peewee:精致小巧的orm,某些场景下可以成为sqlalchemy的一个很好的替代品
楔子
下面我们来了解一下python中的orm:peewee和peewee_async,peewee是python的一个比较精简的orm,源码是一个大概七千多行的py文件。是的,peewee只有一个py文件。至于peewee_async,从名字上也能看出这是基于peewee的一个异步orm。所以介绍peewee_async之前我们需要先介绍一下peewee
下面来安装peewee_async,直接pip install peewee_async即可,会自动安装peewee。
peewee
我们来看看如何使用peewee,peewee是一个比较精简的orm,目前只能适配sqlite、MySQL、PostgreSQL,至于Oracle和SQLserver则不支持。
我们这里以PostgreSQL数据库为例,当然orm并不具备直接和数据库通信的功能,它需要依赖于底层驱动,python连接PostgreSQL使用的模块是psycopg2,直接pip install psycopg2_binary即可。
如果你用的MySQL,那么需要pip install pymysql
定义Model并映射成表
下面我们来看看如何使用peewee定义一个Model,并映射成数据中的表。
import peewee
# 第一个参数是我们要连接到哪个数据库,剩余的参数就无需多说了
db = peewee.PostgresqlDatabase("postgres",
host="localhost",
port=5432,
user="postgres",
password="zgghyys123")
"""
如果是sqlite:那么使用peewee.SqliteDatabase
如果是mysql: 那么使用peewee.MySQLDatabase
"""
# 参数我们来定义Model, 首先要继承自peewee.Model
class Girl(peewee.Model):
pk = peewee.IntegerField(primary_key=True, verbose_name="主键")
name = peewee.CharField(max_length=200, verbose_name="姓名")
where = peewee.CharField(max_length=200, verbose_name="住址")
class Meta:
# 绑定上面的数据库实例
database = db
# 设置表名
table_name = "girl"
# 设置schema, 当然对于PostgreSQL来说,不设置默认为public
schema = "public"
if __name__ == '__main__':
# 调用db.create_tables即可将上面的模型映射成表
db.create_tables([Girl])
# 除此之外,还可以调用db.is_closed()查看连接是否关闭
print(db.is_closed()) # False
# 也可以手动关闭连接
db.close()
print(db.is_closed()) # True
执行上面代码之后会发现数据库中多出一张名为girl的表,使用起来还是比较简单的。
peewee中的Field
我们看到数据库表中的字段对应peewee中的Field,那么在peewee中都有哪些Field呢?这里介绍几个常用的,其实很多都是类似的,比如:IntegerField、BigIntegerField、SmallIntegerField这几个明显就是一类的。
IntegerField
针对整型字段,里面常用参数如下:
null=False:是否允许为空index=False:是否为索引unique=False:是否要求唯一column_name=None:映射表中的字段名,如果为None,那么采用变量名当做字段名default=None:默认值primary_key=False:是否为主键constraints=None:约束verbose_name:字段注释
这个Integer本身是没有__init__函数的,它是继承自Field
AutoField
如果是AutoField,那么对应字段必须为主键,并且自动会自增。我们上面使用IntegerField设置的主键并不是自增的。
peewee.AutoField() # 创建的默认就是自增主键了
FloatField
和IntegerField的参数一致。
DecimalField
和IntegerField的参数一致,并且还可以指定精度,也就是数据库里面的numberic
CharField
和IntegerField的参数一致,并且还多了一个max_length,也就是最大长度。
TextField
和CharField的参数一致,没有长度限制。
UUIDField
继承自Field,和IntegerField参数一样。
DateTimeField、DateField、TimeField
对应:年月日时分秒、年月日、时分秒,也继承自Field
TimestampField
时间戳,Unix到指定之间经过的秒数,继承自Field
IPField
针对IP
BooleanField
针对布尔类型
ForeignKeyField
针对外键
常用的Field如上,至于peewee提供的其他Field,可以去源码中查看。
主键和约束
关于主键和约束,我们知道可以在Field中设置,但是联合主键呢?
class Girl(peewee.Model):
pk = peewee.IntegerField(primary_key=True, verbose_name="主键")
name = peewee.CharField(primary_key=True, max_length=200, verbose_name="姓名")
where = peewee.CharField(max_length=200, verbose_name="住址")
如果给多个字段设置主键,那么它们不会变成联合主键,而是会报错:ValueError: over-determined primary key Girl.
解决办法如下:
class Girl(peewee.Model):
pk = peewee.IntegerField(verbose_name="主键")
name = peewee.CharField(primary_key=True, max_length=200, verbose_name="姓名")
where = peewee.CharField(max_length=200, verbose_name="住址")
class Meta:
# 通过peewee.CompositeKey进行设置
# 里面以字符串的形式直接传入设置变量名即可
# 注意:是变量名,并且以字符串的形式
primary_key = peewee.CompositeKey("pk", "name")
# 除此之外还可以设置约束, 当然约束也可以在Field中设置
constraints = [peewee.SQL("CHECK(length(name) > 3)"),
peewee.SQL("CHECK(pk > 3)")]
此时pk和name就是说联合主键了,并且要求name的长度大于3个字符,pk的值大于3。
关于自增还可以这么设置,比如关闭自增:User._meta.auto_increment = False
另外,我们这里创建表的时候定义了主键,但如果我们没有定义主键的话,那么peewee会自动帮我们加上一个名为id的自增主键,并且我们还可以通过Girl.id进行获取。但如果我们定义了主键,那么peewee就不会再帮我们自动加主键了。
表的增删改查
增加记录
下面我们来看看如何使用peewee给表增加记录
import peewee
db = peewee.PostgresqlDatabase("postgres",
host="localhost",
port=5432,
user="postgres",
password="zgghyys123")
# 参数我们来定义Model, 首先要继承自peewee.Model
class Girl(peewee.Model):
pk = peewee.AutoField(verbose_name="自增主键")
name = peewee.CharField(max_length=200, verbose_name="姓名")
where = peewee.CharField(max_length=200, verbose_name="住址")
class Meta:
database = db
table_name = "girl"
if __name__ == '__main__':
db.create_tables([Girl])
# 增加记录有以下几种方式
g1 = Girl()
g1.name = "古明地觉"
g1.where = "东方地灵殿"
# 或者
g2 = Girl(name="博丽灵梦", where="博丽神社")
# 然后一定要save,否则记录不会进入到表中
g1.save()
g2.save()
此时查看数据库,会发现数据库的表girl中多了两条记录。
或者这样插入记录也是可以的
# 直接调用Girl.create即可
Girl.create(name="芙兰朵露", where="红魔馆")
Girl.create(name="蕾米莉亚", where="红魔馆")
会发现数据库中又多了两条记录
但问题是,我们这里的记录是一条一条插入的,效率上不够好,可不可以多条记录一块插入到数据库呢?
