
写在前面
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 1750 | 2365 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 60 | 150 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| · Design | · 具体设计 | 180 | 90 |
| · Coding | · 具体编码 | 840 | 1320 |
| · Code Review | · 代码复审 | 280 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 360 |
| Reporting | 报告 | 135 | 140 |
| · Test Repor | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| | 合计 |1915 |2545
解题思路
- 本题考察的指标主要分为4项——统计字符、统计有效行数、统计单词数、统计词频。
- 解题思路大致将这4项小问题归为3类来解决。
【1】
统计字符数:只需要统计Ascii码,汉字不需考虑,
空格,水平制表符,换行符,均算字符。
- 字符方面
- 由题意只需考虑可视字符 (Ascii码:32~126) 以及水平制表符 (Ascii码:9) 和换行符 (Ascii码:10) 。
- 读取字符可以通过文件流 (get) 来逐个字符读取。
- 需要注意的是换行符和回车符二者的区别——换行符为 \n ,回车符为 \r 。具体区别可以参照这篇文章 。
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
-
有效行数方面
- 网上关于非空白字符的定义也有很多,向助教请教后,助教给出定义——非空白字符即Ascii码中可以显示的字符 。
- 所以例如下图所示,第二行不算作有效行,总有效行数为2。

- 综上所述,检测有效行只需要在每一行检测字符时判断是否先检测到可视字符,再检测到换行符即可。
- 最后一行的判断——仅需判断最后一行是否读到可视字符即可。
【2】
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 单词总数方面
【3】
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 词频统计方面
- 最开始是想直接采用STL的map来进行操作的,比较方便操作而且STL中的map也方便字典序排序,但是考虑到了STL中map的底层是依靠红黑树实现的,时间复杂度为O(logn)。而hashmap的时间复杂度为O(1)。
- 不过仍需考虑处理冲突的情况,但是相对于大数据量的情况,hashmap的效率会更高。
- 所以词频统计可以通过建立hashmap来实现,具体模型如下图所示。

- 每次检测到单词即进行hash操作一次,待文件完全读入后,最后再进行排序。
- 原先有考虑过最后的词频的排序方法,最开始的版本是AVL树进行排序,再输出结果。(代码敲到一半感觉想复杂了)。其实排序的时间是O(nlog(n)),而单独遍历10次的时间也是 O(n) 复杂度量级的。所以就当前需求的分析考虑,词频统计上,我采用了遍历的形式,消耗资源和时间在AVL树的旋转上 反而效率不会很高。
(输出全部单词并排序的话就要采用排序的方法,真香)
设计实现过程
代码文件组织
为了独立需求中的三项功能,所以我在代码文件上的组织也将这三项功能封装到不同的cpp文件中,并且在头文件中声明各自的函数。
-
work_2.h——包含头文件、数据结构以及用到函数的声明。 -
Count_chrs.cpp——统计字符数模块(也包含行数的统计) -
Count_words.cpp——统计单词数模块(结果计入hashmap) -
Rank_words.cpp——词频字典序导出模块
各个模块可以分开进行单元测试,也可以合并一起作为最终的输出结果。 -
Rank_words.cpp包含3个函数用于实现hashmap- hash_index用于实现hash值的计算,让哈希节点尽量分散,在理想情况达到O(1) 时间复杂度。
- hash_insert用于实现hash节点的插入(头插法)
- rank_word 用于排名并且导出前10词频
031602509
|- src
|- WordCount.sln
|- UnitTest1
|- WordCount
|- Count_chrs.cpp
|- Count_words.cpp
|- Rank_words.cpp
|- WordCount.cpp
|- WordCount.vcxproj
|- pch.cpp
|- pch.h
|- work_2.h
具体文件组织如下所示

实现流程图
整个需求完成的流程图如下所示。

- 个人认为比较关键的部分在单词判断与统计上
- 具体一点说就是用正则表达式的模板匹配符合要求的单词,并且记录并且统计次数。
- 详细正则表达式判断过程在下文中以流程图形式展示
关键函数
正则表达式的判断过程如下所示:
- 敲重点!!!查阅了一些文档,发现VS2017不支持零宽断言判断,所以使用正则表达式需要额外增加分隔符的判断

