

Deep learning:二十一(随机初始化在无监督特征学习中的作用)
这又是Ng团队的一篇有趣的paper。Ng团队在上篇博客文章Deep learning:二十(无监督特征学习中关于单层网络的分析)中给出的结论是:网络中隐含节点的个数,convolution尺寸和移动步伐等参数比网络的层次比网络参数的学习算法本身还要重要,也就是说即使是使用单层的网络,只要隐含层的节点数够大,convolution尺寸和移动步伐较小,用简单的算法(比如kmeans算法)也可取得不亚于其它复杂的deep learning最优效果算法。而在本文On random weights and unsupervised feature learning中又提出了个新观点:即根本就无需通过那些复杂且消耗大量时间去训练网络的参数的deep learning算法,我们只需随机给网络赋一组参数值,其最终取得的特征好坏不比那些预训练和仔细调整后得到的效果些,而且这样还可以减少大量的训练时间。
以上两个结论不免能引起大家很多疑惑,既然这么多人去研究深度学习,提出了那么多深度学习的算法,并构建了各种深度网络结构,而现在却发现只需用单层网络,不需要任何深度学习算法,就可以取得接近深度学习算法的最优值,甚至更好。那么深度学习还有必要值得研究么?单层网络也就没有必要叫深度学习了,还是叫以前的神经网络学习算了。这种问题对于我这种菜鸟来说是没法解答的,还是静观吧,呵呵。
文章主要是回答两个问题:1. 为什么随机初始化有时候能够表现那么好? 2. 如果用无监督学习的方法来预赋值,用有监督学习的方法来微调这些值,那这些方法的作用何在?
针对第一个问题,作者认为随机初始化网络参数能够取得很好的效果是因为,如果网络的结构确定了,则网络本身就对输入的数据由一定的选择性,比如说会选择频率选择性和平移不变性。其公式如下:

因此,最优输入处的频率是滤波f取最大的幅值时的频率,这是网络具有频率选择性的原因;后面那个相位值是没有固定的,说明网络本身也具有平移不变形选择性。(其实这个公式没太看得,文章附录有其证明过程)。下面这张图时随机给定的网络值和其对应的最佳响应输入:
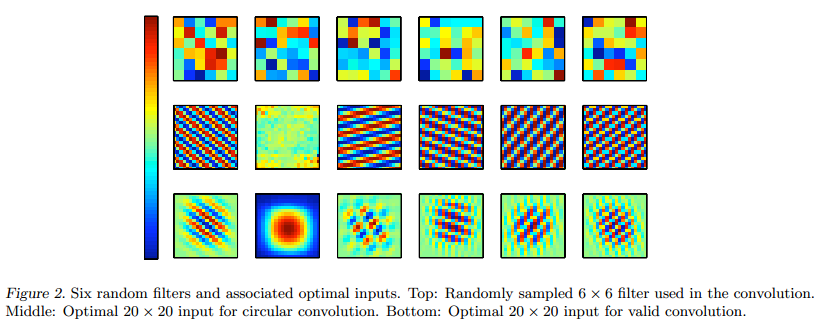
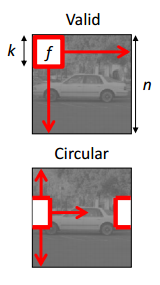
其中圆形卷积是指其卷积发生可以超出图片的范围,而有效卷积则必须全部在图片范围内进行。其示意图可以参考下面的:
作者给出了没有使用convolution和使用了convolution时的分类准确度对比图,图如下所示:
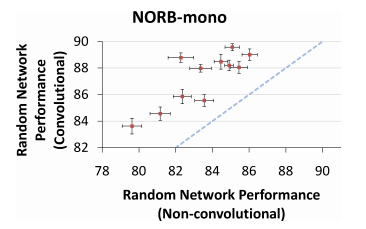
其中不使用convolution和使用convolution的区别是,前者在每个位置进行convolution时使用的网络参数是不同的,而后者对应的参数是相同的。由上图也可以知道,使用convolution的方法效果会更好。
下面是作者给出第二个问题的答案,首先看下图:

由上图可知,使用预训练参数比随机初始化参数的分类效果要好,测试数据库是NORB和CIFAR。预训练参数值的作用作者好像也没给出具体解释。只是给出了建议:与其在网络训练方法上花费时间,还不如选择一个更好的网络结构。
最后,作者给出了怎样通过随机算法来选择网络的结构。因为这样可以节省不少时间,如下表所示:

参考资料:
On random weights and unsupervised feature learning. In ICML 2011,Saxe, A., Koh, P.W., Chen, Z., Bhand, M., Suresh, B., & Ng, A. (2011).
Deep learning:二十(无监督特征学习中关于单层网络的分析)