# 我们可以调用insert和insert_many来插入记录
# 这两者使用上没有什么区别,都可以接收一个字典插入一条记录
# 接收多个字典组成的列表,插入多条记录。
# 但是调用之后一定要再调用一下execute,才会进入到数据库中
Girl.insert([{"name": "帕秋莉·诺蕾姬", "where": "红魔馆"},
{"name": "西行寺幽幽子", "where": "白玉楼"}]).execute()
Girl.insert({"name": "八意永琳", "where": "辉夜永远亭"}).execute()
Girl.insert_many({"name": "雾雨魔理沙", "where": "魔法森林"}).execute()
Girl.insert_many([{"name": "红美铃", "where": "红魔馆"}]).execute()
此外,我们还可以设置事务。
with db.transaction():
Girl.create(pk=10, name="xx", where="xx")
Girl.create(pk=10, name="xx", where="xx")
# 或者
with db.atomic():
Girl.create(pk=10, name="xx", where="xx")
Girl.create(pk=10, name="xx", where="xx")
显然pk重复了,因此无论哪种方式,两条记录最终都会插入失败。
当然如果失败了,我们最好要记得回滚,在sqlalchemy中你应该遇到过这么个错误。就是使用session操作数据库的时候,如果失败不会滚的话,那么这个错误会一直持续到你连接断开为止。因此如果操作失败,一定要记得回滚。
不过当我们使用with db.atomic或者with db.transaction的时候,失败了peewee会自动帮我们进行回滚。这一点不需要我们手动做了,当然如果是我们在不使用atomic、transaction,并且需要多次操作数据库的时候,失败了要记得回滚。
try:
Girl.insert([{"pk": 10, "name": "xx", "where": "xxx"},
{"pk": 10, "name": "xx", "where": "xxx"}]).execute()
except Exception:
db.rollback()
orm的insert插入多条记录的时候,整体是具备事务性质的,最终两条记录都插入失败。但是,插入失败了,一定要回滚。不过对于insert来说,也建议使用with db.atomic()或者with db.transaction()的方式。
peewee插入记录的几种方式我们就介绍到这里,支持的方式还是不少的。
删除记录
下面来看看删除记录,删除记录非常简单。
# Girl.delete().execute()相当于删除全部记录
# 如果删除指定条件的记录的话,那么可以通过where指定
# where中怎么进行筛选,我们会在 "查询记录" 的时候详细介绍
# 查询、更新、删除,它们的where都是一样的
print(
Girl.delete().where(Girl.name.in_(["红美铃", "八意永琳"])).execute()
) # 2
# 上面返回2,表示成功删除两条记录
# 我们说不加where表示全部删除
print(Girl.delete().execute()) # 7
此时记录就全没了,我们重新创建一下吧,不然下面没有数据演示了。
修改记录
修改记录也没有什么难度,我们来看一下。
# update里面直接通过关键字参数的方式修改
print(Girl.update(where="东方红魔馆").where(Girl.where == "红魔馆").execute()) # 4
print(Girl.update(where="红魔馆").where(Girl.where == "东方红魔馆").execute()) # 4
# 返回4表示成功修改4条
查询记录
重头戏来了,也不知道谁的头这么重,我们用的最多的应该就是查询了,下面来看看peewee都支持我们怎么查询。而查询的关键就在where上面,当然我们表里面也有个字段叫where,两个没啥关系,不要搞混了。
一种简单的方式,调用Model的get方法,会返回满足条件的第一条记录。
res = Girl.get(Girl.where == "红魔馆")
# 返回的是一个Model对象,这个3是什么?
# 直接打印的话,显示的是记录的主键的值
print(res, type(res)) # 3 <Model: Girl>
# 获取其它属性
print(res.name, res.where) # 芙兰朵露 红魔馆
如果是根据主键获取的话,还有如下两种简单的形式:
res = Girl.get_by_id(3)
print(res, type(res)) # 3 <Model: Girl>
print(res.name, res.where) # 芙兰朵露 红魔馆
res = Girl[3]
print(res, type(res))
print(res.name, res.where) # 芙兰朵露 红魔馆
# 注意:通过get_by_id获取的话,如果记录不存在会报错
我们看到如果是根据主键获取的话,那么可以直接通过get_by_id,或者直接通过字典的方式。至于为什么可以通过字典的方式,想都不用想,肯定是内部实现了__getitem__方法。
查看源码的话,会发现peewee.Model继承的父类中实现了__getitem__,底层还是调用了get_by_id
上面只是获取单条记录,如果是多条的话使用select。
# 如果select里面不指定字段,那么是获取全部字段
res = Girl.select(Girl.name, Girl.where).where(Girl.pk > 5)
print(res) # SELECT "t1"."name", "t1"."where" FROM "girl" AS "t1" WHERE ("t1"."pk" > 5)
print(type(res)) # <class 'peewee.ModelSelect'>
# 上面的res返回的是一个<class 'peewee.ModelSelect'>,上面的语句不会立即执行
# 而是一个懒执行,类似于spark里面的transform,或者python里面的迭代器
# 像get,get_by_id等方法,使用之后会立即组成sql语句然后去查询
# 我们可以调用res.sql查看SQL语句
print(res.sql()) # ('SELECT "t1"."name", "t1"."where" FROM "girl" AS "t1" WHERE ("t1"."pk" > %s)', [5])
# 当我们调用for循环迭代的时候,才会执行,如何实现?实际上是底层实现了迭代协议
for _ in res:
print(_, type(_), _.name, _.where)
"""
None <Model: Girl> 西行寺幽幽子 白玉楼
None <Model: Girl> 八意永琳 辉夜永远亭
None <Model: Girl> 雾雨魔理沙 魔法森林
None <Model: Girl> 红美铃 红魔馆
"""
# 返回的仍然是一个Model对象,如果打印的话默认打印的还是主键的值
# 但是我们这里没有选择主键,因此打印的是None
# 如果我们调用get的话,也可以返回第一条满足条件的记录
first = res.get()
# 这里打印None不要慌,默认显示的主键的值,但是没有选择主键所以为None
print(first) # None
print(first.name, first.where) # 西行寺幽幽子 白玉楼
除了使用for循环,还可以这么做
res = Girl.select(Girl.name, Girl.where).where(Girl.pk > 5)
# 可以调用list将其全部打印出来
print(list(res)) # [<Girl: None>, <Girl: None>, <Girl: None>, <Girl: None>]
# 使用Girl.select().where()这种方式获取的结果永远可以当成一个列表来使用
# 因此可以通过索引获取单个记录
some = res[3]
print(some) # None
print(some.name, some.where) # 红美铃 红魔馆
还没完,我们还可以得到一个字典
# 调用dicts之后得到的依旧是<class 'peewee.ModelSelect'>对象
# 打印的时候会打印一条SQL语句
res = Girl.select(Girl.name, Girl.where).where(Girl.pk > 5).dicts()
print(res) # SELECT "t1"."name", "t1"."where" FROM "girl" AS "t1" WHERE ("t1"."pk" > 5)
print(type(res)) # <class 'peewee.ModelSelect'>
# 但是当我们调用list、或者for循环的时候,打印就是一个字典了
print(list(res))
"""
[{'name': '西行寺幽幽子', 'where': '白玉楼'},
{'name': '八意永琳', 'where': '辉夜永远亭'},
{'name': '雾雨魔理沙', 'where': '魔法森林'},
{'name': '红美铃', 'where': '红魔馆'}]
"""
# 通过索引或者切片获取
print(res[1: 3]) # [{'name': '八意永琳', 'where': '辉夜永远亭'}, {'name': '雾雨魔理沙', 'where': '魔法森林'}]
或者得到一个tuple对象、或者namedtuple对象
res = Girl.select(Girl.name, Girl.where).where(Girl.pk > 5).tuples()
print(list(res))
"""
[('西行寺幽幽子', '白玉楼'), ('八意永琳', '辉夜永远亭'),
('雾雨魔理沙', '魔法森林'), ('红美铃', '红魔馆')]
"""
print(res[1: 3]) # [('八意永琳', '辉夜永远亭'), ('雾雨魔理沙', '魔法森林')]
# 或者namedtuple
res = Girl.select(Girl.name, Girl.where).where(Girl.pk > 5).namedtuples()
