: //不与正则匹配的字符,按原字符输出
32.2F //与正则相匹配的第一个字符串的原字符串 Regstr
0.10000000000000142C //与正则相匹配的第一个字符串的第一个子模式匹配的替换结果 2
7 //与正则相匹配的第一个字符串的第一个子匹配出现的偏移量 $3
Water: 32.2F and Oil: 20.30F. //原字符串 newstrObj
and Oil: //不与正则匹配的字符
20.30F //与正则相匹配的第二个字符串的原字符串
-5.85C //与正则相匹配的第二个字符串的第一个子模式与匹配的替换结果
.30 //与正则相匹配的第二个字符串的第二个子模式匹配项的替换结果,这里我们没有将它替换
22 //与正则相匹配的第二个字符串的第一个子匹配出现的偏移量
Water: 32.2F and Oil: 20.30F. //原字符串
. //不与正则匹配的字符
上面的函数参数我们全部用到了。在实际中,我们只须用将xxF替换为xxC,根据要求,我们无须写这么多参数。
例子8:
function f2c(s) {
var test = /(\d+(\.\d*)?)F\b/g; // 说明华氏温度可能模式有:123F或123.4F
return(s.replace
(test,
function(strObj,$1) {
return((($1-32) * 1/2) + "C");
}
)
);
}
document.write(f2c("Water: 32.2F and Oil: 20.30F."));
输出:Water: 0.10000000000000142C and Oil: -5.85C.
更多的应用:
例子9:
function f2c(s) {
var test = /([\d]{4})-([\d]{1,2})-([\d]{1,2})/;
return(s.replace
(test,
function(1,3) {
return(1);
}
)
);
}
document.write(f2c("today: 2011-03-29"));
输出:today: 03/2011
split 方法
将一个字符串分割为子字符串,然后将结果作为字符串数组返回。
stringObj.split([separator[, limit]])
参数
stringObj
必选项。要被分解的 String 对象或文字。该对象不会被 split 方法修改。
separator
可选项。字符串或 正则表达式 对象,它标识了分隔字符串时使用的是一个还是多个字符。如果忽略该选项,返回包含整个字符串的单一元素数组。
limit
可选项。该值用来限制返回数组中的元素个数。
说明
split 方法的结果是一个字符串数组,在 stingObj 中每个出现 separator 的位置都要进行分解。separator 不作为任何数组元素的部分返回。
例子10:
function SplitDemo(){
var s, ss;
var s = "The rain in Spain falls mainly in the plain.";
// 正则表达式,用不分大不写的s进行分隔。
ss = s.split(/s/i);
return(ss);
}
document.write(SplitDemo());
输出:The rain in ,pain fall, mainly in the plain.
js正则表达式之exec()方法、match()方法以及search()方法
先看代码:
var sToMatch = "test, Tes, tst, tset, Test, Tesyt, sTes";
var reEs = /es/gi;
alert(reEs.exec(sToMatch));
alert(sToMatch.match(reEs));
alert(sToMatch.search(reEs));
三个弹出框内容如下:
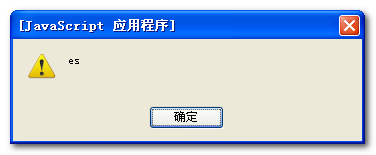
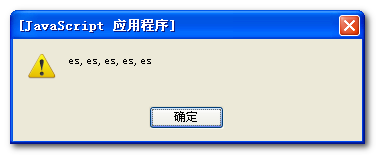
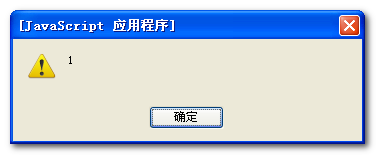
结果分析如下:
1、RegExp的exec()方法,有一个字符串参数,返回一个数组,数组的第一个条目是第一个匹配;其他的是反向引用。所以第一个返回的结果是第一个匹配的值es(不区分大小写)。
2、String对象有一个match()方法,它返回一个包含在字符串中所有匹配的数据。这个方法调用string对象,同时传给它一个RegExp对象。所以第二个弹出语句返回的是所有符合正则表达式的数组。
3、search()的字符串方法与indexOf()有些类似,但是它使用一个RegExp对象而非仅仅一个子字符串。search()方法返回 第一个匹配值的位置。所以第三处弹出的是“1”,即第二个字符就匹配了。注意的是search()方法不支持全局匹配正规表达式(带参数g)。
var tel = /(^[0-9]{3,4}\-[0-9]{7,8})|(^[0-9]{3,8}$)|(^0{0,1}13[0-9]{9}$)|(13\d{9}$)|(15[0135-9]\d{8}$)|(18[267]\d{8}$)/;
var phone = document.getElementById("phoneNumber").value;
if(phone != "" && phone.replace(/\s/g,"")!="" && !(tel.exec(phone))) {
alert("电话号码格式不对,正确格式如下:\n座机号码:区号-座机号码(或)\n手机号码:11位手机号码");
return false;
}
var temp = document.getElementById("email").value;
