
软工结对作业之词频统计plusplus
引子
1. 分工明细
- 031602509 董钧昊:Java爬虫的设计实现,附加题的设计实现
- 031602523 刘宏岩:升级优化WordCount的功能,命令函参数的使用
2. PSP表格
| psp2.1 | personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 原型开发 | 600 | 900 |
| Analysis | 需求分析(包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 20 | 150 |
| Coding Standrd | 代码规范(为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 60 | 180 |
| Coding | 具体编辑 | 180 | 180 |
| Code Review | 代码复审 | 120 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 210 | 300 |
| Test Repor | 测试报告 | 30 | 45 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 15 |
| - | 合计 | 1435 | 2150 |
3. 设计思路及实现流程
- 仔细阅读了作业文档后,总结了本次作业的两点要求:
- 爬取数据,并按照格式生成result.txt
- 升级第一次作业的WordCount,满足各种新增需求
- 有些功能在上次个人作业中已经说明,所以本次作业就不赘述了,要心疼一下我们两位可爱的助教小姐姐~
3.1 Java爬虫
- 最初为了方便起见,用python实现了一遍爬虫,但是考虑到测试问题,最终还是换用JAVA实现了一遍爬虫。
- 如下用流程图形式说明我的具体思路
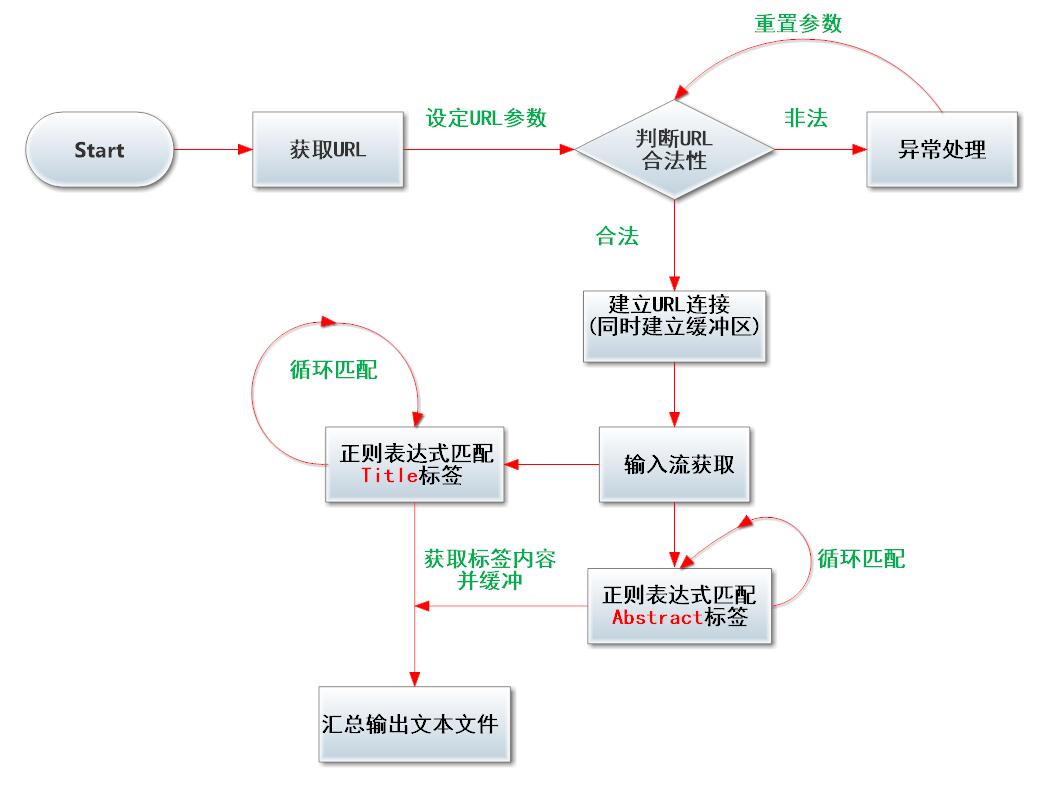
- 通过分析下图所示的网页源代码,我们可以容易看出,每一份论文的标题URL都被保存在ptitle这个标签中,我们只需通过循环匹配每一个标签上述标签就可以根据获得每一篇论文的标题Title——标签内容。

- 而摘要Abstract的获取则可以通过上图所示中的URL,访问对应子页面。分析子页面的源代码,我们可以看出,摘要被保存在了div id="abstract" 这个标签中,只需匹配标签头尾即可获取标签内容——摘要内容

- 简单说一下本次爬虫的几个注意事项:
- 首先是爬取摘要时,我下意识认为标签尾部只需匹配到 /这个字符即匹配到标签尾,但实际上摘要部分是有可能出现类似于/、div这两种字符串的,所以仍需全文匹配标签尾部。
- 当然提到后向匹配的问题,C++11非boost库不支持后向零宽断言 (具体差异详见上一篇博客),而JAVA这边的库支持大多数正则表达式匹配语言(少量需要外部库支持);本次也可以利用后向零宽断言来实现匹配标签尾部的功能。
- !!!查阅了部分资料后发现,在JDK1.3及之前的JDK版本中并没有包含正则表达式的类,如果要在Java中使用正则表达式必须使用第三方提供的正则表达式库。从JDK1.4开始提供了支持正则表达式API,它们位于java.util.regex包中。所以使用JAVA实现爬虫最好采用JDK1.4版本以上
3.2 代码组织与内部实现设计(类图)
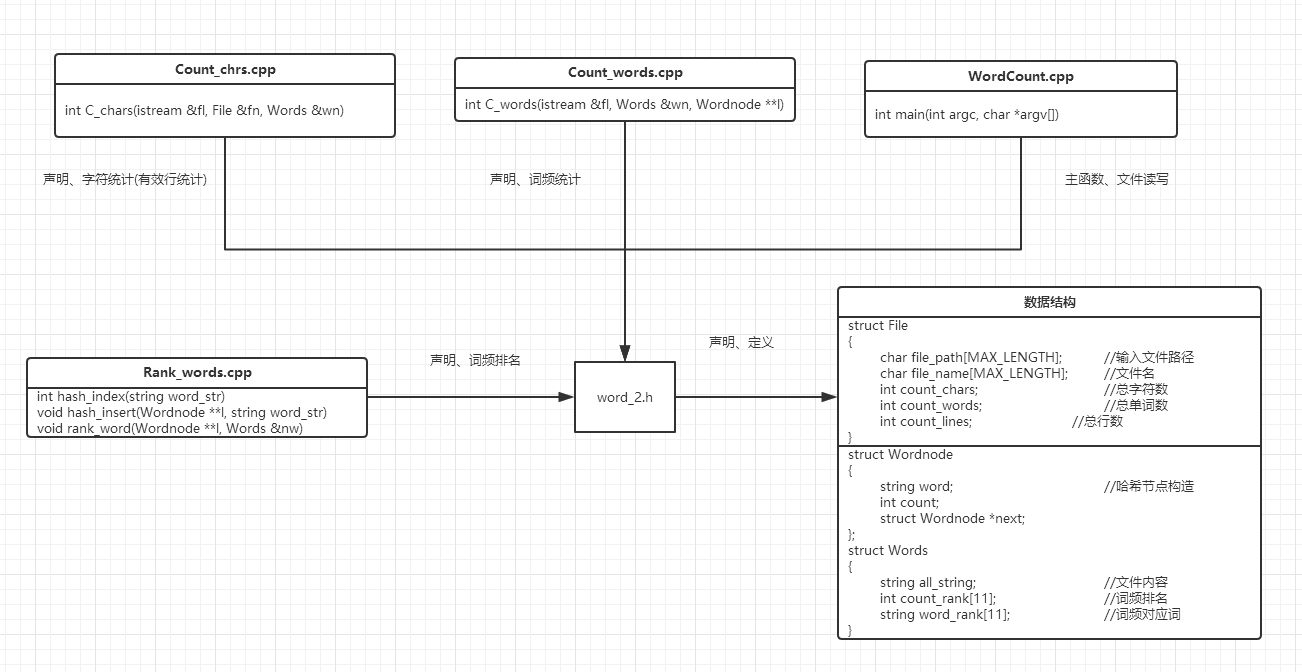
- 本次迭代的新版本代码仅在基础上修改完善了部分函数。
- 并在个人作业基础上优化了原型代码,去除旧代码冗余部分。
- 迭代更新大致内容如下所示
| 模块 | 备注 |
|---|---|
| work_2.h | 包含头文件、数据结构以及用到函数的声明 |
| Count_chrs.cpp | 统计字符数模块(也包含行数的统计) |