print(list(res))
"""
[Row(name='西行寺幽幽子', where='白玉楼'),
Row(name='八意永琳', where='辉夜永远亭'),
Row(name='雾雨魔理沙', where='魔法森林'),
Row(name='红美铃', where='红魔馆')]
"""
支持的结果种类还是蛮多的,下面我们来看看peewee都支持哪些where操作
-
alias:起别名# 起别名,当然这是在select里面的 res = Girl.select(Girl.where.alias("WHERE")).where(Girl.where == "红魔馆") # 起完别名就只能用别名获取了 print(res[0].where, res[0].WHERE) # None 红魔馆 -
cast:改变类型# 改变类型, 这也是在select里面, 但是类型要写PostgreSQL的类型 res = Girl.select(Girl.pk.cast("text")) print(res[0].pk, res[0].pk == "1") # 1 True -
is_null:查询为NULL的# 查找name为null的 res = Girl.select().where(Girl.name.is_null()) print(len(list(res))) # 0 # 查找name不为null的 res = Girl.select().where(Girl.name.is_null(False)) print(len(list(res))) # 9 -
contains:查询包含某个字符串的# 查找name包含"莉"的记录, 相当于 name like '%莉%' res = Girl.select().where(Girl.name.contains("莉")) print([_.name for _ in res]) # ['蕾米莉亚', '帕秋莉·诺蕾姬'] -
startswith:查询以某个字符串开始的# 查找where以"红"开头的, 相当于 where like '红%' res = Girl.select().where(Girl.where.startswith("红")) print([_.where for _ in res]) # ['红魔馆', '红魔馆', '红魔馆', '红魔馆'] -
endswith:查询以某个字符串结尾的# 查找where以"楼"结尾的, 相当于 where like '%楼' res = Girl.select().where(Girl.where.endswith("楼")) print([(_.name, _.where) for _ in res]) # [('西行寺幽幽子', '白玉楼')] -
between:查询位于两个值之间的# 查找pk在3到6之间的 res = Girl.select().where(Girl.pk.between(3, 6)) print([(_.pk, _.name) for _ in res]) """ [(3, '芙兰朵露'), (4, '蕾米莉亚'), (5, '帕秋莉·诺蕾姬'), (6, '西行寺幽幽子')] """ # 以上等价于Girl.pk[slice(3, 6)],注意传入的切片是包含结尾的 # 当然这种方式底层也是调用的between res = Girl.select().where(Girl.pk[slice(3, 6)]) print([(_.pk, _.name) for _ in res]) """ [(3, '芙兰朵露'), (4, '蕾米莉亚'), (5, '帕秋莉·诺蕾姬'), (6, '西行寺幽幽子')] """ # 既然可以传入一个切片,也可以传入普通的整型 res = Girl.select().where(Girl.pk[3]) # 等价于Girl.select().where(Girl.pk == 3) print([(_.pk, _.name) for _ in res]) # [(3, '芙兰朵露')] -
in_:查找位于指定的多个记录之中的,反之是not_inres = Girl.select().where(Girl.pk.in_([1, 3, 5])) print([(_.pk, _.name) for _ in res]) # [(1, '古明地觉'), (3, '芙兰朵露'), (5, '帕秋莉·诺蕾姬')] # 或者还可以这么写 res = Girl.select().where(Girl.pk << [1, 3, 5]) print([(_.pk, _.name) for _ in res]) # [(1, '古明地觉'), (3, '芙兰朵露'), (5, '帕秋莉·诺蕾姬')] -
regexp、iregexp:正则,前者大小写敏感,后者大小写不敏感# 查找name只有四个字符的,这里的正则要遵循对应数据的正则语法 res = Girl.select().where(Girl.name.regexp(r"^.{4}$")) print([(_.pk, _.name) for _ in res]) """ [(1, '古明地觉'), (2, '博丽灵梦'), (3, '芙兰朵露'), (4, '蕾米莉亚'), (7, '八意永琳')] """
上面我们介绍了一些常见的where操作,当然也包含select。当然PostgreSQL里面还有concat、substring等等,这些使用peewee该如何实现呢?在peewee中有一个fn,通过fn来调用这些函数。
# 通过fn调用的函数要大写
res = Girl.select(peewee.fn.CONCAT(Girl.name, "xx")).where(Girl.pk > 5)
print([_.name for _ in res]) # [None, None, None, None]
# 但是我们看到的全是None,这是什么鬼?
# 因为我们使用CONCAT之后,这个字段名就不叫name了,而是叫concat
print([_.concat for _ in res]) # ['西行寺幽幽子xx', '八意永琳xx', '雾雨魔理沙xx', '红美铃xx']
# 因此这种方式不是很友好,因此解决办法之一就是起一个别名
res = Girl.select(peewee.fn.CONCAT(Girl.name, "xx").alias("name")).where(Girl.pk > 5)
print([_.name for _ in res]) # ['西行寺幽幽子xx', '八意永琳xx', '雾雨魔理沙xx', '红美铃xx']
# 另一个办法就是通过字典或者元组的方式
res = Girl.select(peewee.fn.CONCAT(Girl.name, "xx")).where(Girl.pk > 5).dicts()
print(list(res))
"""
[{'concat': '西行寺幽幽子xx'},
{'concat': '八意永琳xx'},
{'concat': '雾雨魔理沙xx'},
{'concat': '红美铃xx'}]
"""
# 再比如substr
res = Girl.select(peewee.fn.SUBSTR(Girl.name, 1, 2)).where(Girl.pk > 5).tuples()
print(list(res)) # [('西行',), ('八意',), ('雾雨',), ('红美',)]
不仅是这些函数,包括数学相关的函数,一些常用的聚合函数都是通过fn来调用,比如保留两位小数:peewee.fn.ROUND、求次数fn.COUNT等等。
多条件筛选
res = Girl.select().where((Girl.pk > 5) & (Girl.where == "红魔馆")).tuples()
print(list(res)) # [(9, '红美铃', '红魔馆')]
# 只有一个满足条件的,&代表and、|代表or、~代表not
# 记得每个条件之间使用小括号括起来,因为优先级的问题
# 我们上面的例子如果不使用小括号括起来的话,那么5会先和Girl.where进行&运算,这显然不是我们想要的结果
returning
returning语句是专门针对insert、update、delete的,表示在完成相应操作的时候返回一个值,我们看一下。
res = Girl.update(name="古明地恋").where(Girl.where == "东方地灵殿").returning(Girl.name).execute()
# 更新之后返回更新的name
print([_.name for _ in res])
# 返回多个也可以
res = Girl.update(name="古明地恋").where(Girl.where == "东方地灵殿").returning(Girl.name, Girl.where).execute()
print([(_.name, _.where) for _ in res]) # [('古明地恋', '东方地灵殿')]
# 删除数据也是可以的
res = Girl.delete().where(Girl.where == "东方地灵殿").returning(Girl.name, Girl.pk).execute()
print([(_.name, _.pk) for _ in res]) # [('古明地恋', 1), ('古明地恋', 3)]
# 当然插入也是如此
res = Girl.insert([{"name": "帕秋莉·诺蕾姬", "where": "红魔馆"},
{"name": "西行寺幽幽子", "where": "白玉楼"}]).returning(Girl.name, Girl.where).execute()
print([(_.name, _.where) for _ in res]) # [('帕秋莉·诺蕾姬', '红魔馆'), ('西行寺幽幽子', '白玉楼')]
# 插入单条数据也是如此,同样需要使用循环
res = Girl.insert({"name": "帕秋莉·诺蕾姬", "where": "红魔馆"}
).returning(Girl.name).execute()
print([_.name for _ in res]) # ['帕秋莉·诺蕾姬']
# 如果不指定returning,那么对于insert来说返回的是主键
res = Girl.insert({"name": "帕秋莉·诺蕾姬", "where": "红魔馆"}
