

AIX盘rw_timeout值过小导致IO ERROR
刚下班没多久,接收到告警提示数据库的数据文件异常,且同时收到主机硬盘的IO ERROR告警
该数据库服务器为AIX+oracle 9i环境,登录主机验证关键日志告警
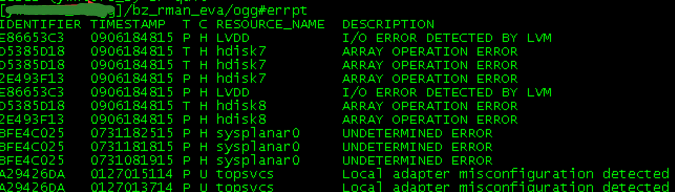
发现确实在18点48分有磁盘IO的报错
从而查看查看存储和交换机告警信息,都是正常状态
继续查看数据库告警日志
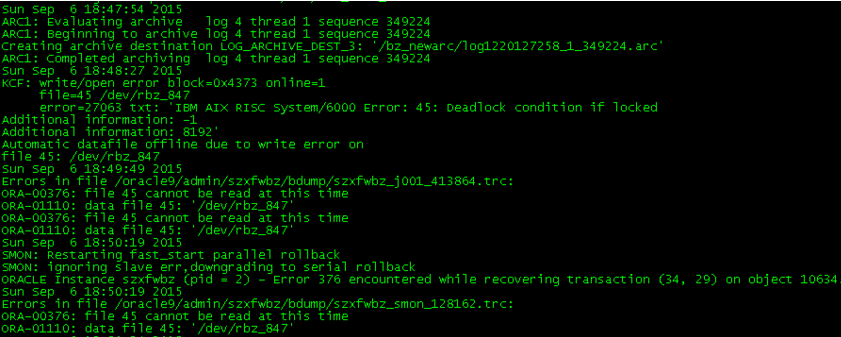
可以看到数据文件45无法正常访问
从数据库中查看数据文件状态
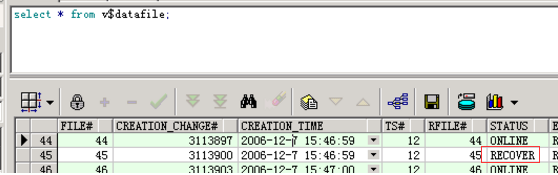
该数据文件处于recover状态
查看数据库的备份和归档都正常,继续进行数据文件级别的恢复操作
1 recover datafile 45; 2 alter database datafile 45 online;(因为之前做了offline的操作)
数据库恢复正常
注:恢复操作不能在PLSQL中实施,必须在sqlplus中操作
继续分析原因:
查看盘的具体报错信息
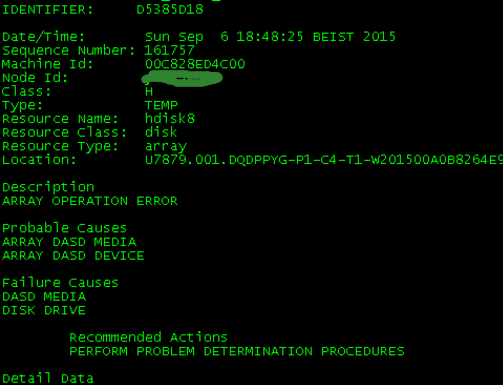
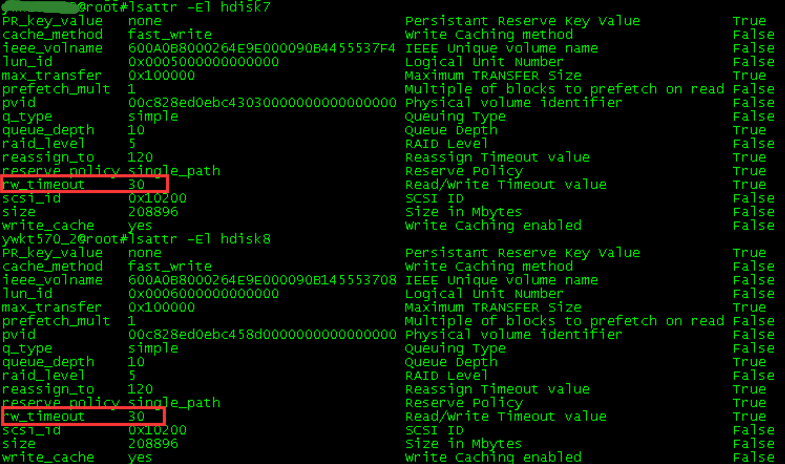
这样的错误,实际上,盘阵上也没有报硬盘的错误,交换机也正常,经过检查,最后修改了chdev -l hdisk6 -a rw_timeout=1000(这个值有点偏大)解决了此问题.
经过求证,在网上找到一个类似的说明:
Early vendor support recommendation is to increase rw_timeout, as they judge it as characteristic of a long fibre connection, but cables are only 15 metre, and due to its nature, we are loathe to start performing outages just to tweak settings that shouldn't be causing issue.