| Count_words.cpp | 统计单词、词组数模块(结果计入hashmap) |
| Rank_words.cpp | 词频、词组字典序导出模块,用于实现hashmap |
| WordCount.cpp | 主函数 |
3.3 命令行解析
- 命令行解析主要通过循环参数判定实现,使用一个循环体来判定传入参数首字符与次字符;同时加入非法检测模块,对不合法参数进行检测并提供错误提示。
- 值得一提的是,在Unix网络编程下,C++有一个getopt()函数可以快速有效地解析命令行参数,具体应用
for (v = 1; v < argc; v++)
{
if (argv[v][0] == '-' && strlen(argv[v]) == 2)
{
if (argv[v][1] == 'i') //输入参数判定
{
if (v + 1 < argc)
{
strcpy_s(fnew.file_name, argv[v + 1]);
fnew.i_flag = 1;
v = v + 1;
}
}
else if (argv[v][1] == 'o') //输出参数判定
{
if (v + 1 < argc)
{
strcpy_s(fnew.out_file_name, argv[v + 1]);
fnew.o_flag = 1;
v = v + 1;
}
}
else if (argv[v][1] == 'w')
{
if (v + 1 < argc)
{
fnew.w_flag = 1;
if (argv[v + 1][0] == '0') //权重参数判定
fnew.weight = 0;
else if (argv[v + 1][0] == '1')
fnew.weight = 1;
else
cout << "error for weight!" << endl;
v = v + 1;
}
}
else if (argv[v][1] == 'm')
{
if (v + 1 < argc)
{
fnew.m_flag = 1;
fnew.count_m = atoi(argv[v + 1]); //词组参数判定
if (fnew.count_m == 0)
{
cout << "error for m!" << endl;
return 0;
}
v = v + 1;
}
}
else if (argv[v][1] == 'n')
{
if (v + 1 < argc)
{
fnew.n_flag = 1;
fnew.count_n = atoi(argv[v + 1]);
if (fnew.count_n == 0)
{
cout << "error for n!" << endl; //排名参数判定
return 0;
}
v = v + 1;
}
}
}
}
if (fnew.n_flag == 0)
fnew.count_n = 10;
if (fnew.i_flag == 0 || fnew.o_flag == 0 || fnew.w_flag == 0) //三参数异常判定
{
cout << "parameters error!" << endl;
return 0;
}
- 本模块也可简化如下述流程图所示

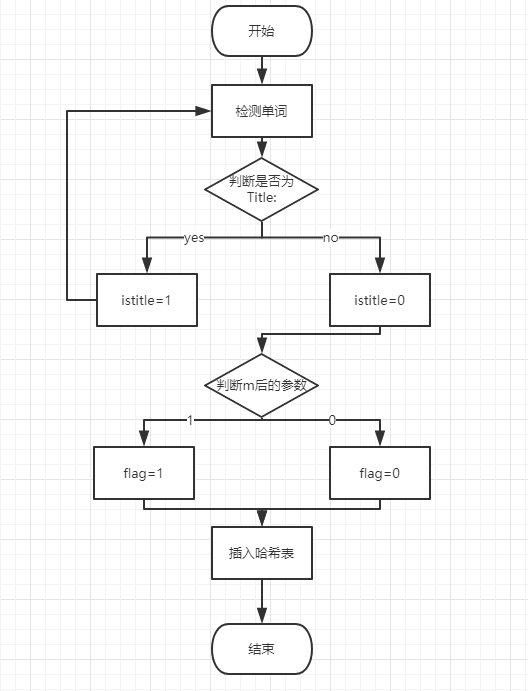
3.4 w—权重统计
-
标题中的单词(词组)在统计时算出现十次,摘要中的单词(词组)在统计时算出现一次。
-
实现这个功能关键就是区分标题和摘要,我们的思路是:
-
在提取单词时,通过单词
Title:和Abstract:来检测,并设置一个开关istitle。当检测到Title:时,置istitle为1,表示在此状态下提取出的单词(词组)都属于标题部分。否则置为0,表示在此状态下提取出的单词(词组)都属于摘要部分。这样就把单词(词组)用标题和摘要区分开啦! -
当然光有这些还不够,还要根据