).execute()
# 直接打印即可
print(res) # 22
# 如果是插入多条数据
res = Girl.insert([{"name": "帕秋莉·诺蕾姬", "where": "红魔馆"},
{"name": "帕秋莉·诺蕾姬", "where": "红魔馆"}]).execute()
print(list(res)) # [(27,), (28,)]
distinct、nullif、coalesce
下面来看看上面这三个函数怎么实现,不过既然是函数,就可以通过fn来调用。
# 通过fn调用的函数要大写
res = Girl.select(peewee.fn.DISTINCT(Girl.where)).tuples()
print(list(res))
"""
[('白玉楼',), ('魔法森林',), ('博丽神社',),
('东方地灵殿',), ('红魔馆',), ('辉夜永远亭',)]
"""
# 我们看到实现了去重的效果
# 除此之外我们还可以这么做
res = Girl.select(Girl.where).distinct().tuples()
print(list(res))
"""
[('白玉楼',), ('魔法森林',), ('博丽神社',),
('东方地灵殿',), ('红魔馆',), ('辉夜永远亭',)]
"""
# 得到的结果是一样的
# nullif的作用就是,如果两个值一样,那么返回null
# 不一样返回第一个值,比如为了防止除零错误,就可以用 a / nullif(b, 0)
# 这样当b为0的时候就不会报错了,而是返回null
res = Girl.select(peewee.fn.NULLIF(Girl.where, "红魔馆"), Girl.where).tuples()
print(list(res))
"""
[('东方地灵殿', '东方地灵殿'), ('博丽神社', '博丽神社'),
(None, '红魔馆'), (None, '红魔馆'), (None, '红魔馆'),
('白玉楼', '白玉楼'), ('辉夜永远亭', '辉夜永远亭'),
('魔法森林', '魔法森林'), (None, '红魔馆')]
"""
# coalesce的作用是,里面传入多个值,返回一个不为空的值
# 如果都为空,那么就只能是空了
res = Girl.select(peewee.fn.coalesce(None, "红魔馆", None)).tuples()
print(list(res))
"""
[('红魔馆',), ('红魔馆',), ('红魔馆',), ('红魔馆',),
('红魔馆',), ('红魔馆',), ('红魔馆',), ('红魔馆',), ('红魔馆',)]
"""
group by和having
在做聚合的时候需要使用到group by和having,这两个就一起说吧。
res = Girl.select(peewee.fn.COUNT(Girl.where), Girl.where)\
.group_by(Girl.where).tuples() # 如果是根据多个字段group by,那么就直接写多个字段即可
print(list(res))
"""
[(1, '白玉楼'), (1, '魔法森林'),
(1, '博丽神社'), (1, '东方地灵殿'),
(4, '红魔馆'), (1, '辉夜永远亭')]
"""
# 加上having的话
res = Girl.select(peewee.fn.COUNT(Girl.where), Girl.where) \
.group_by(Girl.where).having(peewee.fn.COUNT(Girl.where) > 1).tuples()
print(list(res)) # [(4, '红魔馆')]
# 这里选择Girl.where出现次数大于1的
# 如果having里面需要多个条件,那么和多条件筛选一样,使用&、|、~
order by
res = Girl.select(peewee.fn.COUNT(Girl.where), Girl.where)\
.group_by(Girl.where).order_by(peewee.fn.COUNT(Girl.where)).tuples()
print(list(res))
"""
[(1, '白玉楼'), (1, '魔法森林'), (1, '博丽神社'),
(1, '东方地灵殿'), (1, '辉夜永远亭'), (4, '红魔馆')]
"""
# 默认是升序的,如果降序呢?
res = Girl.select(peewee.fn.COUNT(Girl.where), Girl.where) \
.group_by(Girl.where).order_by(peewee.fn.COUNT(Girl.where).desc()).tuples()
print(list(res))
"""
[(4, '红魔馆'), (1, '白玉楼'), (1, '魔法森林'),
(1, '博丽神社'), (1, '东方地灵殿'), (1, '辉夜永远亭')]
"""
# 要是按照多字段排序,那么直接写上多个字段即可。
# 其中peewee.fn.COUNT(Girl.where).desc()也可以写成 -peewee.fn.COUNT(Girl.where)
# 前面加上+号表示升序,-号表示降序
limit和offset
res = Girl.select().limit(2).offset(1).tuples()
print(list(res)) # [(2, '博丽灵梦', '博丽神社'), (3, '芙兰朵露', '红魔馆')]
# 或者这样写也可以,但是按照SQL来说,上面的写法更习惯一些
res = Girl.select().offset(1).limit(2).tuples()
print(list(res)) # [(2, '博丽灵梦', '博丽神社'), (3, '芙兰朵露', '红魔馆')]
res = Girl.select().limit(2).offset(1).tuples()
print(list(res)) # [(2, '博丽灵梦', '博丽神社'), (3, '芙兰朵露', '红魔馆')]
# 或者我们还可以通过paginate来实现
# paginate(a, b), 表示将数据分页,每一页显示b条数据,然后获取第a页的数据
# 这里表示每一页显示3条数据,然后返回第二页的数据。实际上这个paginate内部还是调用了limit和offset
res = Girl.select().paginate(2, 3).tuples()
print(list(res)) # [(4, '蕾米莉亚', '红魔馆'), (5, '帕秋莉·诺蕾姬', '红魔馆'), (6, '西行寺幽幽子', '白玉楼')]
所以我们通过peewee执行SQL时候,顺序如下:
Girls.select().where().group_by().having().order_by().limit().offset()
实现count(*)
# 直接返回一个int
print(Girl.select().count()) # 9
原生SQL
有些时候,我们是希望执行一些原生SQL的,我举个例子:比如我们想要查找某个字符、比如"幽"在字段name中出现的位置,在PostgreSQL中可以这么写:position('幽' in name),那如果在peewee里面要怎么做呢?难道是peewee.fn.POSITION('幽' in Girl.name) ?这样显然是不行的,因此这个时候我们就需要执行一些原生的SQL了。
res = Girl.select(peewee.SQL("position('幽' in name), name")).tuples()
print(list(res))
"""
[(0, '古明地觉'), (0, '博丽灵梦'), (0, '芙兰朵露'),
(0, '蕾米莉亚'), (0, '帕秋莉·诺蕾姬'), (4, '西行寺幽幽子'),
(0, '八意永琳'), (0, '雾雨魔理沙'), (0, '红美铃')]
"""
# 为0的话表示name中不存在'幽'这个字,显然我们执行成功了的
# 我们看到peewee.SQL的作用就是将字符串里面的内容当成普通SQL来执行
# 不仅如此,我们还可以混合使用
res = Girl.select(peewee.SQL("position('幽' in name)"), Girl.name).tuples()
print(list(res))
"""
[(0, '古明地觉'), (0, '博丽灵梦'), (0, '芙兰朵露'),
(0, '蕾米莉亚'), (0, '帕秋莉·诺蕾姬'), (4, '西行寺幽幽子'),
(0, '八意永琳'), (0, '雾雨魔理沙'), (0, '红美铃')]
"""
# peewee.SQL不仅可以在在select里面,还可以在其他的地方
from peewee import fn, SQL
# where是SQL的关键字,所以需要使用双引号括起来, 而group by语句中可以使用给字段起的别名
res = Girl.select(fn.COUNT(SQL('"where"')), Girl.where.alias("哈哈")).group_by(SQL("哈哈")).tuples()
print(res) # SELECT COUNT("where"), "t1"."where" AS "哈哈" FROM "girl" AS "t1" GROUP BY 哈哈
print(list(res))
"""
[(1, '白玉楼'), (1, '魔法森林'), (1, '博丽神社'),
(1, '东方地灵殿'), (4, '红魔馆'), (1, '辉夜永远亭')]
"""
总的来说,peewee.SQL的作用就是将里面的内容原封不动的交给数据库来执行。
rollup、cube、grouping sets多维度统计
先来看一下数据集。
select * from sales_data;
/*
pk saledate product channel amount
1 2019-01-01 桔子 淘宝 1864
2 2019-01-01 桔子 京东 1329
3 2019-01-01 桔子 店面 1736
4 2019-01-01 香蕉 淘宝 1573
5 2019-01-01 香蕉 京东 1364
6 2019-01-01 香蕉 店面 1178
7 2019-01-01 苹果 淘宝 511
8 2019-01-01 苹果 京东 568
9 2019-01-01 苹果 店面 847