var myreg = /^([a-zA-Z0-9]+[_|\_|\.]?)*[a-zA-Z0-9]+@([a-zA-Z0-9]+[_|\_|\.]?)*[a-zA-Z0-9]+\.[a-zA-Z]{2,3}$/;
if(temp.value!=""){
if(!myreg.test(temp) && temp !="" && temp.replace(/\s/g,"")!=""){
alert("email格式不正确,请重新输入!");
//email.focus();
return false;
}
}
验证银行卡号
//银行卡号校验
//Description: 银行卡号Luhm校验
//Luhm校验规则:16位银行卡号(19位通用):
// 1.将未带校验位的 15(或18)位卡号从右依次编号 1 到 15(18),位于奇数位号上的数字乘以 2。
// 2.将奇位乘积的个十位全部相加,再加上所有偶数位上的数字。
// 3.将加法和加上校验位能被 10 整除。
function luhmCheck(bankno){
if (bankno.length < 16 || bankno.length > 19) {
//$("#banknoInfo").html("银行卡号长度必须在16到19之间");
return false;
}
var num = /^\d*$/; //全数字
if (!num.exec(bankno)) {
//$("#banknoInfo").html("银行卡号必须全为数字");
return false;
}
//开头6位
var strBin="10,18,30,35,37,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,58,60,62,65,68,69,84,87,88,94,95,98,99";
if (strBin.indexOf(bankno.substring(0, 2))== -1) {
//$("#banknoInfo").html("银行卡号开头6位不符合规范");
return false;
}
var lastNum=bankno.substr(bankno.length-1,1);//取出最后一位(与luhm进行比较)
var first15Num=bankno.substr(0,bankno.length-1);//前15或18位
var newArr=new Array();
for(var i=first15Num.length-1;i>-1;i--){ //前15或18位倒序存进数组
newArr.push(first15Num.substr(i,1));
}
var arrJiShu=new Array(); //奇数位*2的积 <9
var arrJiShu2=new Array(); //奇数位*2的积 >9
var arrOuShu=new Array(); //偶数位数组
for(var j=0;j<newArr.length;j++){
if((j+1)%2==1){//奇数位
if(parseInt(newArr[j])*2<9)
arrJiShu.push(parseInt(newArr[j])*2);
else
arrJiShu2.push(parseInt(newArr[j])*2);
}
else //偶数位
arrOuShu.push(newArr[j]);
}
var jishu_child1=new Array();//奇数位*2 >9 的分割之后的数组个位数
var jishu_child2=new Array();//奇数位*2 >9 的分割之后的数组十位数
for(var h=0;h<arrJiShu2.length;h++){
jishu_child1.push(parseInt(arrJiShu2[h])%10);
jishu_child2.push(parseInt(arrJiShu2[h])/10);
}
var sumJiShu=0; //奇数位*2 < 9 的数组之和
var sumOuShu=0; //偶数位数组之和
var sumJiShuChild1=0; //奇数位*2 >9 的分割之后的数组个位数之和
var sumJiShuChild2=0; //奇数位*2 >9 的分割之后的数组十位数之和
var sumTotal=0;
for(var m=0;m<arrJiShu.length;m++){
sumJiShu=sumJiShu+parseInt(arrJiShu[m]);
}
for(var n=0;n<arrOuShu.length;n++){
sumOuShu=sumOuShu+parseInt(arrOuShu[n]);
}
for(var p=0;p<jishu_child1.length;p++){
sumJiShuChild1=sumJiShuChild1+parseInt(jishu_child1[p]);
sumJiShuChild2=sumJiShuChild2+parseInt(jishu_child2[p]);
}
//计算总和
sumTotal=parseInt(sumJiShu)+parseInt(sumOuShu)+parseInt(sumJiShuChild1)+parseInt(sumJiShuChild2);
//计算Luhm值
var k= parseInt(sumTotal)%10==0?10:parseInt(sumTotal)%10;
var luhm= 10-k;
if(lastNum==luhm){
$("#banknoInfo").html("Luhm验证通过");
return true;
}
else{
$("#banknoInfo").html("银行卡号必须符合Luhm校验");