w后的参数来判断是否需要权重功能。敲重点!!! 当istitle和w后的参数同时为1时,才能把标题中的单词(词组)按照10计数。 否则不管是标题还是摘要中的单词(词组),都只能按照1计数。 -
因为我们采用了hashmap的方法统计频,所以只要在插入哈希表的函数上稍作改动即可,即增加一个开关
flag,当需要计数10次时置flag=1,插入结点的times值置为10,否则flag=0插入结点的times值置为1。 -
本模块的流程图:
- 贴上关键代码,关键处用注释解释:
//istitle开关部分
if (temp_word == "title"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 7;
count_words--; //title不算有效单词
istitle = 1; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
if (temp_word == "abstract"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 10;
count_words--; //title不算有效单词
istitle = 0; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
//插入函数
void hash_insert(Wordnode **l, string word_str,int weight_flag)
{
int value = hash_index(word_str); //计算哈希值
Wordnode *p;
//cout << value;
for (p = l[value]; p != NULL; p = p->next) //查找节点并插入
{
if (word_str == p->word) //已有节点存在(重复单词)
{
p->count += 1 + weight_flag * 9;
return;
}
}
p = new Wordnode; //未有节点存在(新单词)
p->count = 1 + weight_flag * 9;
p->word = word_str;
p->next = l[value];
l[value] = p;
}
//带权重的插入部分
if (istitle == 1 && fn.weight == 1)
{
hash_insert(l, temp_comb,1); //插入10次
}
else
{
hash_insert(l, temp_comb,0); //插入1次
}
本模块可单独分割进行测试,使得本模块整体耦合度较低,且本模块内部几乎无冗余代码,也体现了内聚度较高的性质,彻底体现了高内聚、低耦合的特点。
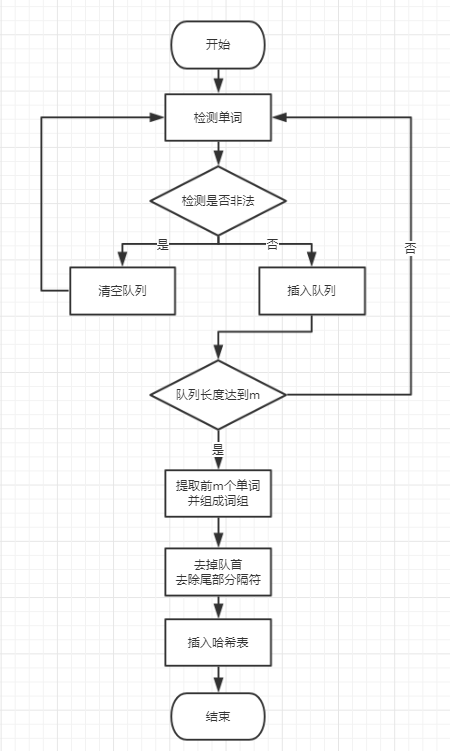
3.5 m—词组统计
-
本参数要求根据m后的参数,统计对应长度的词组词频。
-
我们总结了几个要点:
- 如何提取对应长度的词组
- 准确并完整的提取单词之间的分隔符
- 如何避免非法单词的干扰(数字,the、we等)
- 避免跨越标题和摘要提取单词组成词组
-
以下是我们的思路:
-
首先定义短单词、数字开头的单词、
Tiltle和Abstract为非法单词,其余为合法单词 。 -
在提取词组时,首先就是连续提取
m个单词。我们采用了队列的思想。每当提取出一个单词时连同它后面的所有分隔符组成一个string型变量进入队列。然后判断队列中的合法单词数目,如果等于m,就创建一个临时的空的string型变量,用它去连接队列中的前m个合法单词。然后去掉连接后所得字符串后面的所有分隔符,最后插入哈希表,并弹出队首单词。这样我们就取得了完整的分隔符。 -
要去除非法单词的干扰,只需在检测到非法单词时清空队列即可。因为队列中的单词数目不足m且不能后后面进来的单词组合成词组。
-
要去除