10 2019-01-02 桔子 淘宝 1923
11 2019-01-02 桔子 京东 775
12 2019-01-02 桔子 店面 599
13 2019-01-02 香蕉 淘宝 1612
14 2019-01-02 香蕉 京东 1057
15 2019-01-02 香蕉 店面 1580
16 2019-01-02 苹果 淘宝 1345
17 2019-01-02 苹果 京东 564
18 2019-01-02 苹果 店面 1953
19 2019-01-03 桔子 淘宝 729
20 2019-01-03 桔子 京东 1758
21 2019-01-03 桔子 店面 918
22 2019-01-03 香蕉 淘宝 1879
23 2019-01-03 香蕉 京东 1142
24 2019-01-03 香蕉 店面 731
25 2019-01-03 苹果 淘宝 1329
26 2019-01-03 苹果 京东 1315
27 2019-01-03 苹果 店面 1956
28 2019-01-04 桔子 淘宝 547
29 2019-01-04 桔子 京东 1462
30 2019-01-04 桔子 店面 1418
31 2019-01-04 香蕉 淘宝 1205
32 2019-01-04 香蕉 京东 1326
33 2019-01-04 香蕉 店面 746
34 2019-01-04 苹果 淘宝 940
35 2019-01-04 苹果 京东 898
36 2019-01-04 苹果 店面 1610
*/
其中pk表示自增主键,saledate表示日期,product表示商品,channel表示销售渠道,amount表示销售金额。
关于rollup和cube、grouping sets的具体含义可以网上搜索,我们直接演示。
import peewee
db = peewee.PostgresqlDatabase("postgres", host="localhost", password="zgghyys123", user="postgres", port=5432)
class SalesData(peewee.Model):
pk = peewee.AutoField()
saledate = peewee.DateField()
product = peewee.CharField()
channel = peewee.CharField()
amount = peewee.IntegerField()
class Meta:
database = db
table_name = "sales_data"
from peewee import SQL, fn
from pprint import pprint
res = SalesData.select(SQL("product, channel, sum(amount)")).group_by(fn.ROLLUP(SQL("product, channel"))).tuples()
pprint(list(res))
"""
[('桔子', '店面', 4671),
('桔子', '京东', 5324),
('桔子', '淘宝', 5063),
('桔子', None, 15058),
('苹果', '店面', 6366),
('苹果', '京东', 3345),
('苹果', '淘宝', 4125),
('苹果', None, 13836),
('香蕉', '店面', 4235),
('香蕉', '京东', 4889),
('香蕉', '淘宝', 6269),
('香蕉', None, 15393),
(None, None, 44287)]
"""
group by product, channel这是普通的group by语句,但如果是group by rollup(product, channel),那么除了会按照product、channel汇总之外,还会单独按照product汇总和整体汇总,按照product汇总的时候channel就会空了,整体汇总的时候product和channel都为空。
group by cube(product, channel),如果是cube的话,那么还是会按照product、channel汇总,但同时还会单独按照product汇总、单独按照channel汇总、整体汇总。我们看到cube相当于比rollup多了一个按照channel汇总
from peewee import SQL, fn
from pprint import pprint
res = SalesData.select(SQL("product, channel, sum(amount)")).group_by(fn.CUBE(SQL("product, channel"))).tuples()
pprint(list(res))
"""
[('桔子', '店面', 4671),
('桔子', '京东', 5324),
('桔子', '淘宝', 5063),
('桔子', None, 15058),
('苹果', '店面', 6366),
('苹果', '京东', 3345),
('苹果', '淘宝', 4125),
('苹果', None, 13836),
('香蕉', '店面', 4235),
('香蕉', '京东', 4889),
('香蕉', '淘宝', 6269),
('香蕉', None, 15393),
(None, None, 44287),
(None, '店面', 15272),
(None, '京东', 13558),
(None, '淘宝', 15457)]
"""
rollup和cube都可以通过grouping sets来实现,这么说吧:
group by rollup(product, channel)等价于group by grouping sets( (product, channel), (product), () ),首先最外层的括号不用说,里面的(product, channel)表示按照product和channel进行汇总,(product)表示按照product单独进行汇总,()表示整体进行汇总。至于cube估计有人也想到了,
group by cube(product, channel)等价于group by grouping sets( (product, channel), (product), (channel), () ),直接多一个(channel)即可。
group by product, channel,显然就是group by grouping sets( (product, channel) ),因此grouping sets可以更加方便我们自定制。
from peewee import SQL, fn
from pprint import pprint
res = (
SalesData.
select(SQL("coalesce(product, '所有商品'), coalesce(channel, '所有渠道'), sum(amount)")).
group_by(
getattr(fn, "GROUPING SETS")(SQL("(product, channel), (product), (channel), ()"))
).tuples()
)
pprint(list(res))
"""
[('桔子', '店面', 4671),
('桔子', '京东', 5324),
('桔子', '淘宝', 5063),
('桔子', '所有渠道', 15058),
('苹果', '店面', 6366),
('苹果', '京东', 3345),
('苹果', '淘宝', 4125),
('苹果', '所有渠道', 13836),
('香蕉', '店面', 4235),
('香蕉', '京东', 4889),
('香蕉', '淘宝', 6269),
('香蕉', '所有渠道', 15393),
('所有商品', '所有渠道', 44287),
('所有商品', '店面', 15272),
('所有商品', '京东', 13558),
('所有商品', '淘宝', 15457)]
"""
可以仔细体会一下上面的用法,总之在数据库中我们能直接使用的,基本上都能通过fn来直接调用。甚至中间包含了空格的grouping sets,我们也能通过使用反射的方式进行获取。
窗口函数
窗口函数是在select语句中的,但是为什么直到现在才说呢?因为它稍微难一些,下面我们就来看看如何在peewee中实现窗口函数。事实上如果你SQL语句写的好的话,那么直接通过peewee.SQL写原生的SQL也是可以的,会更方便。不仅是窗口函数,当然也包括上面刚说的cube、rollup、grouping sets等等。或者再比如case when语句,事实上peewee中提供了一个函数Case来实现这一逻辑,但是我们没说,因为觉得没有必要,还不如直接在peewee.SQL中写case when逻辑。
事实上你看一下peewee的Case函数的实现你就知道了,Case里面做的事情也是使用peewee.SQL来拼接case when语句,当然orm最大的作用不就是拼接SQL语句吗。因此,有些语句,我个人还是推荐在peewee.SQL里面写原生SQL的方式,会更方便一些。
from peewee import SQL, fn
from pprint import pprint
# 定义窗口,如果有多个窗口必须要起别名, 否则会报错:提示窗口已存在
w1 = peewee.Window(partition_by=[SalesData.product, SalesData.channel]).alias("w1")
w2 = peewee.Window(partition_by=[SalesData.product]).alias("w2")
w3 = peewee.Window(partition_by=[SalesData.channel]).alias("w3")
res = SalesData.select(SQL("product, channel"),
# 通过over来指定窗口,注意:此时只是指定了窗口
# 但是窗口的定义是什么,当前的sum还是不知道的
# 比如:第一个窗口函数当前只是 sum(amount) over w1
# 这个w1究竟如何定义的,我们需要在下面的window中指定
fn.SUM(SalesData.amount).over(window=w1),
fn.SUM(SalesData.amount).over(window=w2),
fn.SUM(SalesData.amount).over(window=w3)