具体代码如下所示:(性能改进后)
int C_words(istream &fl, Words &wn, Wordnode **l)
{
int count = 0;
int flag = 0;
regex pattern(".[a-zA-Z]{3}[a-zA-Z0-9]*"); //设定正则表达式模板
smatch result; //smatch类存放string结果
//cout << regex_search(wn.all_string, result, pattern)<<endl;
string::const_iterator start = wn.all_string.begin(); //字符串起始迭代器
string::const_iterator end = wn.all_string.end(); //字符串末尾迭代器
string temp_str;
while (regex_search(start, end, result, pattern)) //循环搜索匹配模板的单词
{
flag = 0;
//cout<<"successfully match";
temp_str = result[0];
if (!((temp_str[0] <= 90 && temp_str[0] >= 65) || (temp_str[0] <= 122 && temp_str[0] >= 97)))//首字符判断
{
if (temp_str[0] >= 48 && temp_str[0] <= 57) //数字首字符判断
flag = 1;
temp_str.erase(0, 1);
if (!(temp_str.size()>=4&&((temp_str[3] <= 90 && temp_str[3] >= 65) || (temp_str[3] <= 122 && temp_str[3] >= 97))))
{
flag = 1;
}
}
if (flag == 0)
{
transform(temp_str.begin(), temp_str.end(), temp_str.begin(), ::tolower);//转换为小写单词
hash_insert(l, temp_str); //哈希节点插入
count++;
}
start = result[0].second; //检测下一单词
}
//cout << endl;
return count;
}
}
分析与改进
性能分析
- 性能分析上选择一份文本循环进行10000次测试。主要的时间损耗在正则表达式的匹配上以及文件输出上。
- 具体如下图所示
- 总时间消耗了23.071秒


- 可以看到主要性能消耗在单词检测上,我的改进思路是修改正则表达式,同时减少可避免的判断。为此我的改进如下:
- 修改正则表达式——减少额外不必要判断的性能损耗
- 修改hashmap——取余运算与散列长度均选取指数来减少查找时间
修改后结果如下图所示

- 时间降到了19.1秒
- 性能上得到了些许提升,提升了21%
单元测试
设定了12个单元测试用于测试代码,具体如下所示。
| 单元测试内容 | 测试模块 | 输出结果 | 测试效果 |
|---|---|---|---|
| 给定一个字符串 | 字符统计 | 字符数 | 通过 |
| 给定论文部分内容A | 单词统计 | 单词数 | 通过 |
| 给定论文部分内容B | 词频统计 | 词频前10排名 | 通过 |
| 非法参数 | 容错检测 | 错误提示 | 通过 |
| 输入文件异常 | 容错检测 | 错误提示 | 通过 |
| 输出文件异常 | 容错检测 | 错误提示 | 通过 |
| 给定部分文本内容与部分无效行 | 有效行判断 | 有效行数 | 通过 |
| 给定相近字符串 | 单词统计、词频统计 | 词频前10排名、单词数 | 修改代码后通过 |
| 给定存在大小写区别的字符串 | 单词统计、词频统计 | 词频前10排名、单词数 | 通过 |
| 给出“File123”与“123File” | 单词统计、词频统计 | 词频前10排名、单词数 | 修改代码后通过 |
| 给出多个不合规范字符串 | 单词统计 | 单词数 | 通过 |
| 给出类似乱码文档 | 单词统计、词频统计、有效行统计、字符统计 | 全部需求 | 通过 |

- 这里提供6和7两个测试单元的代码
- 分别是测试相近字符串和大小写区分字符串。
namespace WordCount_Test
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod6)
{
// TODO: 在此输入测试代码
File fnew; //控制文件模块
Words wnew; //控制单词模块
Wordnode *log[HASH_LENGTH] = { NULL }; //哈希散列指针数组
strcpy_s(fnew.file_name, "F:/VS_project/WordCount/WordCount_Test/test/test6.txt"); //获取文件名
//cout << fnew.file_name << endl;
ifstream f;
f.open(fnew.file_name, ios::in); //打开文件
if (!f.is_open()) //检测文件是否存在
{
cout << "can't open this file!" << endl;
}
fnew.count_chars = C_chars(f, fnew, wnew);
fnew.count_words = C_words(f, wnew, log); //计算单词数(插入哈希节点)
rank_word(log, wnew); //词频排名
//单词需按字典序排列才可,依次检测排序。
Assert::AreEqual(wnew.word_rank[1], string("ubuntu14"));
Assert::AreEqual(wnew.count_rank[1], 1);
Assert::AreEqual(wnew.word_rank[2], string("ubuntu16"));
Assert::AreEqual(wnew.count_rank[2], 1);
Assert::AreEqual(wnew.word_rank[3], string("windows"));
Assert::AreEqual(wnew.count_rank[3], 1);
Assert::AreEqual(wnew.word_rank[4], string("windows2000"));
Assert::AreEqual(wnew.count_rank[4], 1);
Assert::AreEqual(wnew.word_rank[5], string("windows97"));
Assert::AreEqual(wnew.count_rank[5], 1);
Assert::AreEqual(wnew.word_rank[6], string("windows98"));
Assert::AreEqual(wnew.count_rank[6], 1);
}
TEST_METHOD(TestMethod7)
{
// TODO: 在此输入测试代码
File fnew; //控制文件模块
Words wnew; //控制单词模块
Wordnode *log[HASH_LENGTH] = { NULL }; //哈希散列指针数组
strcpy_s(fnew.file_name, "F:/VS_project/WordCount/WordCount_Test/test/test7.txt"); //获取文件名
//cout << fnew.file_name << endl;
ifstream f;
f.open(fnew.file_name, ios::in); //打开文件
if (!f.is_open()) //检测文件是否存在
{
cout << "can't open this file!" << endl;
}
fnew.count_chars = C_chars(f, fnew, wnew);
fnew.count_words = C_words(f, wnew, log); //计算单词数(插入哈希节点)
rank_word(log, wnew); //词频排名
//大写“ABCD”和小写“abcd”应被当做同一词汇统计
Assert::AreEqual(wnew.word_rank[1], string("abcd"));
Assert::AreEqual(wnew.count_rank[1], 2);
}
};
}
代码覆盖率
以前就有了解VS有自带的代码覆盖率检测,这次作业实现时发现代码覆盖率结果需要VS企业版 才有提供,最后查阅了这篇博客。给VS2017装了一个小插件OpenCppCoverage才可以运行。
这里简单给出一个小教程 (查阅很多资料都没有很好的使用方法)