Tiltle和Abstract的干扰,每当我们检测到这两个单词时采用continue忽略,并清空队列,因为队列中的单词数目不足m且不能后后面进来的单词组合成词组。所以我们要清空队列,防止跨越标题和摘要提取单词组成词组。 -
本部分流程图:
- 贴出关键代码,关键处用注释解释:
//词组统计函数
if (temp_chr <= '9'&&temp_chr >= '0')
{
k++; //数字开头判断
while (k <= temp_line.size() - 1 && ((temp_line[k] <= '9'&&temp_line[k] >= '0') || (temp_line[k] <= 'z'&&temp_line[k] >= 'a')))
{
k++;
}
wordbuf.clear(); //数字开头,清空队列
}
else if (temp_chr <= 'z' && temp_chr >= 'a')
{
temp_word = "";
temp_word += temp_chr; //字符补足
//cout<<temp_word<<endl;
k += 1;
if (temp_line.size() - 2 > k) //判断余下位数是否够装下一个单词
{
while (k < temp_line.size() && ((temp_line[k] <= 'z' && temp_line[k] >= 'a') || (temp_line[k] <= '9' && temp_line[k] >= '0')))
{
temp_word += temp_line[k];
//cout << temp_word << endl;
k += 1;
}
//wordbuf.clear();
}
//检测到合法单词
if (3 < temp_word.size() && (temp_word[0] <= 'z'&&temp_word[0] >= 'a') && (temp_word[1] <= 'z'&&temp_word[1] >= 'a') && (temp_word[2] <= 'z'&&temp_word[2] >= 'a') && (temp_word[3] <= 'z'&&temp_word[3] >= 'a'))
{
count_words++;
if (temp_word == "title"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 7;
count_words--; //title不算有效单词
istitle = 1; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
if (temp_word == "abstract"&&temp_line[k] == ':'&&k <= temp_line.size())
{
fn.count_chars = fn.count_chars - 10;
count_words--; //title不算有效单词
istitle = 0; //表示目前处于标题状态
wordbuf.clear(); //标题和摘要状态切换时,清空队列因为词组不能跨越二者
k += 2; //跳过“: ”
continue; //获取下一个单词
}
if (fflag == 1) //只统计词组
{
int thischar = k;
//连接单词后的分隔符
while (isdivide(temp_line[thischar]) && thischar < temp_line.size())
{
temp_word = temp_word + temp_line[thischar];
thischar++;
}
wordbuf.push_back(temp_word); //进入队列
if (wordbuf.size() == len) //长度满足要求
{
for (int i = 0; i < len; i++)
{