# 必须调用window,将定义的窗口传进去
# 等价于 window w1 as (partition by product, channel), w2 as ..., w3 as ...
).window(w1, w2, w3).tuples()
pprint(list(res))
"""
[('苹果', '店面', 6366, 13836, 15272),
('苹果', '店面', 6366, 13836, 15272),
('苹果', '店面', 6366, 13836, 15272),
('苹果', '店面', 6366, 13836, 15272),
('桔子', '店面', 4671, 15058, 15272),
('桔子', '店面', 4671, 15058, 15272),
('桔子', '店面', 4671, 15058, 15272),
('桔子', '店面', 4671, 15058, 15272),
('香蕉', '店面', 4235, 15393, 15272),
('香蕉', '店面', 4235, 15393, 15272),
('香蕉', '店面', 4235, 15393, 15272),
('香蕉', '店面', 4235, 15393, 15272),
('苹果', '京东', 3345, 13836, 13558),
('桔子', '京东', 5324, 15058, 13558),
('桔子', '京东', 5324, 15058, 13558),
('桔子', '京东', 5324, 15058, 13558),
('桔子', '京东', 5324, 15058, 13558),
('苹果', '京东', 3345, 13836, 13558),
('苹果', '京东', 3345, 13836, 13558),
('苹果', '京东', 3345, 13836, 13558),
('香蕉', '京东', 4889, 15393, 13558),
('香蕉', '京东', 4889, 15393, 13558),
('香蕉', '京东', 4889, 15393, 13558),
('香蕉', '京东', 4889, 15393, 13558),
('桔子', '淘宝', 5063, 15058, 15457),
('桔子', '淘宝', 5063, 15058, 15457),
('桔子', '淘宝', 5063, 15058, 15457),
('桔子', '淘宝', 5063, 15058, 15457),
('香蕉', '淘宝', 6269, 15393, 15457),
('香蕉', '淘宝', 6269, 15393, 15457),
('香蕉', '淘宝', 6269, 15393, 15457),
('香蕉', '淘宝', 6269, 15393, 15457),
('苹果', '淘宝', 4125, 13836, 15457),
('苹果', '淘宝', 4125, 13836, 15457),
('苹果', '淘宝', 4125, 13836, 15457),
('苹果', '淘宝', 4125, 13836, 15457)]
"""
如果没有调用window的话,那么会报错:窗口"w1"不存在,当然不仅w1,w2、w3也是不存在的,总之在select中over的窗口必须在window中传进去。
当然Window这个类里面,还可以传入order_by,以及窗口的起始和结束位置。
ROWS frame_start
-- 或者
ROWS BETWEEN frame_start AND frame_end
其中,ROWS 表示以行为单位计算窗口的偏移量。frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
- UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值;
- N PRECEDING,窗口从当前行之前的第 N 行开始;
- CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
- CURRENT ROW,窗口到当前行结束,默认值
- N FOLLOWING,窗口到当前行之后的第 N 行结束。
- UNBOUNDED FOLLOWING,窗口到分区的最后一行结束;
下图演示了这些窗口选项的作用:
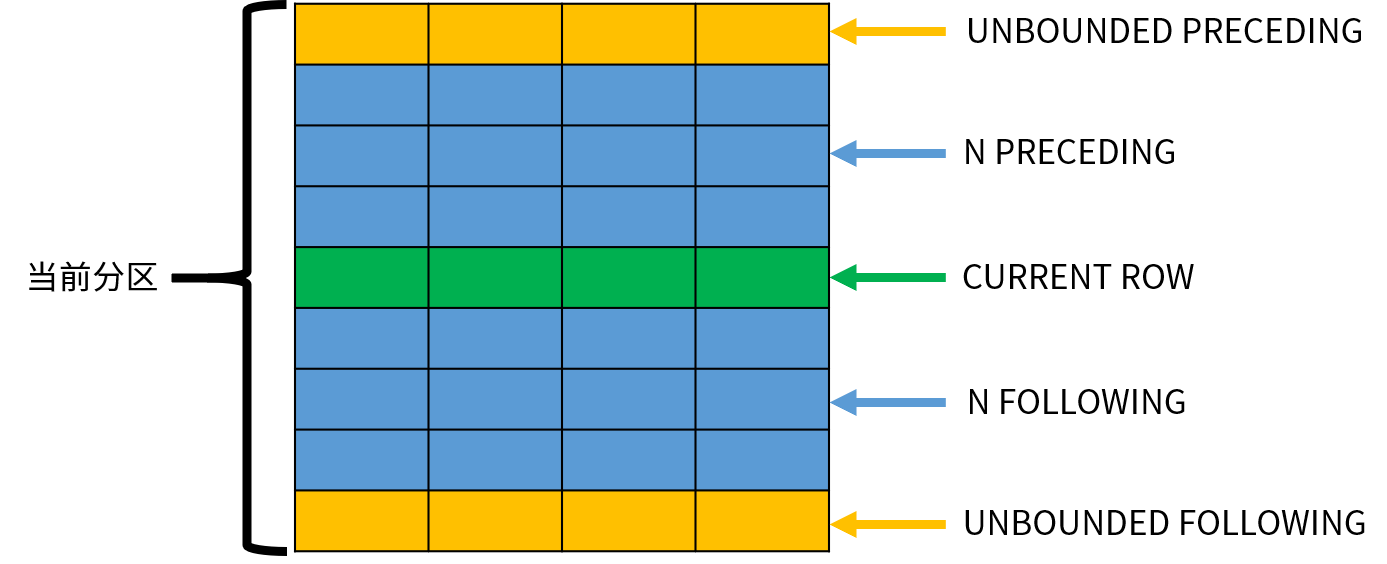
我们举例说明:
rows unbounded preceding
select product, amount,
sum(amount) over w as sum_amount
from sales_data
where saledate = '2019-01-01'
window w as (partition by product order by amount rows unbounded preceding)
/*
桔子 1329 1329
桔子 1736 3065
桔子 1864 4929
苹果 511 511
苹果 568 1079
苹果 847 1926
香蕉 1178 1178
香蕉 1364 2542
香蕉 1573 4115
*/
from peewee import SQL, fn
from pprint import pprint
# 定义窗口
w = peewee.Window(partition_by=[SalesData.product], order_by=[SalesData.amount],
start=peewee.Window.preceding())
res = SalesData.select(SQL("product, amount"),
fn.SUM(SalesData.amount).over(window=w)
).where(SalesData.saledate == '2019-01-01').window(w).tuples()
pprint(list(res))
"""
[('桔子', 1329, 1329),
('桔子', 1736, 3065),
('桔子', 1864, 4929),
('苹果', 511, 511),
('苹果', 568, 1079),
('苹果', 847, 1926),
('香蕉', 1178, 1178),
('香蕉', 1364, 2542),
('香蕉', 1573, 4115)]
"""
rows n preceding
select product, amount,
sum(amount) over w as sum_amount
from sales_data
where saledate = '2019-01-01'
window w as (partition by product order by amount rows 2 preceding)
/*
桔子 1329 1329
桔子 1736 3065
桔子 1864 4929
苹果 511 511
苹果 568 1079
苹果 847 1926
香蕉 1178 1178
香蕉 1364 2542
香蕉 1573 4115
*/
from peewee import SQL, fn
from pprint import pprint
# 定义窗口
w = peewee.Window(partition_by=[SalesData.product], order_by=[SalesData.amount],
# Window.preceding中不传入值就是unbounded preceding,传入值value就是<value> preceding
start=peewee.Window.preceding(2))
res = SalesData.select(SQL("product, amount"),
fn.SUM(SalesData.amount).over(window=w)
).where(SalesData.saledate == '2019-01-01').window(w).tuples()
pprint(list(res))
"""
[('桔子', 1329, 1329),
('桔子', 1736, 3065),
('桔子', 1864, 4929),
('苹果', 511, 511),
('苹果', 568, 1079),
('苹果', 847, 1926),
('香蕉', 1178, 1178),
('香蕉', 1364, 2542),
('香蕉', 1573, 4115)]
"""
rows between 1 preceding and 1 following
select product, amount,
round(avg(amount) over w, 2) as sum_amount
from sales_data
where saledate = '2019-01-01'
window w as (partition by product order by amount rows between 1 preceding and 1 following
)
/*
桔子 1329 1532.5
桔子 1736 1643
桔子 1864 1800
苹果 511 539.5
苹果 568 642
苹果 847 707.5
香蕉 1178 1271
香蕉 1364 1371.67
香蕉 1573 1468.5
*/
from peewee import SQL, fn
from pprint import pprint
# 定义窗口
w = peewee.Window(partition_by=[SalesData.product], order_by=[SalesData.amount],
start=peewee.Window.preceding(1),
end=peewee.Window.following(1))
res = SalesData.select(SQL("product, amount"),
fn.ROUND(fn.AVG(SalesData.amount).over(window=w), 2)
).where(SalesData.saledate == '2019-01-01').window(w).tuples()
pprint(list(res))
"""
[('桔子', 1329, Decimal('1532.50')),
('桔子', 1736, Decimal('1643.00')),
('桔子', 1864, Decimal('1800.00')),
('苹果', 511, Decimal('539.50')),
('苹果', 568, Decimal('642.00')),
('苹果', 847, Decimal('707.50')),