return false;
}
}
邮箱验证 var reg_email=/^[A-Za-z0-9](([_\.\-]?[a-zA-Z0-9]+)*)@([A-Za-z0-9]+)(([\.\-]?[a-zA-Z0-9]+)*)\.([A-Za-z]{2,})$/;
验证手机号
/*
根据〖中华人民共和国国家标准 GB 11643-1999〗中有关公民身份号码的规定,公民身份号码是特征组合码,由十七位数字本体码和一位数字校验码组成。排列顺序从左至右依次为:六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字校验码。
地址码表示编码对象常住户口所在县(市、旗、区)的行政区划代码。
出生日期码表示编码对象出生的年、月、日,其中年份用四位数字表示,年、月、日之间不用分隔符。
顺序码表示同一地址码所标识的区域范围内,对同年、月、日出生的人员编定的顺序号。顺序码的奇数分给男性,偶数分给女性。
校验码是根据前面十七位数字码,按照ISO 7064:1983.MOD 11-2校验码计算出来的检验码。
出生日期计算方法。
15位的身份证编码首先把出生年扩展为4位,简单的就是增加一个19或18,这样就包含了所有1800-1999年出生的人;
2000年后出生的肯定都是18位的了没有这个烦恼,至于1800年前出生的,那啥那时应该还没身份证号这个东东,⊙﹏⊙b汗...
下面是正则表达式:
出生日期1800-2099 (18|19|20)?\d{2}(0[1-9]|1[12])(0[1-9]|[12]\d|3[01])
身份证正则表达式 /^\d{6}(18|19|20)?\d{2}(0[1-9]|1[12])(0[1-9]|[12]\d|3[01])\d{3}(\d|X)$/i
15位校验规则 6位地址编码+6位出生日期+3位顺序号
18位校验规则 6位地址编码+8位出生日期+3位顺序号+1位校验位
校验位规则 公式:∑(ai×Wi)(mod 11)……………………………………(1)
公式(1)中:
i----表示号码字符从由至左包括校验码在内的位置序号;
ai----表示第i位置上的号码字符值;
Wi----示第i位置上的加权因子,其数值依据公式Wi=2^(n-1)(mod 11)计算得出。
i 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Wi 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2 1
*/
//身份证号合法性验证
//支持15位和18位身份证号
//支持地址编码、出生日期、校验位验证
function IdentityCodeValid(code) {
var city={11:"北京",12:"天津",13:"河北",14:"山西",15:"内蒙古",21:"辽宁",22:"吉林",23:"黑龙江 ",31:"上海",32:"江苏",33:"浙江",34:"安徽",35:"福建",36:"江西",37:"山东",41:"河南",42:"湖北 ",43:"湖南",44:"广东",45:"广西",46:"海南",50:"重庆",51:"四川",52:"贵州",53:"云南",54:"西藏 ",61:"陕西",62:"甘肃",63:"青海",64:"宁夏",65:"新疆",71:"台湾",81:"香港",82:"澳门",91:"国外 "};
var tip = "";
var pass= true;
if(!code || !/^\d{6}(18|19|20)?\d{2}(0[1-9]|1[12])(0[1-9]|[12]\d|3[01])\d{3}(\d|X)$/i.test(code)){
tip = "身份证号格式错误";
pass = false;
}
else if(!city[code.substr(0,2)]){
tip = "地址编码错误";
pass = false;
}
else{
//18位身份证需要验证最后一位校验位
if(code.length == 18){
code = code.split('');
//∑(ai×Wi)(mod 11)
//加权因子
var factor = [ 7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2 ];
//校验位
var parity = [ 1, 0, 'X', 9, 8, 7, 6, 5, 4, 3, 2 ];
var sum = 0;
var ai = 0;
var wi = 0;
for (var i = 0; i < 17; i++)
{
ai = code[i];
wi = factor[i];
sum += ai * wi;
}
var last = parity[sum % 11];
if(parity[sum % 11] != code[17]){
tip = "校验位错误";
pass =false;
}
}
}
if(!pass) alert(tip);
return pass;
}
var c = '130981199312253466';
var res= IdentityCodeValid(c);
// 匹配手机号首尾,以类似“123****8901”的形式输出
'12345678901'.replace(/(\d{3})\d{4}(\d{4})/, '$1****$2');
此段正则匹配字符串中的连续11位数字,替换中间4位为*号,输出常见的隐匿手机号的格式。如果要仅得到末尾4位,则可以改成如下形式:
// 匹配连续11位数字,并替换其中的前7位为*号
'15110280327'.replace(/\d{7}(\d{4})/, '*******$1');