temp_comb += wordbuf[i];
}
wordbuf.erase(wordbuf.begin()); //第一个单词清空
while (isdivide(temp_comb[temp_comb.length() - 1])) //去除最后的分隔符
{
temp_comb = temp_comb.substr(0, temp_comb.length() - 1);
}
if (istitle == 1 && fn.weight == 1)
{
hash_insert(l, temp_comb,1);
}
else
{
hash_insert(l, temp_comb,0);
}
temp_comb = "";
}
}
else //只统计单词
{
if (istitle == 1 && fn.weight == 1)
{
hash_insert(l, temp_word,1);
}
else
{
hash_insert(l, temp_word,0);
//cout << temp_word << endl;
}
temp_word = "";
}
}
else //遇见短单词
{
wordbuf.clear(); //清空队列
}
}
4. 性能分析与改进
- 使用爬取获得的
result.txt,参数为WordCount.exe -i result.txt -o output.txt -m 3 -n 10 -w 1,性能测试结果如下图:
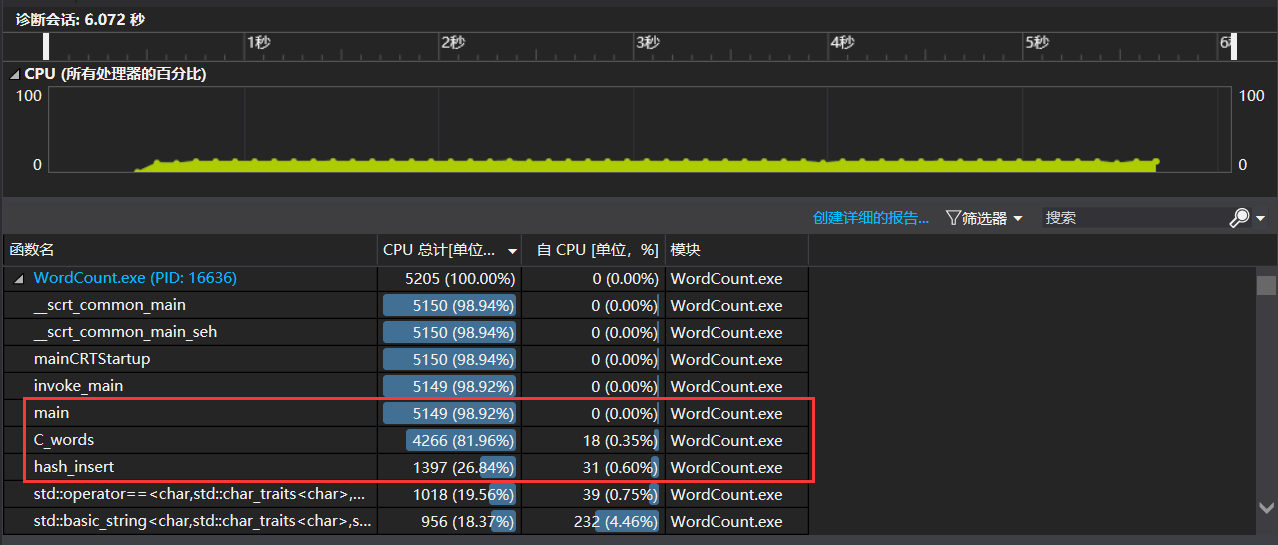
- 可以看出消耗最大的函数为C_words()函数,因为该函数执行单词提取和词组拼接的操作,占用的大部分的CPU时间,总时间为6.072s。
- 对此我们提出来静态模块转换为动态模块,不仅是从算法层次上提出的,更是从模块化层次提出的。
- 具体展示模块如下示对比图体现
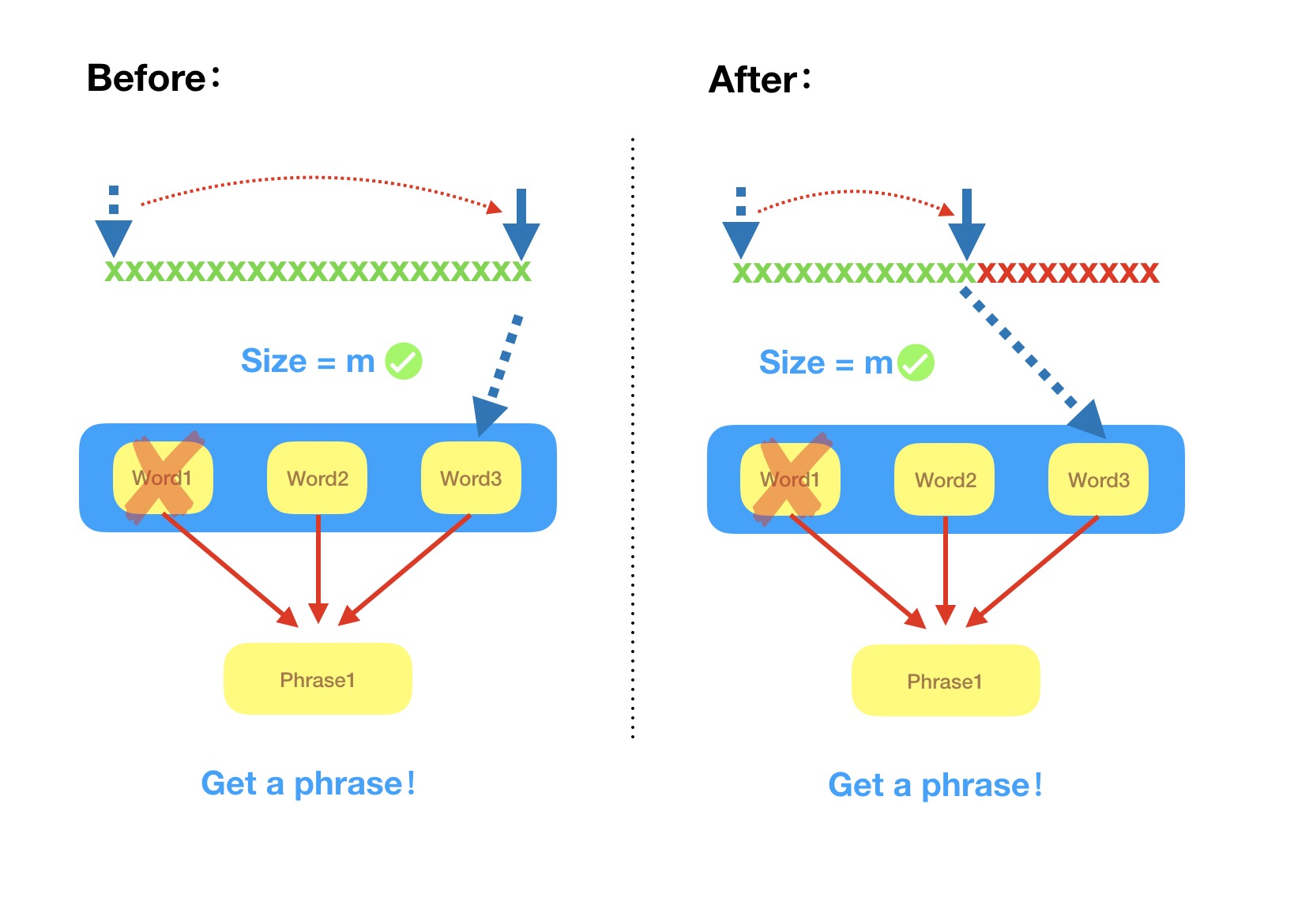
- 在之前我们通过静态判断词组及其之间的分割符,每次程序运行过程中均需花费大量的时间,维护该静态存储数据结构,且每次都需要遍历整个数据结构才能实现词组的筛选匹配
- 而改进之后,我们采用动态数据结构的形式,同时将模块中的静态化接口模块均转化成动态化程序应用模块,每次仅仅需要遍历部分数据结构,且采用二分法的遍历形式,极大程度的减少了再遍历的开销,使得代码能够以近乎单次完全遍历的结果。
- 改进后的效果如下图所示
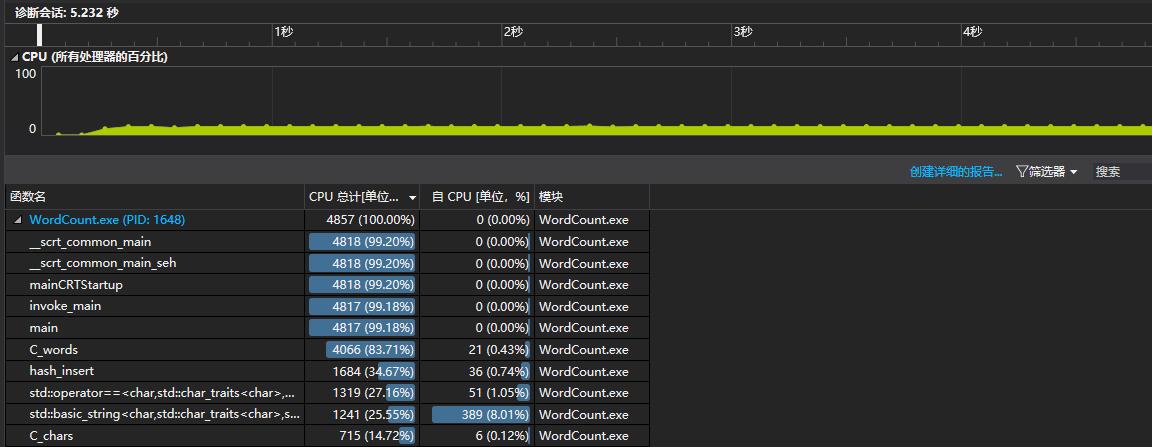
- 改进后时间为5.232s,性能速度提升比为13%
5.单元测试
- 设定了10个单元测试用于检测代码的准确性,如下表所示:
| 单元测试的内容 | 测试的模块 | 输出结果 | 测试结果 |
|---|---|---|---|
| 给定一个字符串 | 字符统计 | 字符数 | 通过 |
| 给定论文部分摘要A | 单词统计 | 字符数 | 通过 |
| 给定论文部分摘要B | 词频统计 | 排名前5词组 | 通过 |
| 非法参数 | 容错检测 | 错误提示 | 通过 |
| 输入文件异常 | 容错检测 | 错误提示 | 通过 |
| 输出文件异常 | 容错检测 | 错误提示 | 通过 |
| result.txt | 带权重单词统计 | 排名前五单词 | 通过 |
| result.txt | 长度为2、不带权词组统计 | 长度为2,排名前五词组 | 通过 |
| result.txt | 长度为3、带权词组统计 | 长度为3,排名前五词组 | 修改代码后通过 |
| result.txt | 长度为5、不带权词组统计 | 长度为5,排名前五词组 | 修改代码后通过 |
单元测试结果如下图所示:
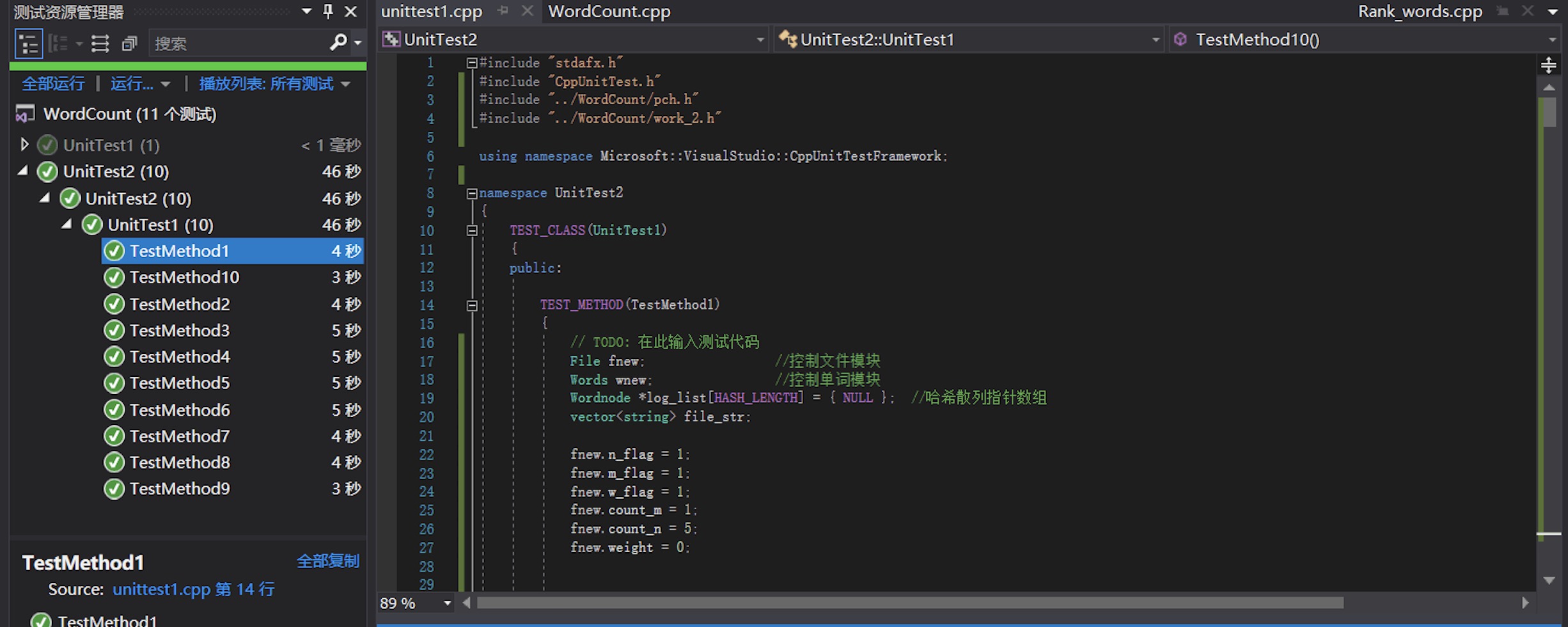
- 这里提供8、9两次测试的代码
//第八次单元测试
TEST_METHOD(TestMethod8)
{