('香蕉', 1178, Decimal('1271.00')),
('香蕉', 1364, Decimal('1371.67')),
('香蕉', 1573, Decimal('1468.50'))]
"""
所以我们看到可以在窗口中指定大小,方式为:rows frame_start或者rows between frame_start and frame_end,如果出现了frame_end那么必须要有frame_start,并且是通过between and的形式
frame_start的取值为:没有frame_end的情况下,unbounded preceding(从窗口的第一行到当前行),n preceding(从当前行的上n行到当前行),current now(从当前行到当前行)。
frame_end的取值为:current now(从frame_start到当前行),n following(从frame_start到当前行的下n行),unbounded following(从frame_start到窗口的最后一行)
此外数据库还提供了一些排名窗口函数、取值窗口函数等等,这些只要你熟悉数据库的语法,那么调用peewee也是很简单的,我们举个例子:
from peewee import SQL, fn
from pprint import pprint
# 定义窗口
w = peewee.Window(partition_by=[SQL("product")], order_by=SalesData.amount)
res = SalesData.select(SalesData.amount,
fn.ROW_NUMBER().over(window=w)
).where(SalesData.saledate == '2019-01-01').window(w).tuples()
pprint(list(res))
"""
[(1329, 1),
(1736, 2),
(1864, 3),
(511, 1),
(568, 2),
(847, 3),
(1178, 1),
(1364, 2),
(1573, 3)]
"""
其他的函数类似,可以自己尝试一下。
查看表和字段的信息
peewee的一些常见用法,我暂时只想到了上面那些。如果没有介绍到的,可以通过peewee的源代码或者官方文档查看。总之,peewee.fn是一个很不错的东西,数据库里面的能直接用的基本上都可以通过fn来调用。甚至grouping sets这种,我们可以可以通过反射的形式来调用。还有一个万金油peewee.SQL,我们可以直接在里面写原生SQL,如果你SQL写得好的话,根本不需要那么多花里胡哨的。
我们调用的peewee的函数,其底层做的事情就是在转成peewee.SQL进行拼接,比如我们来看一下peewee中的Case函数。
def Case(predicate, expression_tuples, default=None): clauses = [SQL('CASE')] if predicate is not None: clauses.append(predicate) for expr, value in expression_tuples: clauses.extend((SQL('WHEN'), expr, SQL('THEN'), value)) if default is not None: clauses.extend((SQL('ELSE'), default)) clauses.append(SQL('END')) return NodeList(clauses)所以我们看到Case这个函数就是在使用peewee.SQL进行拼接,因此我们直接通过peewee.SQL是完全没有问题的,有些时候反而推荐这种做法。
下面我们来看看如何通过peewee查看一个表的信息。
from pprint import pprint
import peewee
db = peewee.PostgresqlDatabase("postgres",
host="localhost",
port=5432,
user="postgres",
password="zgghyys123")
class OverWatch(peewee.Model):
pk = peewee.AutoField(verbose_name="自增主键")
name = peewee.CharField(verbose_name="姓名", null=False, index=True)
hp = peewee.IntegerField(verbose_name="血量", default=200)
attack = peewee.CharField(verbose_name="英雄定位")
ultimate = peewee.CharField(verbose_name="终极技能")
class Meta:
database = db
table_name = "ow"
schema = "anime"
# 1. 查询一张表的记录总数
print(OverWatch.select().count()) # 15
# 2. 查询该表的所有字段名
meta = OverWatch._meta
pprint(meta.columns)
"""
{'attack': <CharField: OverWatch.attack>,
'hp': <IntegerField: OverWatch.hp>,
'name': <CharField: OverWatch.name>,
'pk': <AutoField: OverWatch.pk>,
'ultimate': <CharField: OverWatch.ultimate>}
"""
# 3. 获取该表的主键
print(meta.get_primary_keys()) # (<AutoField: OverWatch.pk>,)
print([_.name for _ in meta.get_primary_keys()]) # ['pk']
# 4. 是否是联合主键
print(meta.composite_key) # False
# 5. 获取该表的默认值
print(meta.get_default_dict()) # {'hp': 200}
# 6. 主键是否自增
print(meta.auto_increment) # True
# 7. 表名和schema名
print(meta.table_name, meta.schema) # ow anime
# 8. 获取所有的约束
print(meta.constraints) # None
通过peewee查看一个表的所有字段的信息。
meta = OverWatch._meta
columns = meta.columns
for col in columns:
pprint({"字段名": columns[col].column_name,
"是否为主键": columns[col].primary_key,
"字段类型": columns[col],
"是否允许非空": columns[col].null,
"是否必须唯一": columns[col].unique,
"是否是索引": columns[col].index,
"默认值": columns[col].default,
"约束": columns[col].constraints,
"注释": columns[col].verbose_name}
)
"""
{'字段名': 'pk',
'字段类型': <AutoField: OverWatch.pk>,
'是否为主键': True,
'是否允许非空': False,
'是否必须唯一': False,
'是否是索引': False,
'注释': '自增主键',
'约束': None,
'默认值': None}
{'字段名': 'name',
'字段类型': <CharField: OverWatch.name>,
'是否为主键': False,
'是否允许非空': False,
'是否必须唯一': False,
'是否是索引': True,
'注释': '姓名',
'约束': None,
'默认值': None}
{'字段名': 'hp',
'字段类型': <IntegerField: OverWatch.hp>,
'是否为主键': False,
'是否允许非空': False,
'是否必须唯一': False,
'是否是索引': False,
'注释': '血量',
'约束': None,
'默认值': 200}
{'字段名': 'attack',
'字段类型': <CharField: OverWatch.attack>,
'是否为主键': False,
'是否允许非空': False,
'是否必须唯一': False,
'是否是索引': False,
'注释': '英雄定位',
'约束': None,
'默认值': None}
{'字段名': 'ultimate',
'字段类型': <CharField: OverWatch.ultimate>,
'是否为主键': False,
'是否允许非空': False,
'是否必须唯一': False,
'是否是索引': False,
'注释': '终极技能',
'约束': None,
'默认值': None}
"""
我们通过db也可以获取很多信息
from pprint import pprint
import peewee
db = peewee.PostgresqlDatabase("postgres",
host="localhost",
port=5432,
user="postgres",
password="zgghyys123")
# 获取所有字段,传入表和schema
pprint(db.get_columns("girl", "public"))
"""
[ColumnMetadata(name='pk', data_type='integer', null=False, primary_key=True,
table='girl', default="nextval('girl_pk_seq'::regclass)"),
ColumnMetadata(name='name', data_type='character varying', null=False,
primary_key=False, table='girl', default=None),
ColumnMetadata(name='where', data_type='character varying', null=False,
primary_key=False, table='girl', default=None),