代码覆盖率结果如下图所示

除了图示的WordCount.cpp覆盖率不高以外,其余的代码覆盖率都十分高,总覆盖率为 91% ,仔细看函数内部结构发现,该cpp中存在多处异常检测与提示,再加上本次测试给定的参数正确,所以这也是代码覆盖率不高的原因。(测试正常输出)
计算模块部分异常处理说明
- 输入参数异常处理
- 用于处理无参数或者2个以上参数的情况。

- 文件名异常处理
- 用于处理不合规范或者不存在的输入文件名的情况

- 输出文件异常处理
- 用于处理输出文件无法创建的情况。

对应单元测试如下
TEST_METHOD(Exception_input)
{
File fnew;
int flag_input_exception = 0;
strcpy_s(fnew.file_name, "../UnitTest1/test/test11.txt");//输入文件名异常
ifstream f;
if (!f.is_open())
{
flag_input_exception = 1; //输入异常标志
}
Assert::AreEqual(flag_input_exception, 1);
}
TEST_METHOD(Exception_output)
{
File fnew;
int flag_output_exception = 0;
strcpy_s(fnew.file_name, "../UnitTest1/test/ ");//输出文件异常
ofstream fo;
fo.open(fnew.file_name , ios::out); //输出文件
if (!fo.is_open()) //输出文件合法性检查
{
flag_output_exception = 1; //输出异常标志
}
Assert::AreEqual(flag_output_exception, 1);
}

心得与收获
- 个人感觉本次作业难点并不是在编程本身,如构建之法中提到的——“软件=程序+软件工程”,本次作业也并不是单纯地跑通一个程序,更核心的思想我觉得是掌握软件工程编程的要素——比方说这次作业中的接口设计也是为了应变实践中、现实生活中多变的需求,因此也需要软件设计更具有可维护性以便后续修改。
- 关于查阅资料方面,在实现正则表达式匹配方式时,我自己也查阅了一些资料——原先在ubuntu上有试着实现正则表达式匹配,每个字符串匹配的速度都很慢,基本上都是换用boost库中正则表达式匹配来进行的,我当时总觉得标准库中的regex_search的底层实现不行,本次作业的时候因为VS2017的编译boost库的问题,只能采用标准库。
- 在查阅了一些资料和实践以后,我发现以前效率低是g++4.7版本问题, C++11相对于g++4.7还是太新了一些,不过本次在VS2017平台上测试的效果很好,换用boost库也没有必要,再加上VS2017也支持C++17,我认为在实现regex_search上效率也会更高。
以前太懒不愿意去查资料.具体信息可以看下这里。- 我花了很多的时间理解构建之法第三章第二节内容,我也仔细去思考了其中提到的关于软件工程师的几个误区。我在分析当前这个问题的时候,是否也存在着这些问题。我自己本身也存在一个习惯——思考完整个实现过程包括内部细节再开始敲代码。有时候这个习惯能让我的代码会更加具有条理,但是更多的时候却因为这个习惯浪费了大量时间。书中提到分清主次依赖的方法个人感觉十分有效,相对于这份作业来说主要的依赖问题是需求的三个功能,次要依赖问题才是文件读写、优化效率。当然,这里的次要并不是代表不重要,我们仍需多对次要问题多上一些心。
- 这里还想简单阐述一下个人的想法,更泛化来说,我所认为的主要依赖问题强调的是软件的需求,这也是最重要的,影响着一个软件的核心——功能性;次要依赖问题则更多的是注重软件的可维护性和效率。现在重新再认真翻读一遍 《构建之法》 ,也比暑假看的时候有了更多的体会,这大概就是本次作业最大的收获吧。
- 之前写第一次作业的时候有想过每天晚上就花2个小时来完成,但是做这份作业的时候,几乎整个晚上都在敲代码和调试bug当中,也可能是太久没有敲代码有些生疏吧。现在看来,每天晚上2个小时完全不够,现在决定调整到每天3小时。
给自己鼓掌下!