// TODO: 在此输入测试代码
File fnew; //控制文件模块
Words wnew; //控制单词模块
Wordnode *log_list[HASH_LENGTH] = { NULL }; //哈希散列指针数组
vector<string> file_str;
fnew.n_flag = 1;
fnew.m_flag = 1;
fnew.w_flag = 1;
fnew.count_m = 2;
fnew.count_n = 5;
fnew.weight = 0;
ifstream f;
f.open("E:/result.txt", ios::in); //打开文件
fnew.count_chars = C_chars(f, fnew, wnew, file_str); //计算字符数(行数)
fnew.count_words = C_words(f, fnew, wnew, log_list, file_str); //计算单词数(插入哈希节点)
//cout << "chars = " << fnew.count_chars << "," << "lines = " << fnew.count_lines<<","<<"words = "<<fnew.count_words<<endl;
rank_word(log_list, wnew, fnew); //词频排名
Assert::AreEqual(wnew.word_rank[1], string("this paper"));
Assert::AreEqual(wnew.count_rank[1], 469);
Assert::AreEqual(wnew.word_rank[2], string("show that"));
Assert::AreEqual(wnew.count_rank[2], 340);
Assert::AreEqual(wnew.word_rank[3], string("neural networks"));
Assert::AreEqual(wnew.count_rank[3], 209);
Assert::AreEqual(wnew.word_rank[4], string("neural network"));
Assert::AreEqual(wnew.count_rank[4], 187);
Assert::AreEqual(wnew.word_rank[5], string("convolutional neural"));
Assert::AreEqual(wnew.count_rank[5], 186);
}
//第九次单元测试
TEST_METHOD(TestMethod9)
{
// TODO: 在此输入测试代码
File fnew; //控制文件模块
Words wnew; //控制单词模块
Wordnode *log_list[HASH_LENGTH] = { NULL }; //哈希散列指针数组
vector<string> file_str;
fnew.n_flag = 1;
fnew.m_flag = 1;
fnew.w_flag = 1;
fnew.count_m = 3;
fnew.count_n = 5;
fnew.weight = 1;
ifstream f;
f.open("E:/result.txt", ios::in); //打开文件
fnew.count_chars = C_chars(f, fnew, wnew, file_str); //计算字符数(行数)
fnew.count_words = C_words(f, fnew, wnew, log_list, file_str); //计算单词数(插入哈希节点)
//cout << "chars = " << fnew.count_chars << "," << "lines = " << fnew.count_lines<<","<<"words = "<<fnew.count_words<<endl;
