

C++笔记(2):《数据结构和问题求解》part1笔记
前言:
C++,数据结构,算法,这些知识在互联网行业求职过程中是必备的,而本科电路硬件出身的我这些基本就没学过,也用得比较少,为了以后的饭碗,从现在开始还是花点时间来看下这些东西吧。本节是mark allen Weiss数据结构书籍data structures and algorithm analysis in c++ (second edition)中第一大部分的笔记(随手写的,供自己以后参考),这部分主要是讲解一些C++的知识,比如面向对象概念,继承,多态,重载,虚函数,模板,设计模式等等。
Chap1:
本章主要是讲一些array,string,struct,pointer的东西,属于c++的一些非常基本的数据类型。
64bit Win7+32bit vs2010经过测试,发现不同数据类型占用的内存大小情况如下:
unsigned char:1, char:1, unsigned int:4, int:4, long:4,unsigned long:4
32bit的系统只能说明变量的地址是32bit(即4字节)的,与地址里面的内容所占内存大小无关。
一个指针也被看成是一个指向object的object。
array里面保存的是相同数据类型的变量,这些变量可以是结构体,而结构体中又可以用不同的数据类型。
vector代替原始的array,而string代替原始的strings。
其中vector和string属于一流的object,因为它们满足通用的操作。稍微不同的是vector是个类模板,而string是个类。
vector使用数组下标访问时不会进行边界检查,为了保险,需要保证它访问的范围在它边界内,所以此时的用法和普通的array没区别。
参数传递过程中采用引用而不是直接的形参一个原因是可以减小copy实参带来的开销。不过直接用引用的话有可能改变原来变量的内容,所以一般情况下都是用常量引用(如果不想原来的参数被改变的话)。
在STL中没有对应多维数组的object,不过在OpenCV中的Mat貌似有这个功能,二维的。
stirng中的c_str指返回一个char*类型,它指向的内容和原来的string一样。
对指针变量进行declaration操作时必须保证该指针已经正确初始化过了。
自动内存分配和动态内存分配是2个不同的概念,自动指的是程序自动执行,而动态指的是手动执行,在需要使用和销毁的时候声明,对应的关键字为new, delete. 如果pt是个指针,执行delete pt只是把pt指向的那一块内存给收回了,而pt本身这个变量还是存在的。
使用指针传递时属于c语言风格,而用引用传递时为c++语言风格。引用传递时,其实内部已经隐式将地址传递进去了,系统会自动每时每刻的解引用。使用引用的好处是我们只需在声明和定义引用时加入符号”&”,在函数内部实现时不要额外加其它符合,直接采用实值变量即可。在调用函数时也无需加入其它等符号。
因为struct中变量的数据类型不完全相同,所以我们不能像操作array那样循环操作它的每个变量。Struct里面包含多个变量类型,作为参数传递时一般不采用实值传递,因为这样的开销太大(主要是参数复制方面)。
如果ps是指向结构体的指针,a为结构体的一个成员变量,则(*ps).a表示访问结构体中的变量a,但是这样看起来比较别扭,所以在c++中提供了一个符号”->”带代替,此时的表达为ps->a.
Chap2:
类中定义的操作类型不能超过c++内嵌的数据操作类型范围。
Object是一个原子单元,不可分割的。类的性质如下:信息隐藏性,封装性,代码复用性,模板机制,继承机制,多态性(作为继承性的一部分实现)。
Object-oriented programming:面向对象编程。
Object-based programming:基于对象编程,该思想也有封装,信息隐藏,代码复用等机制,但是不包括多态和继承性质。
因为在执行类的构造函数时是先依次进行变量的所有内存分配,然后才进行变量的赋初值。一般类的数据成员都有其默认的赋值机制,如果需要更改其默认的值,可以在构造函数体中实现。但是有些变量,比如const变量,它需要在定义它(即分配内存)的时候给它赋初值,但是代价函数是首先分配完所有的内存,然后再赋值,明显不符合const变量初始化的要求。因此const变量的初始化只能在构造函数后的冒号初始化列表中进行,该处的优先级比构造函数本体的还要高。另一个例子就是类中有类的数据成员,并且它没有默认的初始化函数,因此这个类的初始化也应该在初始化列表中进行。