补充注释:正则表达式中的括号即可用于分组,同时也用于定义子模式串,在replace()方法中,参数二中可以使用$n(n为数字)来依次引用模式串中用括号定义的字串。
1****$2')); 隐藏手机号中间4位
常见正则表达式验证
export const regExpConfig = { IDcard: /^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$|^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$/, // 身份证 mobile: /^1([3|4|5|7|8|])\d{9}$/, // 手机号码 telephone: /^(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}$/, // 固定电话 num: /^[0-9]*$/, // 数字 phoneNo: /(^1([3|4|5|7|8|])\d{9}$)|(^(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}$)/, // 电话或者手机 policeNo: /^[0-9A-Za-z]{4,10}$/, // 账号4-10位数字或字母组成 pwd: /^[0-9A-Za-z]{6,16}$/, // 密码由6-16位数字或者字母组成 isNumAlpha: /^[0-9A-Za-z]*$/, // 字母或数字 isAlpha: /^[a-zA-Z]*$/, // 是否字母 isNumAlphaCn: /^[0-9a-zA-Z\u4E00-\uFA29]*$/, // 是否数字或字母或汉字 isPostCode: /^[\d-]*$/i, // 是否邮编 isNumAlphaUline: /^[0-9a-zA-Z_]*$/, // 是否数字、字母或下划线 isNumAndThanZero: /^([1-9]\d*(\.\d+)?|0)$/, // 是否为整数且大于0/^[1-9]\d*(\.\d+)?$/ isNormalEncode: /^(\w||[\u4e00-\u9fa5]){0,}$/, // 是否为非特殊字符(包括数字字母下划线中文) isTableName: /^[a-zA-Z][A-Za-z0-9#$_-]{0,29}$/, // 表名 isInt: /^-?\d+$/, // 整数 isTableOtherName: /^[\u4e00-\u9fa5]{0,20}$/, // 别名 // isText_30: /^(\W|\w{1,2}){0,15}$/, // 正则 // isText_20: /^(\W|\w{1,2}){0,10}$/, // 正则 isText_30: /^(\W|\w{1}){0,30}$/, // 匹配30个字符,字符可以使字母、数字、下划线、非字母,一个汉字算1个字符 isText_50: /^(\W|\w{1}){0,50}$/, // 匹配50个字符,字符可以使字母、数字、下划线、非字母,一个汉字算1个字符 isText_20: /^(\W|\w{1}){0,20}$/, // 匹配20个字符,字符可以使字母、数字、下划线、非字母,一个汉字算1个字符 isText_100: /^(\W|\w{1}){0,100}$/, // 匹配100个字符,字符可以使字母、数字、下划线、非字母,一个汉字算1个字符 isText_250: /^(\W|\w{1}){0,250}$/, // 匹配250个字符,字符可以使字母、数字、下划线、非字母,一个汉字算1个字符 isNotChina: /^[^\u4e00-\u9fa5]{0,}$/, // 不为中文 IDcard: /^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$|^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$/, // 身份证 IDcardAndAdmin: /^(([1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$|^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X))|(admin))$/, // 身份证或者是admin账号 IDcardTrim: /^\s*(([1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3})|([1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X))|(admin))\s*$/, // 身份证 num1: /^[1-9]*$/, // 数字 companyNO: /^qqb_[0-9a-zA-Z_]{1,}$/, // 公司人员账号 imgType: /image\/(png|jpg|jpeg|gif)$/, // 上传图片类型 isChina: /^[\u4e00-\u9fa5]{2,8}$/, isNozeroNumber: /^\+?[1-9]\d*$/, // 大于零的正整数 float: /^\d+(\.?|(\.\d+)?)$/, // 匹配正整数或者小数 或者0.这个特殊值 }
作者:Tyler Ning
出处:http://www.cnblogs.com/tylerdonet/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,如有问题,请微信联系冬天里的一把火


_1257.gif)

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?