rank_word(log_list, wnew, fnew); //词频排名
Assert::AreEqual(wnew.word_rank[1], string("convolutional neural networks"));
Assert::AreEqual(wnew.count_rank[1], 196);
Assert::AreEqual(wnew.word_rank[2], string("generative adversarial networks"));
Assert::AreEqual(wnew.count_rank[2], 178);
Assert::AreEqual(wnew.word_rank[3], string("convolutional neural network"));
Assert::AreEqual(wnew.count_rank[3], 159);
Assert::AreEqual(wnew.word_rank[4], string("visual question answering"));
Assert::AreEqual(wnew.count_rank[4], 156);
Assert::AreEqual(wnew.word_rank[5], string("deep neural networks"));
Assert::AreEqual(wnew.count_rank[5], 128);
}
6. 代码覆盖率测试
- 使用
Run OpenCppCoverage工具测试了本次作业程序的代码覆盖率,结果如下图所示:

- 可以看出覆盖率较低的模块为main函数和count_char函数,主要原因如下述所示:
- main函数中加入了许多异常检测代码段,比如文件打开失败检测等,导致覆盖率降低。
- count_char函数中,为了方便统计单词,我们把文档事先都转化为小写字母,由于爬取结果中大写字母数目很少,所以导致大小写转换的函数的使用率不高,代码覆盖率降低。
7.附加题设计
- 我们的附加题实现的功能主要是围绕CVPR的论文处理进行,我们可通过批量爬取论文PDF保存至本地、读取论文PDF转换文字、论文关键词、高频词检索并绘制词云。
- 为此我们通过Tkinter模块将上述功能整合在一起。
- 原先是想通过Web绘制较为好看的界面的,但是碍于时间限制,最终采用简洁的python模块进行界面UI设计实现。
- 在Windows界面下的效果如下图所示:

-
!!!虽说我们结对的俩人是钢铁直男,但是Tkinter的美工界面的也太粗糙了吧,我们认为这也与Tkinter在Windows下的底层实现方式以及移植问题相关。
-
经过查阅文档后,在Tkinter的首页上,我们得到了答案——Tkinter在Windows上的界面是极其不好看的,所以我们改用Ubuntu实现我们的界面。
仍不死心

-
在Ubuntu系统上配置好了环境后,再次运行程序的结果如下图所示:

-
本质上还只是将边框切换成了Ubuntu风格的界面,本质上内容很是十分简陋的。既然如此,不妨来看看我们实现的功能吧。
彻底死心 -
PDF批量下载模块
通过爬虫批量获取论文PDF的URL,同时完成解析功能,并且以text的形式将其保存在本地对应文件夹中,方便后续读取PDF功能的实现。
- PDF转换文字功能
通过将PDF转换成文字功能,从图片扩展到文字,虽说尚不可及我们的初衷——OCR识别论文,但是从结果层面考量已经足够实现这项功能了。
同时这项功能并不只是为了后续词云,我们也可以就此依据Google基于python提供的翻译库,实现论文的翻译,减轻了大多数用户的阅读负担。
或许你常会遇到论文中无法理解的专业术语,而这些术语大多是简写,这时我们该怎么办呢?对此我们可基于此结合情感分析的手段实现文本处理,大致结果图如下图所示:

本次计划实现的情感分析模块也会在团队作业中更加完善化的实现。