关键字explicit一般在构造函数前使用,且一般是单参数的构造函数,因为在C++中,如果一个类的构造函数是单参数的,它是允许直接给一个类的对象赋数值的,这实际上是系统首先定义了一个类的临时对象,并用该数值作为类的构造函数参数,然后将这个临时对象赋值给新的类对象。如果使用了explicit关键字后,系统(编译器)就不再允许直接将数字赋值给类对象了。
const主要用在3个地方:函数参数传递时,函数返回值,函数参数括号后。
在类中,析构函数,copy构造函数,赋值操作符,称为big three,这3个函数在系统内部已经有了个默认的实现,一般情况下我们不需要更改它。
析构函数主要是释放类中的变量,这些变量包括构造函数中定义的以及其他成员函数定义的,还有就是那些在类中使用new后的所有变量,它也关闭那些打开了的的所有文档。
*this表示当前的对象。
当类的数据成员有指针变量时,一般情况下需要重写Big Three。其中的析构函数需要用delete收回对应的指针变量。Copy构造函数需要满足deep copy操作。
将需要初始化特定值的变量尽量放在初始化列表中初始化,这样避免额外的赋值开销,因为那些不再初始化列表的变量的初始化过程都是在0-参数的构造函数中进行初始化的,如果你在自己重载的构造函数体中重新进行初始化,就相当于了2次赋值,并且有可能引起一些内存问题(上面的理解可能有问题)。数据成员的初始化顺序不是依照初始化列表进行的,而是依照在类中声明的次序进行的,因此我们要尽量避免定义那些相互依赖的变量。
下面的情况下数据成员一定要在初始化列表中进行初始化:常量;引用变量;没有0-参数构造函数的变量。
C函数中常犯的一个错误是返回一个指针(函数内部的)给一个动态变量,c++函数中常犯的一个错误是返回一个引用给动态变量。
在c++中,下面5个操作符是不能重载的:”.”, ”.*”, ”?:”, ”::”, ”sizeof”.并且操作符重载时只能重载c++中现有的操作符,不能重载新的操作符,且重载时其参数的个数不能够改变。总的来说重载操作符不能改变原先操作符的语法和优先级。
本来由于类的信息隐藏特性,其私有变量是不能被类对象调用的,它只能被内部的成员函数调用,但是如果有一个函数是该类的友元函数(一般情况下该函数不是该类的成员函数,而是外部函数),则在该函数内部是可以调用类中所有成员的。实际使用情况如下:当类A的对象B作为一个参数传入到函数f(A的友元函数)中时,在函数f的内部可以调用B中的所有成员,包括它的private成员(正常情况下,其对象时不能调用私有成员的)。
一般情况下尽量少用友元函数,可以考虑使用全局函数,类静态成员变量,类枚举变量等代替友元函数。
错误处理是c++类的设计中是个难题,一般情况下采用异常处理模式。异常处理常用的是try-catch语句,try有测试的意思,因为在try中实现的代码有可能有常识性的错误,自己在try语句里添加那些不符合逻辑的错误并throw一个整数值(其它类型的值也可以),这个整数可以理解为错误代号。然后在try语句后直接(不用分号)接catch函数,这个函数带有参数,其参数为可以为任何数据类型,如果不知道是什么类型,则可以采用通用符号“…”,然后在catch语句中实现对应的错误处理程序。
系统自动调用new[]一般发生在构造函数,赋值操作符=,+=中,系统自定调用delete[]一般发生在析构函数中。
函数值返回一个引用就是返回一个别名,返回一个常量引用就是表面返回的这个别名(所代表的值)不能被修改。
操作符重载时的函数名为operator+,operator-等,即operator和操作符一起构成的。
copy constructor与operator=的不同之处在于,在使用operator=时需要赋值符号两边的object都已经创建了,它是一个个元素进行赋值的。而copy constructor机制主要用于构造函数的copy,函数参数以value传递,函数返回值也为value的情况。
Chap3:
类模板的出现主要是为了代码的重复利用。一般是针对类型独立的场合。
模板分为函数模板和类模板。模板中实现的一般是通用的算法,简单的模板思想是:用typedef定义一个通用类型,然后用通用类型来实现函数内部。
在使用函数模板时,需要在使用前进行目标的声明,一般情况下如下所示:template<class anyType>