9.17更新
思考错因
- 在助教学姐公布的测试结果中有报错TLE,仔细思考了一下原因,因为是每个点都是TLE,所以我主要的考虑方向还是死循环这一方面是否有问题。
- 最后在跑了几次由cbattle同学提供的测试数据,发现运行时间相差不大,这里还要感谢我的一个没有参加软工实践课程的舍友,发现了输出界面的差异—— system("pause") 导致了命令行窗口没有正确停止。我认为这也就是本次TLE的原因。
改进
- 如果是要让结果正确的话,其实修改掉system("pause") 完全就足够了,但是本次还是想在原来的基础上改进。
- 因为考量到测试用例都是数据量大的文件,而原先应用的正则表达式匹配单词在处理大文件上速度明显就慢下来了,原原不如用底层直接字符判断速度快。
- 由于原先的实现方式是正则表达式匹配,所以也把整个文本读入来进行全文匹配单词,但是发现这样的方式在实现底层匹配时候不是特别方便。于是改进成vector_string 的形式来解决,具体实现方式如下流程图所示: .

- 单词匹配几个要注意到的坑点cbattle同学也和耐心地告诉我了,
感觉有点像在武林高手那边求得一本秘籍。单词匹配的流程图如下所示:

改进效果
- 以完成一次长文本的匹配为例子,下发给出时间与结果。
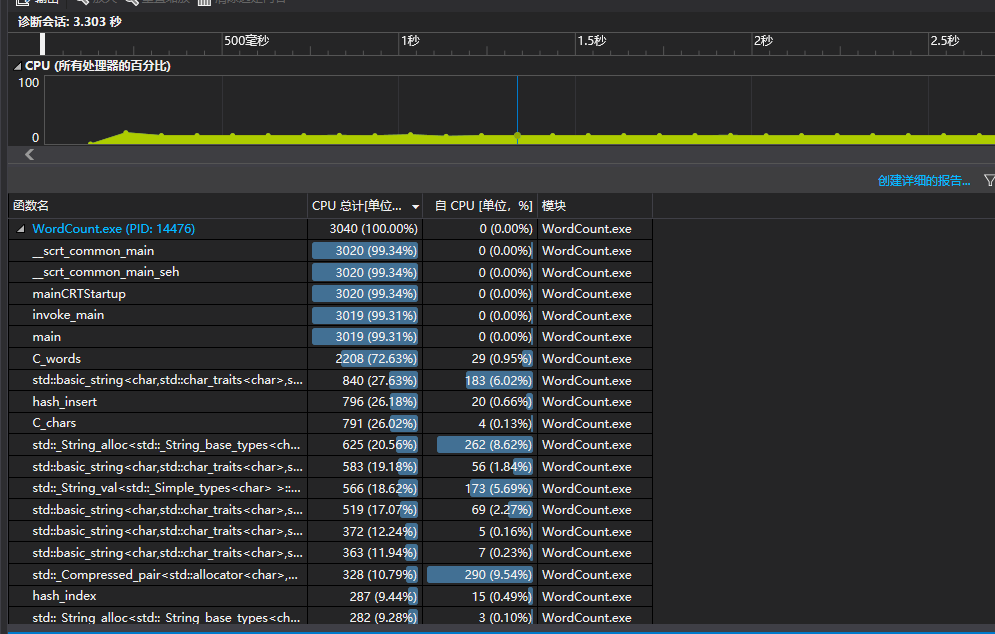
- 成功减少了在单词匹配上消耗的时间,总时间为3.303s。
小贴士
- 检测TLE的问题除了在时间限制上面,我发现还有可能是一部分同学在结尾用了类似于
system("pause")之类的导致等待时间过长。 - 我周边有部分同学有删除.vs文件后无法编译,查阅一部分资料发现具体与x64的兼容性有关,这种情况可以手动勾选x86进行编译,具体如下图所示。

参考博客
[1] https://www.cnblogs.com/SivilTaram/p/software_pretraining_cpp.html#part6.效能工具介绍
[2] http://www.ruanyifeng.com/blog/2016/01/commit_message_change_log.html