ColumnMetadata(name='country', data_type='character varying', null=True,
primary_key=False, table='girl', default=None)]
"""
print(db.get_columns("girl")[0].data_type) # integer
# 获取表的外键,第二个参数schema不指定默认是public
print(db.get_foreign_keys("girl")) # []
# 获取表的索引
print(db.get_indexes("girl"))
"""
[IndexMetadata(name='girl_pkey',
sql='CREATE UNIQUE INDEX girl_pkey ON public.girl USING btree (pk)',
columns=['pk'], unique=True, table='girl')]
"""
# 获取一个schema下的所有表,schema不指定默认是public
print(db.get_tables())
"""
['a', 'b', 'course', 'girl', 'girl_info', 'girl_score',
'interface', 'ods_cir_df', 'ods_cir_di', 'people',
'sales_data', 't1', 't_case', 'teacher', '全球患病人数']
"""
# 获取一个schema下的所有视图,schema不指定默认是public
print(db.get_views())
"""
[ViewMetadata(name='people_view',
sql='SELECT people.pk,\n people.id,\n people.degree\n FROM people')]
"""
# 查看schema下是否存在某张表,schema不指定默认是public
print(db.table_exists("girl")) # True
修改表结构
当我们创建完一张表后,发现字段需要进行修改,这个时候怎么办呢?我们可以使用一个叫做playhouse的模块,这个模块为peewee提供了很多扩展功能,并且它不需要单独安装,装完peewee的时候就已经有了,我们来看一下。
import peewee
from playhouse.migrate import PostgresqlMigrator, migrate
from playhouse.db_url import connect
# 通过peewee.PostgresqlDatabase也可以,这两者是通用的
db = connect("postgres://postgres:zgghyys123@localhost:5432/postgres")
# 传入db,实例化一个PostgresqlMigrator对象
migrator = PostgresqlMigrator(db)
with db.transaction():
migrate(
# 设置schema
migrator.set_search_path("anime"),
# 删除一个字段,传入表名、字段名
migrator.drop_column("ow", "attack"),
# 增加一个字段,传入表名、字段名、peewee.xxxField
migrator.add_column("ow", "country", peewee.CharField(verbose_name="英雄的国籍", null=True)),
# 重命名一个字段,传入表名、字段名、新字段名
migrator.rename_column("ow", "name", "Name"),
# 修改字段类型
migrator.alter_column_type("ow", "ultimate", peewee.TextField())
# 里面有很多操作,比如:增加约束、索引,删除约束、索引等等,可以进入源码中查看
# 甚至可以给表重命名
)
# 在外层我们写上了一个with db.transaction(): ,这是因为这些操作不是一个事务
# 执行完之后,会发现表被修改了
反射表
我们想通过orm来操作数据库中的表的时候,往往会定义一个Model,但是数据库里面已经存在了大量的表,我们总不能每操作一张表就定义一个Model吧,这样也太麻烦了。于是在sqlalchemy中提供了一个反射机制,可以自动将数据库中的表反射成sqlalchemy中Table。那么在peewee中可不可以呢?答案是可以的,只不过我们用的不是peewee,而是playhouse,当然我们完全可以把这两个模块当成是一家子。
import peewee
from playhouse.reflection import generate_models
# 通过playhouse.db_url.connect也可以,这两者是通用的
db = peewee.PostgresqlDatabase("postgres",
host="localhost",
port=5432,
user="postgres",
password="zgghyys123")
models = generate_models(db)
# 得到了一个字典,分别是表名和Model组成的键值对
print(models)
"""
{'a': <Model: a>, 'b': <Model: b>, 'course': <Model: course>,
'girl': <Model: girl>, 'girl_info': <Model: girl_info>,
'girl_score': <Model: girl_score>, 'interface': <Model: interface>,
'ods_cir_df': <Model: ods_cir_df>, 'ods_cir_di': <Model: ods_cir_di>,
'people': <Model: people>, 'sales_data': <Model: sales_data>,
't1': <Model: t1>, 't_case': <Model: t_case>, 'teacher': <Model: teacher>,
'全球患病人数': <Model: 全球患病人数>}
"""
# 当然也可以指定表名,给指定的表反射成Model
# 如果想反射视图的话,那么只需要添加一个参数include_views=True即可,默认是False
print(
generate_models(db, table_names=["girl", "interface"])
) # {'girl': <Model: girl>, 'interface': <Model: interface>}
# 指定schema
models = generate_models(db, schema="anime")
print(models) # {'ow': <Model: ow>}
# 我们来操作一波
Girl = generate_models(db, table_names=["girl"])["girl"]
from pprint import pprint
pprint(list(Girl.select().dicts()))
"""
[{'name': '古明地觉', 'pk': 1, 'where': '东方地灵殿'},
{'name': '博丽灵梦', 'pk': 2, 'where': '博丽神社'},
{'name': '芙兰朵露', 'pk': 3, 'where': '红魔馆'},
{'name': '蕾米莉亚', 'pk': 4, 'where': '红魔馆'},
{'name': '帕秋莉·诺蕾姬', 'pk': 5, 'where': '红魔馆'},
{'name': '西行寺幽幽子', 'pk': 6, 'where': '白玉楼'},
{'name': '八意永琳', 'pk': 7, 'where': '辉夜永远亭'},
{'name': '雾雨魔理沙', 'pk': 8, 'where': '魔法森林'},
{'name': '红美铃', 'pk': 9, 'where': '红魔馆'}]
"""
总的来说,peewee还是很强大的,可以实现我们日常所需的功能。并且搭配playhouse,可以实现很多意想不到的功能。至少在PostgreSQL方面,目前是可以和sqlalchemy相媲美的,当然sqlalchemy还支持peewee不支持的数据库,比如:Oracle、SqlServer,甚至是hive,并提供了更高级的功能,毕竟代码量摆在那里,只不过那些功能我们很少使用。
另外,可能有人注意到了,我们目前说的都是单表操作。那多表之间的union呢?join呢?以及定义多张表,通过外键建立联系,关联查询呢?答案是都没有,这里只介绍单表,至于多表的话可以自己去了解,事实上也比较简单,没什么复杂的。
peewee_async
介绍完peewee,再解释peewee_async就简单很多了,因为peewee_async是基于peewee并进行了异步化,执行SQL的流程没有任何变化,只不过操作需要在协程中进行执行。使用peewee_async操作PostgreSQL的话,需要pip install aiopg,操作MySQL,则需要pip install aiomysql
import asyncio
from peewee_async import PostgresqlDatabase, Manager
from playhouse.reflection import generate_models
db = PostgresqlDatabase("postgres",
host="localhost",
port=5432,
user="postgres",
password="zgghyys123")
# 得到模型
Model = generate_models(db, table_names=["girl"])["girl"]
# 然后我们需要将db传入到Manager中得到一个async_db
async_db = Manager(db)
async def main():
res = await async_db.execute(Model.select().dicts())
print(list(res))
asyncio.run(main())
只需要在协程中运行,并且将原来的操作写成await async_db.execute中即可。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏

