

机器学习&数据挖掘笔记_25(PGM练习九:HMM用于分类)
前言:
本次实验是用EM来学习HMM中的参数,并用学好了的HMM对一些kinect数据进行动作分类。实验内容请参考coursera课程:Probabilistic Graphical Models 中的的最后一个assignmnet.实验用的是kinect关节点数据,由于HMM是一个时序模型,且含有隐变量,所以这个实验不是很好做。大家对HMM不熟悉的话可以参考网友的实验:code.
kinect人体关节数据中, 每个关节点由3个坐标数据构成,多个关节点数据(实验中为10个)构成一个pose,多个pose构成一个action,每个action所包含的pose个数可能不等。其示意图如下:
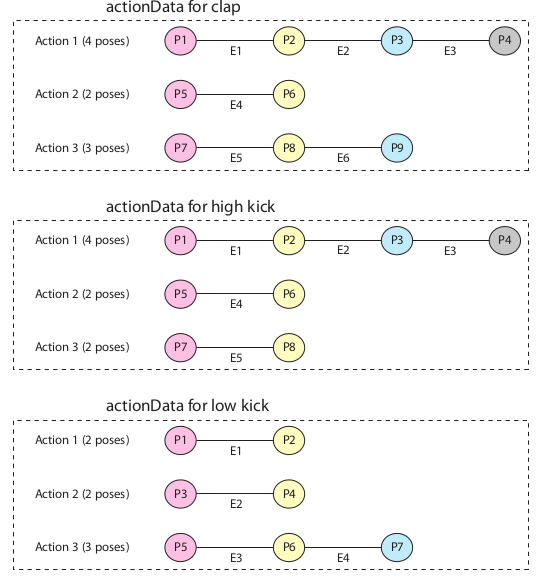
图中有3个action: clap, high kick, low kick. 而每个action可以由不同的pose序列构成,上面的每个action中列举出了3种情况,其长短可不一。在HMM模型中,上面模型中每个节点代表的是观察节点,代表一个pose,该pose可由状态变量(隐变量)产生,比如具有3个pose的action示意图如下:
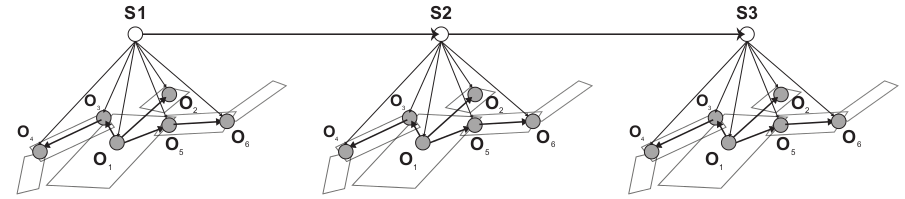
其中的状态变量S1,S2,S3并不是该pose的action标签,而是介于pose和action之间的一个隐藏类别,它与action和pose数据同时有关,这里state的物理意义不是十分明确,state节点的个数可由验证集通过实验来确定。
实验中一些函数的简单说明:
[P loglikelihood ClassProb] = EM_cluster(poseData, G, InitialClassProb, maxIter):
实验1的内容。poseData大小为N*10*3,表示N个pose的数据。G,P和练习八意思一样,为模型的结构信息。InitialClassProb大小为N*K,表示这N个样本分别属于K个类别的初始概率,ClassProb表示EM聚类完成后这N个样本属于各个类别的概率值。loglikelihood中保存的是每次EM迭代时的log似然值。模型中的隐变量为每个样本所属的类别。程序中的E步是:给定模型中的参数(每个关节点的CLG参数),求出每个样本属于各个类别的概率。M步为:给定每个样本属于K个类别的概率后,来求模型中每个关节点的参数。
[mu sigma] = FitG(X, W):
该函数类似于练习八中的FitGaussianParameters(),只是这里每个样本多了一个可信度权值,求高斯参数的时候需要把这个权值考虑进去。
[Beta sigma] = FitLG(X, U, W):
该函数类似于练习八中的FitGaussianParameters(),也是多了一个参数W,表示输入进来的数据X和父节点数据U的可信度为W中对应的值。每个state都会学习到的自己的参数beta和sigma,为HMM模型中的发射矩阵。
out = logsumexp(A):
很明显是求exp(A),然后求和,最后取log值,内部采用了防止数据溢出的方法。如果A是一个矩阵,则上面的操作是针对A的每一行进行的。
[P loglikelihood ClassProb PairProb] = EM_HMM(actionData, poseData, G, InitialClassProb, InitialPairProb, maxIter):
实验2的内容。参数结构比较复杂,简单介绍下。
actionData结构体向量:该向量中的每一个元素都是一个action。action.action表示对应动作的名称,在本函数中,因为是训练某个类别的HMM模型,所以其名称都一样。action.marg_ind,表示该action的pose数据在poseData向量中的行索引,同时也为pose属于各个state的概率值在ClassProb中的索引。action.pair_ind:action中连续的pose之间的边在PairProb中的索引,PairProd矩阵中的每一行表示对应edge两端之间的state转移概率。
poseData, G, InitialClassProb,maxIter和前面的差不多。
InitialPairProb:大小为V*K^2的矩阵,其中V为模型中边的数目,K为HMM模型中状态的个数,该矩阵与HMM转移矩阵的计算有关。
博文前面的HMM action示意图中对应的poseData, PairProb值形式如下所示:

返回值P和以前的P结构稍有不同,因为这里考虑到了HMM之间的状态转移,所以有P.transMatrix来表示HMM中状态转移矩阵,尺寸为K*K。另外P.c不再表示每个pose所属action的概率分布,而是初始状态分布。P.c表示在这些数据下,这个action对应state的先验概率。
EM_HMM()函数的作用是:用某个action的序列样本actionData来训练它的HMM模型,对应的模型参数包括转移概率,发射概率(包括各个状态下的关节点参数),初始概率。主要分为2个步骤:E步:给定参数,通过clique tree求数据;M步:给定数据,求HMM参数,比如初始状态分布计算:
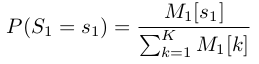
转移概率的计算公式为:
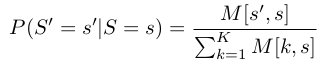
与发射概率相关的CLG参数计算参考练习八。
[M, PCalibrated] = ComputeExactMarginalsHMM(F):
F为HMM模型的factorlist,M为在该模型上进行精确推导的条件概率,与以前练习4实验中的推理类似。PCalibrated为校正好的clique tree,
[accuracy, predicted_labels] = RecognizeActions(datasetTrain, datasetTest, G, maxIter):
实验3的内容。datasetTrain为训练HMM模型时的样本,它是长度为3的向量(本实验只有3个动作类别),每个元素都是一个结构体。第1个结构体表示动作clap的数据,结构体中包含了actionData, poseData, InitialClassProb, InitialPairProb信息。第2个结构体为high_kick动作的数据,第3个结构体为low_kick动作的数据。datasetTest为测试样本,也是一个结构体,里面有actionData,poseData和labels. labels对应每个action的标签,“clap” = 1, “high kick” = 2, “low kick” = 3。实现该函数时首先用datasetTrain训练3个HMM模型参数,然后针对datasetTest中的每个action数据,计算它的posedata在每个模型各个状态下的概率。然后在这3个模型上分别建立clique tree,并算出生成这些样本的概率,概率值最大的那个模型对应的action为其分类类别。
相关理论知识点:
这部分可参考Corsera中的课件以及网友demonstrate的blog:PGM 读书笔记节选(十四)
不完全数据(incomplete data)主要包含2部分:缺失数据(missing data)和含隐变量的数据。
缺失数据又分2种情况:一是数据样本中有一些没有被观察到的量,一般用问号代替。另外一种是数据样本中直接少了一些数据,至于少了哪些数据,在哪些位置(序列数据)少了数据,都无法知道。
Missing at Random(MAR):随机缺失的一些样本,此时在给定观察到的样本条件下,没被观察的样本与控制缺失的开关变量相互独立。
带有隐变量的Likelihood函数值会有多个极值点,并且极值点的个数与隐变量的个数成指数关系(实际上,这些局部极值的log似然值也不相同)。带缺失数据的情形与之类似。有多个极值点的函数时即使学习到了其中一个极值点的参数,这组参数也未必就是模型中的true parameters. 隐变量的likelihood的另一个缺点就是likelihood函数不能按照变量和CPD等来局部分解,并且模型中一些不相关的参数也开始相关了(引入了新的v-structure)。
带隐变量likelihood函数参数的求解虽然可以采用一些高级的梯度下降法,但实际中用得较多的是EM算法。关于EM算法可以参考我前面的博文对EM算法的简单理解. 在隐变量likelihood这里,简单来说E步为给定模型参数,产生”完全”数据(把那些隐变量的数据也生成出来);M步为给定”完全”数据,计算模型参数。EM算法的特点是在前面迭代过程中收敛速度较快,越到后面收敛越慢。
梯度下降法是沿着一条直线进行搜索,而EM算法是沿着一个凸函数曲线来搜索其极值,有理论保证EM算法迭代过程中对应似然函数值不会下降。
参考资料:
coursera课程:Probabilistic Graphical Models
网友demonstrate的blog:PGM 读书笔记节选(十四)