- 基于背景图片的词云生成
效果对比图如下图所示:

我们可根据用户所需指定的背景图片,生成更加有趣、好看的词云图,而不是仅仅基于普通的方框模板的词云图;该项功能给用户提供了高自由度的自制定模板,从基于官方固定模板到用户充足发挥想象力。
私以为这类能提供给用户的高自由度功能在当今已经是少之又少,市场上更多的则是限制了用户的思维方式,而本“产品”反其道行之,尽我们的最大程度给用户带来良好体验。
8.Github的代码签入记录

- 匆忙间只迭代了一个版本,但该版本是经过多次测试、修缮完成的。
- 同时提交了 “爬虫”脚本及主程序
9.遇到的代码模块异常或结对困难及解决方法
- 本次遇到的困难及各自的应对方式大致如下表中所列。
| 异常及困难描述 | 尝试解决 | 是否解决 | 有何收获 |
|---|---|---|---|
| 原型代码的选择 | 尝试测试了双方程序速度,并比对易读性 | 是 | 分析了下述多点如程序运行效率、测试结果准确性在内的诸多考量因素,同时考量了各自编码的优势及可行性来完成分工模块。 |
| 爬虫设计问题 | 原计划采用C++实现本次爬虫,但多次尝试均受阻于代码量极大且功能复杂的爬虫模块 | 是 | 解决问题不一定要按部就班地照标准模型进行,可以在既有模型的概念基础上,添加自身的思考与体会,打造出更适合团队实际应用的模型应用到本次问题中,若是担心应用的周期性及实用性,则可以选择其他模块开发。 |
| 钢铁直男的审美 | 尝试邀请美工“大触”,学习“生活与美”等类似界面UI教程 | 是 | 直男毁一生,美工“大触”都不屑跟我们合作,但是这一次我们的美工完成“从0到1”的改进,从流程图的绘制到改进对比图均体现出了我们审美的极大提升。 |
10. 学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 18 | 18 | 原型设计,爬虫关于python的urllib库及request库学习 |
| 2 | 0 | 300 | 8 | 26 | 钢铁直男们的审美进步“一点点” |
| 3 | 500 | 800 | 12 | 38 | Java爬虫、Tkinter界面 |
11.评价队友
- 我的队友031602523刘宏岩是我合作多年来的好基友,每次与他的合作我均能从合作过程中收获许多;我们俩也非常珍惜每一次合作的机会,
貌似他国庆烫个头回来越来越帅了 - 值得学习的地方:对待事情的认真、不懈的态度,并且主动提议熬夜完成代码部分的重构及组织测试。(当晚写代码到了凌晨5点)由于宿舍邻近,他也提出了功能时限制——每次分工量不超过2个小时,但时间截止双方立刻验收对方工作成果,这样的方式也正是我们超高执行力的来源。
- 值得改进的地方:其实这一块也是我们双方都需要改进的地方——时间观念问题,由于国庆各类要务 (?) 缠身,我们的进度也显得断断续续,只能等到回到宿舍才开始高效进行编码工作。
- 每一次合作无论过程的艰辛坎坷,我们都一步步走过来,我也始终期待下一次的合作!!
12.总结
- 结对作业从原型到实现,随然时间跨度不长,但仍是一份值得细品其内涵的一份作业。
- 大多数人偏好 “单打独斗”,只愿一个人完成整个功能的实现,而忽视了这种做法存在的致命缺陷——主观意愿过强;而结对作业不仅提供了一个能从客观角度帮助你分析的队友,还提供了一种结对编程形式的模板——其中一人主攻编码模块,另一人则更客观提出编码意见促进编码实现。也算是一种不可多得的编程体验吧。
- 最后我还是想不单仅为我自己,更为我优秀的结对队友鼓下掌吧!

13.附件
- 附件链接
- 密码:aam9
14. 更新(10.17)
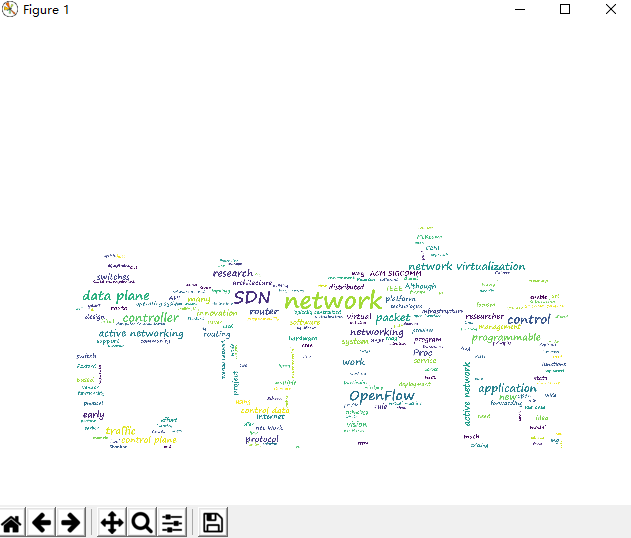
- 感谢柯老师帮我们找出了一个 “bug”
- 现已修正为通过采集的CVPR论文绘制出的词云,效果如下所示:

- 选自Misra_Learning_by_Asking_CVPR_2018_paper