其中声明过程用尖括号,且后面不需要加分号,直接接函数或者类的实现过程,其中的anyType表示模板中可以识别的类型等,且目标中类别的个数一般不会太多,1到2个是最常见的。
使用类模板的基本原理和函数模板相同,但是有3个地方需要注意:1. 在类的实现前也需加入上面的模板声明语句,且在类的外面实现类中的成员函数时,如果用到了类模板参数anyType,则每个函数实现前都需要加入类模板声明。2. 在类外面实现类中的成员函数,除了前面要加入类模板声明语句外还需要在类的域操作符”::”前也加入类模板参数<anyType>. 3. 在用带模板的类初始化一个对象时,需要给类模板参数一个确定的参数,也是用尖括号括起来。
类模板的目的是为了实现一个通用的类,这样当不同的类型传入时都可以完成其想要的功能,体现了代码的重用性。不过还有一种模板叫做特殊模板,即它只适用于某个特定的类型,它的类模板声明语句为:template<>,里面是空的。这种使用方法一般是跟在一个通用类模板后面,因为它的模板参数为空,所以在类的实现时其模板要传递具体的类型。这样当新建一个目标类时,如果它属于哪个具体的类型(即特殊模板),则按照特殊模板来处理,否则就属于通用模板了。
在老版本的类模板的实现代码时,类模板的实现也是放在.h文件中的,因为当时分开编译会出现一些问题,且在对应的cpp文件在实现每个函数之前需要加入类模板声明。
类模板有缺省的参数,也可以有多个参数。
Chap4:
类之间常见的关系有IS-A,HAS-A。其中类的继承属于IS-A。
三种继承方式如图所示:
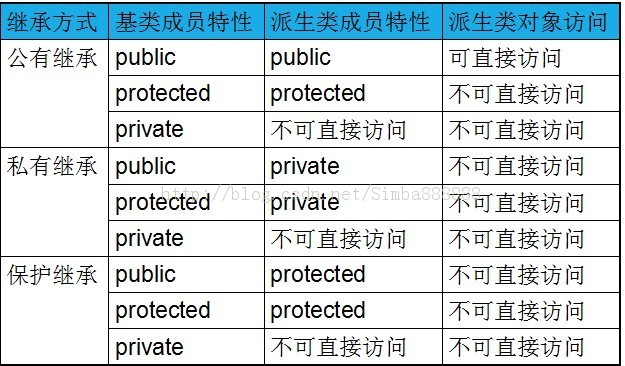
指向基类的指针或者引用是可以指向其子类对象。
公有继承时父类的隐藏属性在子类中是不变的,私有继承时,父类中所有的成员在子类中都是私有的。即使是公有继承,其父类的构造函数和析构函数是不能够被子类所继承的,但是在子类进行对象化时,由于用到了父类,所以其父类必须先建立,这时候父类的构造函数也会被使用,但子类销毁时,先执行的是子类的析构函数,然后才执行父类的析构函数。
当把父类中的任何一个成员放在了子类的private区时,表示这些成员在子类中是不能再被使用的,如果将其放在public区时,就需要覆盖重新实现这些成员。
类的protected成员只对它自己和它的子类开放,对其它类不开放。
子类构造函数的初始化列表中可以直接通过函数名调用基类的构造函数,如果此时子类的构造函数体内容为空,则表明直接使用父类的构造函数。
子类的设计一般不需要再考虑父类的那些私有成员,因此父类中私有成员的更改对子类的设计毫无影响。
重写分为2种,一种是直接重写成员函数,一种是重写虚函数,但是只有重写虚函数才是体现类的多态性。多态性的目的是为了实现接口重用。
虚函数有一个好处是可以直接用父类的指针调用对应的子类的函数,而不需要用子类对象去调用。非纯虚函数的情况下,如果子类没有实现对应的虚函数代码,则子类对象调用的是父类的那个函数内容。
要真正实现多态(采用指针或引用访问时),应该将virtual关键字放在父类中声明,放在子类中是无效的。
即使在父类中,构造函数,析构函数,赋值操作,拷贝构造函数等放在public区,且子类也是public方式继承父类的,如果子类中没有重新定义自己的这几个函数,那么系统会自动为子类这几个函数采用默认的方法构造,而不是用父类的,因为子类不继承这些。
在类的设计中,通常情况下是将构造函数定义为非虚的,而将析构函数定义为虚函数。
含有至少一个抽象方法(一般叫做纯虚函数,后接”=0”来代替函数体)的类叫做抽象类,抽象类是不能用来实例化对象的,它的子类如果没有实现对应的抽象方法则也不能用来实例化对象,因此它的构造函数平常是用不到的,除非子类调用来初始化父类的一些变量。不过可以定义指向抽象类的指针或者引用来指向它的子类(非抽象的子类)。
类中函数的默认参数都是静态绑定的,一般情况下其它的成员函数(虚函数)地址也是静态绑定的。
函数重载:在一个类中,函数与函数的函数名相同,参数类型或者参数的个数不同,对函数的返回值不一定需要完全相同,只需兼容即可。
函数覆盖:在基类和派生类中,基类的函数必须是虚函数,两个类中的函数与函数的函数名相同,参数类型和个数也完全相同,函数的返回值类型也要求相同。
函数隐藏:在基类和派生类中,两个类中的函数名相同情况下,不满足函数覆盖的所有情况都是函数隐藏。
公有继承体现的是IS-A关系,而私有继承体现的是HAS-A关系。一般情况下尽量少使用私有继承方式。并且默认情况下子类的继承都是私有继承,所以在子类继承为非私有继承时不要忘了添加对应的关键字。
