
SqlServer 自动化分区方案
本文是我关于数据库分区的方案的一些想法,或许有些问题。仅供大家讨论。SqlServer (SqlServer 2005\SqlServer 2008)实现分区需要在企业版下进行.
SqlServer的分区分为大致有以下个过程:1、创建文件组用以存放数据文件 2、创建文件组用户数据文件 3、创建分区函数 4、创建分区方案 5、在分区方案下创建表
本文是在SqlServer2012 下完成的。
过程:
1、新建数据库,在属性中创建文件以及文件组。如下图:

可以在下图中选择文件组、或者新建文件组用户存放上图中新建的文件:

2、创建分区函数
CREATE PARTITION FUNCTION [partitionById](int) AS RANGE LEFT FOR VALUES (100, 200, 300)
3、创建分区方案
CREATE PARTITION SCHEME [partitionSchemeById] AS PARTITION [partitionById] --分区函数 TO ([FileGroup1], [FileGroup2], [FileGroup3],[FileGroup4])
注意以上分区函数使用的是LEFT ,根据后面的值指明了数据库中如何存放。以上存放方式为:-∞,100],(100,200],(200,300],(300,+∞).此分区方案是依据分区函数
partitionById 创建的。那就是说以上Id的存储区间分别被放在[FileGroup1], [FileGroup2], [FileGroup3],[FileGroup4]文件组的文件中。
4、依据分区方案创建表
CREATE TABLE [dbo].[Account]( [Id] [int] NULL, [Name] [varchar](20) NULL, [Password] [varchar](20) NULL, [CreateTime] [datetime] NULL ) ON partitionSchemeById(Id)
注意:创建表的脚本中需要指明分区方案和分区依据列
查看某分区的数据:
SELECT * FROM [dbo].[Account] WHERE $PARTITION.[partitionById](Id)=1
查询结果如下图:
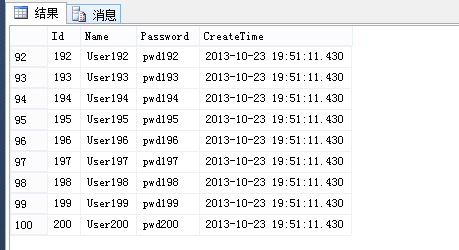
至此,分区似乎已经结束了。但是看看后一个分区里的数据:Id>=400的全部放在了一个数据文件中。这样在有可能瓶颈就发生在了这个分区中。
如果数据不停的增长,希望分区也不断的自动增加。如:每天生成一个新的分区来存放分区新的数据。如到第二天时,新生成一个分区来存放(400,500 ]的数据。
这里我采用了Sql Job的方式来自动产生分区:

DECLARE @maxValue INT, @secondMaxValue INT, @differ INT, @fileGroupName VARCHAR(200), @fileNamePath VARCHAR(200), @fileName VARCHAR(200), @sql NVARCHAR(1000) SET @fileGroupName='FileGroup'+REPLACE(REPLACE(REPLACE(CONVERT(varchar, GETDATE(), 120 ),'-',''),' ',''),':','') PRINT @fileGroupName SET @sql='ALTER DATABASE [Test] ADD FILEGROUP '+@fileGroupName PRINT @sql EXEC(@sql) SET @fileNamePath='C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLINSTANCE\MSSQL\DATA\'+REPLACE(REPLACE(REPLACE(CONVERT(varchar, GETDATE(), 120 ),'-',''),' ',''),':','') +'.NDF' SET @fileName=N'File'+REPLACE(REPLACE(REPLACE(CONVERT(varchar, GETDATE(), 120 ),'-',''),' ',''),':','') SET @sql='ALTER DATABASE [Test] ADD FILE (NAME='''+@fileName+''',FILENAME=N'''+@fileNamePath+''') TO FILEGROUP'+' '+@fileGroupName PRINT @sql PRINT 1 EXEC(@sql) PRINT 2 --修改分区方案,用一个新的文件组用于存放下一新增的数据 SET @sql='ALTER PARTITION SCHEME [partitionSchemeById] NEXT USED'+' '+@fileGroupName EXEC(@sql) --分区架构 PRINT 3 SELECT @maxValue =CONVERT(INT,MAX(value)) FROM SYS.PARTITION_RANGE_VALUES PRV SELECT @secondMaxValue = CONVERT(INT,MIN(value)) FROM ( SELECT TOP 2 * FROM SYS.PARTITION_RANGE_VALUES ORDER BY VALUE DESC ) PRV SET @differ=@maxValue - @secondMaxValue ALTER PARTITION FUNCTION partitionById() --分区函数 SPLIT RANGE (@maxValue+@differ)
这样在计划里指定每天什么时候运行,下图:

参考:http://www.cnblogs.com/lyhabc/articles/2623685.html


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· DeepSeek R1 简明指南:架构、训练、本地部署及硬件要求
· NetPad:一个.NET开源、跨平台的C#编辑器
· 面试官:你是如何进行SQL调优的?