


4. TensorFlow环境构建卷积神经网络
4.1深度学习网络结构
(1)本项目构建的网络层数共6层
(2)第1层第一次卷积核的大小是5*5,深度是32
(3)第2层第一次池化核大小是2*2,移动的步长也是2
(4)第3层第二次卷积核的大小是5*5,深度是64
(5)第4层第二次池化核大小是2*2,移动的步长也是2
(6)第5层第一次全连接输入200行,列是16*16*64的矩阵,输出是512个参数
(7)第6层第二次全连接层,输入是上一层的输出结果经过dropout后的结果,输出77个参数


4.2 卷积、池化及参数定义
(1)导入python的tensorflow包,并且定义输入节点数为一张图片的面积大小64*64,输出的节点有77个,图片的宽高是64,通道是1,类别个数是77。定义第一层卷积层的尺寸大小是5*5,深度是32,第二层的尺寸大小也是5*5,并且深度是64,最后定义第一层全连接层的输出数是512.
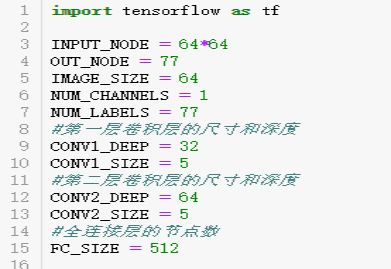
(2)第一层卷积层定义卷积核的大小是5*5,通道是1,深度是32,并且将权重命名为weight,接着定义偏置,深度是32,命名是bias。通过tf.nn.conv2d函数进行池化,第一个参数是input_tensor,是训练集的一部分(每块大小我设置为每次200行),第二个参数conv1_weights,是上面定义的权值。第三个参数是步长strides,它是思维的,第1维和第4维的数必须是1,这是因为卷积层的步长只对矩阵的长和宽有效,中间两个1,表示卷积后不会改变图片的维度,padding的值设置为SAME表示添加全0补充。使用tf.nn.bias_add函数来加入偏置。最后使用tf.nn.relu这个函数作为卷积的激活函数。

(3)第二层池化层,把上面卷积的结果作为输入,核的大小是2*2,移动的步长是2.

(4)第三层是第二次卷积。卷积核的大小是5*5,通道是1,深度是64,并且将权重命名为weight,接着定义偏置,深度是64,命名是bias。通过tf.nn.conv2d函数进行池化,第一个参数是input_tensor,是训练集的一部分(每块大小我设置为每次200行),第二个参数conv1_weights,是上面定义的权值。第三个参数是步长strides,它是思维的,第1维和第4维的数必须是1,这是因为卷积层的步长只对矩阵的长和宽有效,中间两个1,表示卷积后不会改变图片的维度,padding的值设置为SAME表示添加全0补充。使用tf.nn.bias_add函数来加入偏置。最后使用tf.nn.relu这个函数作为卷积的激活函数。

(5)第四层池化层,把上面卷积的结果作为输入,核的大小是2*2,移动的步长是2.

(6)对上面的池化结果,也就是最后一次卷积池化的结果pool2进行扁平化变型。首先获取pool2的维度。接着计算卷积池化后图片的体积大小,也就是节点数或是卷积池化后图片的特征数。最后再把它进行变型。
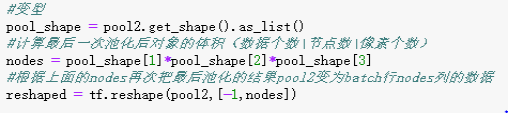
(7)第五层第一次全连接层,首先定义生成全连接层的权值,行数是前面变型结果的列数,权值列数是512.如果正则不为空,则使用tf.add_to_collection('losses',regularizer(fc1_weights))对权值进行正则化处理。接着生成偏置,接下来使用tf.matmul计算上面池化变型结果与权值的乘积再加上偏置。再把这个加上偏置,最后使用tf.nn.relu激活函数进行预测,如果是train的话,那么就调用tf.nn.dropout函数进行去掉部分数据,也是为了防止算法过拟合,设置的概率是0.5.

(8)第六层第一次全连接层,把上一层的输出当成是这一层的输入,首先定义生成全连接层的权值,行数是前面变型结果的列数,权值列数是77.如果正则不为空,则使用tf.add_to_collection('losses',regularizer(fc1_weights))对权值进行正则化处理。接着生成偏置,接下来使用tf.matmul计算上面池化变型结果与权值的乘积再加上偏置。再把这个加上偏置,最后使用tf.nn.relu激活函数进行预测,最后把这个预测结果返回。

4.3 训练过程及结果
(1)导入需要用到的python包

(2)将训练数据集进行变成四维的。把标签变成二维的,之后再改变成one hot编码。

(3)定义运行所需参数,batch_size表示每次取200行数据进行卷积和池化。n_classes表示输出的类别数目。epochs表示把所有的数据重复循环执行的次数,learning_rate表示学习率。batch_num表示训练数据集分多少次执行完。dropout表示去掉一些数据,概率是0.75.

(4)定义每次用于训练的x,提取与x对应的标签y。

(5)调用上面定义的inference方法,把训练数据x传给函数,并且得到预测的结果pred。最小化误差,并且对最小化求均值。接着使用AdamOptimizer进行优化。接着使用tf.equal函数求预测的值和真实值的对比情况。根据前面的计算结果再求训练的准确率accuracy。对tensorflow的变量进行实例化对象。定义训练开始时间计时。

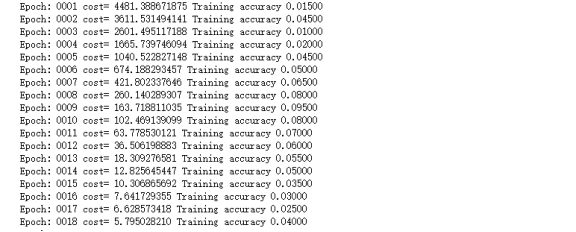
(6)取得tf.Session()的会话,别名是sess,run上面变量实例化对象init,第一个外循环是将所有的训练数据执行多少遍,这里设置是20遍。里面for循环是多少次将一次全部的训练数据执行完。这里设置是上面的batch_num=int(np.shape(X)[0]/batch_size)次。这个训练里面start是开始取训练数据的下标,end是结束下标,每次取的条数是batch_size,也就是上面设置的200。接下来就是将start:end这段数据通过字典赋给变量x,y。然后也更新最小化数值和准确率。并且打印每次的损失,和准确率。

部分输出:

(7)最后打印一共执行的时间。

4.4 参数调整及优化
1、改变神经网络的搭建方式(增加卷积、池化、全连接的层数)
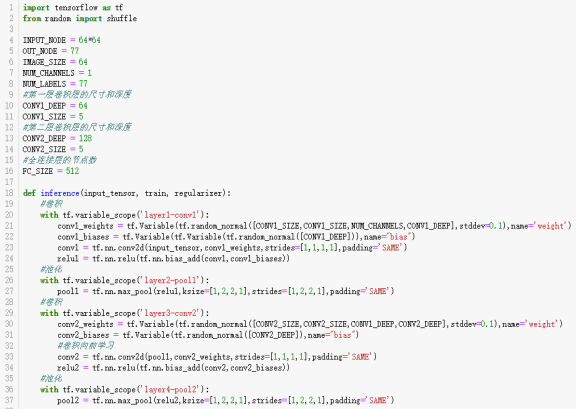



怀疑第一次执行结果的准确率低的原因是由于欠拟合造成的,所以上面的代码把神经网络的卷积层加到了4层,池化层也加到了4层,最后的全连接层加到了3层,比第一次共多处了5层,下面是运行结果:
可以看到结果还是很不理想。所以不是由于欠拟合造成的。
1、接着我在第一次代码的基础上,再次完善,把数据集由原来的学习率改成:1e-4也就是约等于0.0001,并且改变神经网络的搭建方式:


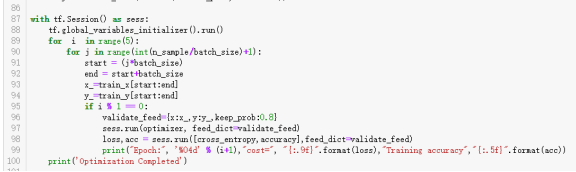
再次改变神经网络搭建方式后,卷积层2层,池化层2层。全连接层也是2层,使用字典的形式来取得神经网络各个层次的权值、偏置以及图片处理过程的深度等参数。运行的结果如下:
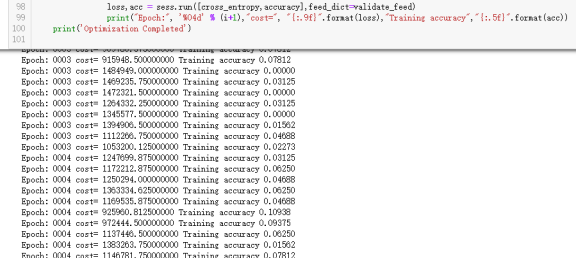
苦苦等了代码跑了4次,结果还是不行……但也说明问题不在我搭建的神经网络上,换了一种方式和学习率,结果还是低准确率。
1、接下来耐下心静下来,再次重新搭建自己的神经网络,各个神经网络的层次还是和上一次的一样,搭建的方式却不再是通过字典和方法来获取相关的参数了,由于这次是痛定思痛搭建神经网络层,几乎没句代码也都加上了注释说明,所以参数就不再另外使用文字描述了。代码如下:

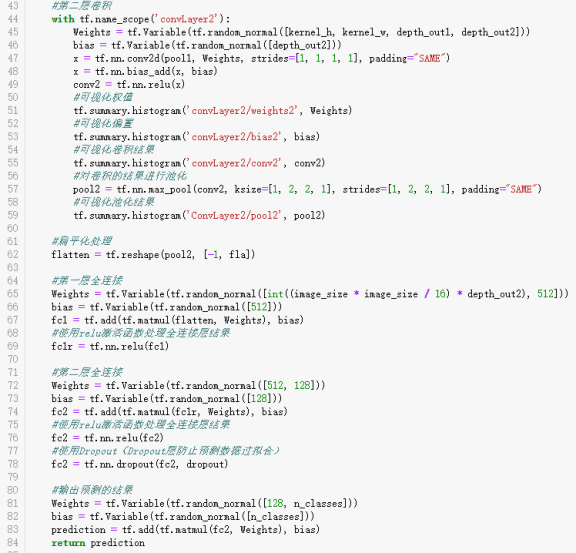

运行的结果如下:
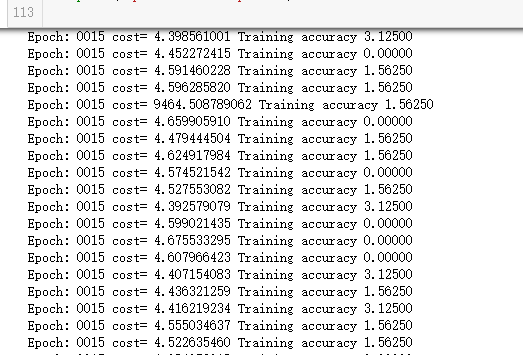
等待了8个多小时,执行到了15次,还有5次代码就结束运行了,但感觉准确率提高的希望很渺茫,就又强制暂停执行了。