父类的友函数原则上不是子类的友函数,不过父类的友函数可以访问子类中从父类公共继承的那些成员。
如果要体现类的多态性机制,则一般情况下不要将对象当做值传递。
类应用中的composition机制指的是一个类代码的实现过程中会调用另一个类对象,最常见的情况就是将一个类对象作为参数传递到另一个类的构造函数中。
多态性指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。C++支持两种多态性:编译时多态性,运行时多态性。编译时多态性:通过重载函数实现;运行时多态性:通过虚函数实现。
Chap5:
一个设计模式类似于一个菜谱,它有模式的名字,问题的描述,问题的解决方法和结果描述。
如果我们要实现在一个比较大小的函数中,其参数要满足各种数据类型,我们可以在每个对应的类中实现比较操作符”<”,这样每实现一个类就需要重载一次操作符。假设我们不希望在类的内部实现该功能,就应该在类外部实现该操作符,但是一旦这个操作符函数定了,就只能有一个并不能满足所有的类型的情况了。所以另外一种实现方法就是在类的外面实现多个比较函数,这个函数就叫做functor。Functor的大致的意思就是把一个类对象当函数一样使用,当然这个类需要重载()操作符。因为他比较像函数,所以得了一个叫Funtor的名字,它来自于commond设计模式。一个functor仅仅包含一个方法,没有包含数据成员,所以将它当为参数传递时需要以值传递的方式进行。Functor也就是我们常说的函数句柄,可以用类来实现。这样传入完成比较功能的函数的参数为数据集以及这个函数类了。
C++标准中有一个wrapper指针类名为auto_ptr,这个指针能够自动的动态删除内存。一般指针内存的删除发生在下面3种情况:1. 函数内部new的局部变量。 2. 函数内部new的局部变量指针且作为返回值,该返回指针在另外一个函数中被调用,当调用它的函数结束时,需要释放new过的内存。 3. New后的一个指针作为参数传入一个函数中,而在这个函数的内部使用了delete掉这个参数指针。auto_ptr的内部有一个指针以及一个owner的指示变量,如果是这个指针的”主人”, 则析构函数时需要删除对应的指针内存,如果复制操作发生,则转移”主人”的身份。因此auto_ptr属于一个指针wrapper。常量引用wrapper主要是用来处理引用指向NULL的情况。
wrapper侧重于包装,而adapter侧重于接口之间的转换。
为了解决类型双向转换带来的编译问题,我们在类的构造函数中尽量使用explicit关键字。
指针可以指向一个目标或空对象,而引用只能指向一个目标,不能为NULL。
当两个类之间相互调用时,需要一个不完全的类声明。
Iterator模式是用来解决一个聚合对象的遍历问题,将对聚合的遍历封装到一个类中进行,这样就避免了暴露这个聚合对象的内部表示的可能。最直接的想法是遍历一个容器,而不用考虑该容器内部的元素类型。
迭代器的设计需要满足自己有hasNext和next方法,并且对应的容器有getIterator的类型转换方法。
factory模式出现的原因:1. 一个基类指针可以指向任意它的子类对象,但是每次都需要用new来创建子类,且需知道子类的名字,这样程序的扩展和维护会变得麻烦。2. 当类A中要用到基类B,且需要初始化B的一个子类,但是此时A并不知道该初始化哪个子类,不过A的子类知道。因此Factory提供了2个重要的功能:定义创建了类的接口,封装了对象的创建;使得具体类的工作延迟到了子类当中。在factory模式中,每个容器都可以返回一个指向抽象类的迭代器。
Composite模式主要是当一个函数需要返回多个参数时(2个参数的最为常见)可以采用,比如说pair,pair常用于构造map和dictionary。
Observer模式主要是解决一对多的依赖关系,当”一”(subject)变化了,则对应的多个依赖(obverser)也相应变化。常见例子就是excel图表中一组数据可以有多个可视化结果,当其中数据改变了时,则这些可视化结果也跟着改变。一般情况下obverser有更新的功能。
参考资料:
data structures and algorithm analysis in c++ (second edition),mark allen Weiss.
23种设计模式(C++)

